Troubleshooting Continuous Integration, or How to Debug Tests That Fail on CI, but Pass Locally

If you’re using a Continuous Integration server, sooner or later a build will fail on the CI, but pass on your development machine. There are several ways to troubleshoot such failures - and one thing you shouldn’t do, even if it’s counterintuitive.
Let’s assume that the tests used to pass in the past, so the configuration issues (language version, package installation, memory limitations, test user permissions, etc) are out. Let’s also assume that your CI server is well configured, that you have a proper logs and a failure message allowing you to identify which test(s) fail.
Don’t Relaunch the CI Build
If the tests failed once on the CI, they will probably fail again - unless you change the code. Or, if the tests pass on the CI after a relaunch, it means there is a random factor that you haven’t identified, and this factor will cause other CI failures in the future. Lastly, if you must troubleshoot a build, it’s much easier to do locally (faster machine, less users) than on a CI server. On a development server, you can isolate the failing test, run it over and over quickly until you find the problem.
So don’t relaunch the CI build - it’s usually a waste of time. There is a good reason the tests failed on the CI, and your job as a developer is to identify the cause, and to fix it.
Don’t try to make tests pass on the CI ; try to make them fail locally.
Rebase Onto Master
You’re probably working on a feature branch. It’s possible that the master branch changed while you worked on your own code. And while you run your tests on your branch, the CI usually runs tests on master after merging your branch.
So rebase your branch on master, and relaunch the tests locally - you may reproduce the CI error locally, and therefore fix it.
Look For Platform Inconsistencies
Do you work on OS X ? Look for local changes that create / rename files. It’s possible that you use a different capitalization in the code and in the filename (e.g. require('Config.json'), while the filename is config.json). OSX filesystems are case insensitive, the CI filesystem is probably case sensitive. That would explain why the CI fails - and the solution is to fix the case inconsistency.
Do you work on Windows ? Look for inconsistent carriage returns (e.g. \r\n instead of \n). The following line should save you from such problems:
git config --global core.autocrlf inputLastly, filesystems don’t order files the same way. Some filesystems don’t even return a consistent order when you list files in a directory twice in a row. If one of your scripts depends on reading a directory, make sure you always order the results before reading them.
Run Tests Locally With The Test Configuration
You probably have a different configuration on the development environment, and on the test environment. This can be ENV vars, API endpoints, databases, browsers, etc.
To reproduce a CI build locally, one of the first things to do is to use exactly the same setup as the CI. If your build automation is good, it should be as easy as running:
ENV=test make testYes, it’s a good idea to use makefiles for that. We use them a lot.
On the CI platform, end-to-end (e2e) tests usually run on a headless browser, or on Chrome / Chromium. If you run e2e tests locally on a different browser, try using the same one as in the CI.
Reinstall Dependencies
The CI server usually reinstalls the entire project, and its dependencies. If your dependency management system doesn’t lock dependency versions (e.g. with a composer.lock or a yarn.lock), it’s possible that the CI installed an updated dependency, which breaks the build. The problem doesn’t happen locally because you didn’t update dependencies.
So don’t be afraid and run:
rm -Rf node_modules && npm install… or the equivalent for your platform.
Oh, and don’t forget to empty the package manager local cache if it has one:
npm cache cleanSlow Down Your Development Machine
Some random CI failures come from race conditions, that you never experience locally because your development worskation is too fast.
A good way to reproduce these failures locally is to slow down responses from services. For instance, here is how you can add a random delay to your API requests using an Express middleware:
app.use(function (req, res, next) { setTimeout(() => next(), Math.round(Math.random() * 1000));});Some testing utilities can also manually throttle a given function, to simulate a slow network / response time. Here is how to throttle a function with sinon.js:
var clock;
before(function () { clock = sinon.useFakeTimers(); });after(function () { clock.restore(); });
it('calls callback after 100ms', function () { var callback = sinon.spy(); var throttled = throttle(callback);
throttled();
clock.tick(99); assert(callback.notCalled);
clock.tick(1); assert(callback.calledOnce);
// Also: // assert.equals(new Date().getTime(), 100);}Alternately, run your build on a VM, or on a container with limited CPU or memory, to reproduce the conditions of the CI server. Some Continuous Integrations platforms even allow you to download the build system. For instance, Travis CI lets you run the build in a local Docker image. Or you can use a tool like vadimdemedes/trevor to ease that process.
Mock Time
If some tests fail at specific dates (e.g. first of the month, February 28th, midnight), then your code must be fixed. Add a new test which mocks the time to the failing case, and fix the related code.
Once again, this is simple to achieve using sinon.js:
it('works on year 2000', function () { const now = new Date('01/01/2000 00:00'); clock = sinon.useFakeTimers(now); // do your test clock.restore();}In addition to time problems, you might have Timezone problems. If the development server is in Europe, and the CI server is in the US, then they don’t have the same timezones. This can lead to unexpected failures. If your app should only work on a specified timezone, force this timezone on the CI server. For instance, on Travis CI:
before_install: - export TZ=Australia/CanberraBut usually, the requirement is that the app should work in all timezones. In that case, change the timezone of your local server to the one of the CI to reproduce the test failure, and fix the code.
Seed Random Generators
Random test failures can also happen if you use a random number generator somewhere in your code, which sometimes triggers a limit case. In that case, you should use the same random seed on the development and test environments, to be sure you can reproduce failures locally (and fix the code).
In other terms: never use a random number generator that you haven’t seeded. For JavaScript, that means never use Math.random(), because it can’t be seeded. Use a Mersenne Twister library instead (like chance.js).
Isolate The Local Build
Some processes in your local machine can make the CI build pass locally, but fail on the CI because they don’t run. For instance, I remember a developer wondering why his end-to-end tests timed out on Travis but passed locally. It’s simply because he was testing a Single-Page Application with a local HTTP API, but forgot to start the API in the CI build.
To identify such side effects, kill all running processes - or better, run your tests in isolation, for instance in a Docker image.
Another related cause of test passing locally is a non-empty database. Your CI uses a new environment every time, with an empty database. Fix your test setup so that it uses an empty database locally, too.
Mock External Resources
Some tests may fail randomly because the tested system depends on an external resource (e.g. an HTTP endpoint). This resource may be not accessible (or slower) from the CI than from your system.
The best option to circumvent these kind of problems is to avoid dependency on external resources altogether in the CI build. Use mocks, fakes, and stubs to simulate an external resource.
There are many libraries for that in every language ; let me recommend one that you may not have heard of. It’s called FakeRest, and it mocks a REST server directly in the browser, by monkey patching the XHR/fetch objects. Ideal to mock a server without an actual server.
Or, you can change the CI configuration to replace the actual URLs of external HTTP endpoints by an URL served by your own development machine. That way, you can see the calls that are made, and find the problem faster. Use ngrok for that.
Slow Down Your Browser
End-to-end (e2e) tests are the most common culprits for random CI failures. These tests take control of a real browser (like Chrome), and repeat a predefined set of actions (navigation, click, form submission, etc).
Failing e2e tests usually come from two chained actions without a proper delay in between. For instance, I remember a scenario where I programed a click on a select box, then clicked on the second option in the dropdown. The tests failed on the CI because the dropdown was not yet revealed when the test automator attempted to click on the option. They passed locally because my development machine is much faster than the CI.
To reproduce the failure locally, I had to slow down my browser. Chrome allows to throttle the network and the CPU in the developer tools. Just hit the “Timeline” tab, and the settings icon:
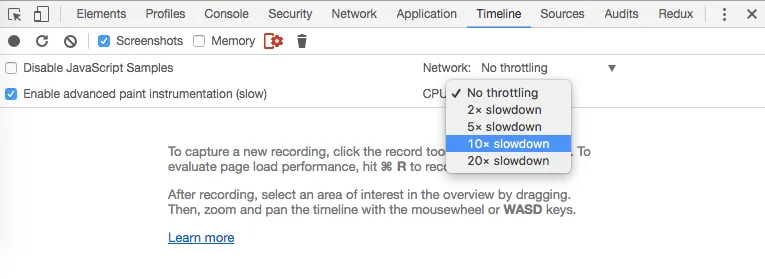
When you can reproduce such failures, you realize that the CI is right: you must add a delay in e2e scenarios to let the previous action finish before starting a new one. This is the hardest part in e2e testing, but it’s easier than you think.
Run All Tests
Did you limit your test run to a single test case (e.g. using .only()), see that it passes, remove the limit, then commit? Then your test may work in isolation, but not when launched with the entire suite, due to side efects you didn’t yet detect.
Run the entire test suite locally to localize such problems.
This may reveal tests that don’t clean up the environment properly (leaving test fixtures in the database, mocks or spies, etc).
Restart From Scratch
If you still can’t reproduce the CI failure after all that, try erasing your local copy of the application, and check it out from the source repository. Then relaunch the entire install / build process to get a fresh environment - exactly like the one you should get on a CI server.
It seldom works.
Debug On the CI Server
If all the above fail, then the problem may lie in the Continuous Integration server. Let’s be clear: it’s rare. Most of the CI failures come from the test setup, or the application code.
But to troubleshoot CI failures, at last resort, log in to the CI server (most of them offer an SSH endpoint), run the tests in debug mode, add breakpoints, add logs, and find the reason why it fails.
For instance, the Travis CI offers a “Debug Build” button on failed build, which starts a Travis machine, sets environment variables, and pulls the code from source. It then gives you an SSH endpoint to log in to, so you can run the tests yourself.
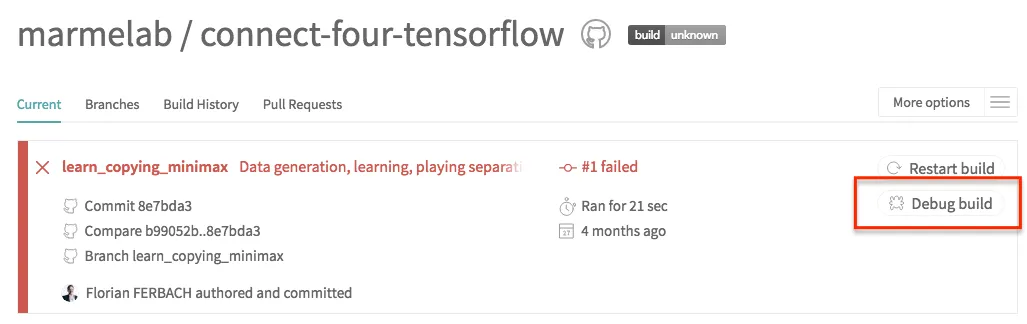
Note that this Travis option is only available on paid plans.
Conclusion
The hardest part of troubleshooting a CI failure is to reproduce the failure locally. Once it’s done, use the usual debugging techniques to locate and fix the bug.
See a failed CI builds as an opportunity to detect and fix an edge case, to make your build process more robust, and to make your development environment more similar to the production environment.
Finally, don’t blame the CI - it’s here to help!
Authors
Marmelab founder and CEO, passionate about web technologies, agile, sustainability, leadership, and open-source. Lead developer of react-admin, founder of GreenFrame.io, and regular speaker at tech conferences.