
Onboarding chez Marmelab : 5 semaines pour faire un jeu - Semaine 1

Mes 5 premières semaines chez Marmelab m’ont donné l’occasion d’apprendre beaucoup en un temps restreint. À chaque sprint, j’ai dû réaliser un jeu dans un paradigme différent :
- Un CLI en python,
- Une API en symfony,
- Une Intelligence Artificielle en Go,
- Une application mobile en react-native,
- Une application web isomorphic avec Nextjs.
À chacun de ces sprints j’ai rencontré des difficultés et eu quelques victoires, mais j’ai surtout énormément appris. Je vous présente ici ce que je retiens de la première semaine, d’autres articles viendront compléter celui-ci.
Tipsy: Un jeu renversant
Avant tout, je vous présente Tipsy, le jeu sur lequel j’ai travaillé. Le principe est relativement simple, chacun des 2 joueurs possède 6 jetons, des bleus pour l’un, et des rouges pour l’autre. Ils sont disposés sur un plateau de 7 cases sur 7 cases, et un jeton noir est disposé au milieu du plateau. Le plateau est entouré de rebords empêchant les jetons de tomber, d’obstacles fixes, et de 4 sorties par lesquelles les jetons pourront sortir.
Le but du jeu est double :
- Retourner les 6 jetons de sa couleur en les faisant sortir du plateau et les replaçant retourné sur une place disponible.
- Ou faire sortir le jeton noir
La particularité de ce jeu se trouve dans la manière de déplacer les jetons, il faut pour cela basculer le plateau de manière à faire glisser les jetons dans la direction souhaitée.
Tipsy CLI : Une première version du jeu en Python
Après avoir perdu (de peu) une première partie de Tipsy, je pars démarrer le sprint en épluchant le backlog qui a été préparé pour l’occasion.
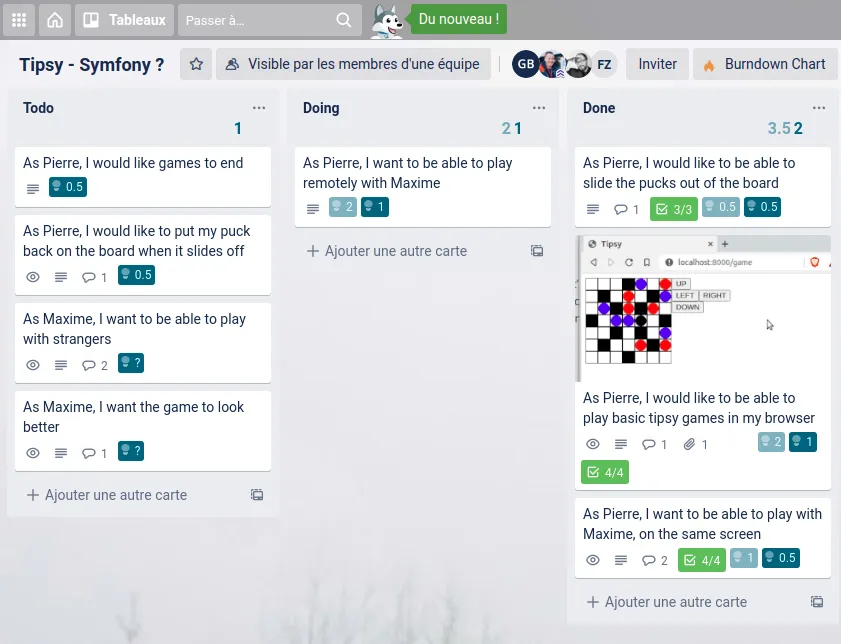
Je découvre un backlog bien construit, les stories y sont plutôt bien détaillées et il n’y a presque pas besoin de précisions. Chaque carte exprime sans ambiguïtés un besoin utilisateur avec à chaque fois, une problématique et une solution.

Je propose des estimations en échangeant avec Florian (qui jouera le rôle du product owner) et Julien (qui me coachera sur cette semaine) et le sprint démarre.
Ha… j’oubliais… Le langage est imposé, ça sera du Python. Moi qui n’ai plus fait de python depuis mes études, je me dis que c’est l’occasion de m’y remettre un peu.
C’est graphe docteur? : Bien choisir sa modélisation
Première étape : modéliser le jeu. En effet, une des difficultés, dans tout développement, est de trouver le bon modèle pour représenter le domaine en question. De prime abord, je décide de représenter mon plateau sous forme de tableau à 2 dimensions. Mais assez rapidement il m’est suggéré de le représenter sous forme de graphe.
L’idée est de représenter chaque case par un nœud du graphe avec comme clef sa position. Un obstacle équivaut à une absence de nœud et les nœuds sont reliés par des liens portant comme attribut la direction de ce lien : nord, sud, est, ouest. Si un pion se situe sur un des nœuds, alors ses propriétés seront portées par les attributs du nœud : couleur, retourné ou non.
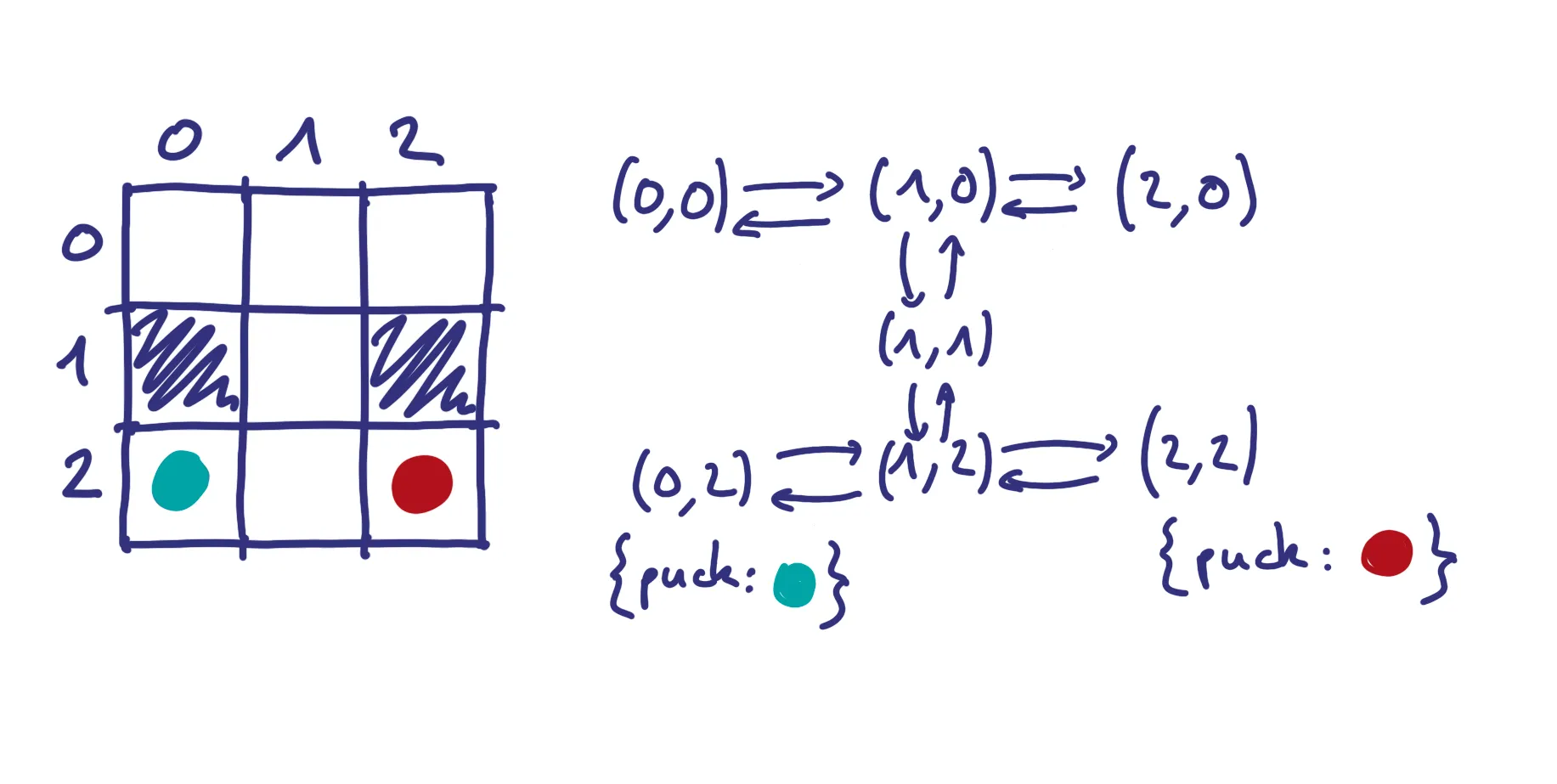
Ce modèle me facilitera la tâche sur différentes opérations, comme trouver les cases libres pour replacer un jeton ou chercher la prochaine case libre pour un jeton lors d’un “tilt” dans une direction.
Démarrons, mais démarrons bien ! Le marmelab starter kit
Une fois le modèle de données choisi, il est temps de se mettre à la tâche. Initialiser le dépôt github, pousser son code, et c’est parti… wait… vraiment ?
Une des choses que j’ai découvertes, parmi les pratiques de Marmelab, est le fait de penser son projet tel que quelqu’un qui ne le connait pas, puisse le reprendre le plus facilement possible. C’est pour cette raison que vous pourrez en 2 commandes installer et lancer ce projet. Explications…
Dans chaque projet marmelab vous trouverez un Makefile, qui comprend principalement 2 goals : install, et start. Ces goals parlent d’eux même, ils servent à installer toutes les dépendances nécessaires à faire tourner le projet, et à le démarrer. En plus de cela, une utilisation judicieuse de Docker (qu’on ne présente plus) permet aux prochains développeurs arrivant sur le projet de ne dépendre que d’une chose pour pouvoir démarrer le projet : Docker.
Par exemple sur tipsy-python, nous trouverons le Makefile suivant :
DOCKER := docker run -it --rm tipsy-python
install: ## Build the docker container docker build -t tipsy-python .
run: ## Run the game. $(DOCKER) python3 ./tipsy.py
test: ## Run the tests $(DOCKER) python3 -m unittest -v
local-test: ## Run the tests on local machine python3 -m unittest discover -s ./src -v
local-run: python3 ./src/tipsy.pyEt le Dockerfile correspondant :
FROM python:3
WORKDIR /usr/src/app
COPY ./src/ ./
RUN pip install -r requirements.txtEn faisant un make install l’image docker va être construite en installant les dépendances de notre projet. Et en faisant un make run le projet se lance.
Il s’agissait de ma première version de Makefile et Dockerfile, il y a moyen d’avoir une configuration beaucoup plus maline. Nous voyons notamment que j’ai créé 2 goals, “local-run” et “local-test”, qui n’utilisent pas du tout l’image Docker. Cela m’oblige à reconstruire l’image docker à chaque mise à jour de mon code… Il aurait été plus malin d’utiliser les volumes de Docker pour monter les sources dans le container. C’est ce que j’ai fait sur les sprints suivants.
version: "3.3"
services: symfony: build: docker/symfony volumes: # Nous montons les sources ('.') dans le dossier /app du container - .:/app ports: - 8080:8080 command: "/usr/local/bin/symfony server:start --port 8080"install: docker-compose build docker-compose run --rm symfony bash -ci 'composer install' docker-compose run --rm symfony bash -ci 'composer update' docker-compose run --rm symfony bash -ci 'symfony console doctrine:schema:update --force'
run: docker-compose up --force-recreate -d
test: docker-compose run --rm symfony bash -ci './bin/phpunit'De cette manière, je suis toujours à jour et je ne suis plus obligé de construire l’image à chaque modification du code. Sur cette base (Docker, docker-compose, Makefile), nous pouvons configurer n’importe quel projet sur n’importe quelle techno.
Des tests visuels : pour mieux comprendre
Le projet est initialisé, le Makefile et le Dockerfile sont prêts, je peux commencer à coder. Je décide de regarder ce qu’il existe comme solution en Python pour représenter un graphe. Assez rapidement je tombe sur la librairie Networkx qui propose une api de création et de manipulation de graphe.
Armé de mon modèle de données et d’une librairie me facilitant le travail, je me lance. Python est, à mon sens, un langage très intuitif, son côté concis et typé en font un langage facile à prendre en main. Je n’éprouve à ce moment pas de difficultés à écrire mes premières lignes de code. Mais assez rapidement je tombe sur mes premiers bugs : mon pion ne se retrouve pas à l’endroit que je souhaite lorsque je bascule le plateau ou disparaît de mon plateau… Afin de ne pas rester bloqué trop longtemps, et d’identifier rapidement le problème, je décide d’écrire des tests.
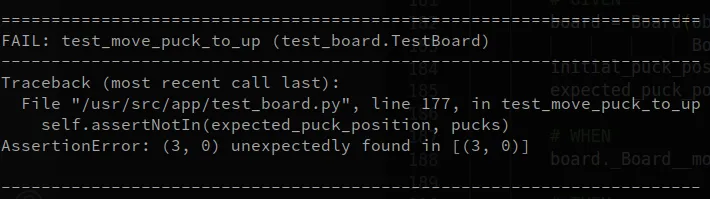
def test_move_puck_to_up(self): # GIVEN board = Board(obstacles=[], exits=[], pucks={ Board.BLUE: [(3, 3)], Board.RED: []}) initial_puck_position = (3, 3) expected_puck_position = (3, 0)
# WHEN board._Board__move_puck_to(initial_puck_position, Board.NORTH)
# THEN pucks = [node for node, attributes in board.graphe.nodes( data=True) if attributes.get(Board.PUCK_KEY)] self.assertIn(expected_puck_position, pucks) self.assertNotIn(initial_puck_position, pucks)Mon test est écrit, et s’exécute bien. J’en écris d’autres qui me permettent d’avancer, de repérer et de corriger différents petits bugs. Mais cela ne me suffit pas… En effet, parmi mes tests, certains se concentrent sur l’état du plateau après tel ou tel mouvement. Il est difficile de comprendre ce qu’il se passe lorsqu’un test échoue sans visualiser le plateau lui-même et la position des pions.
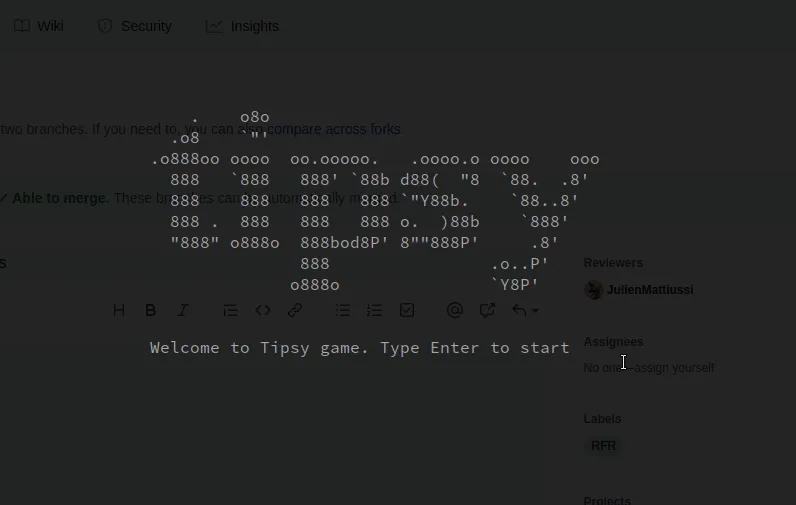
Pour me faciliter la tâche et m’aider dans la compréhension de l’exécution de mes tests, je décide de développer une petite méthode utilitaire pour afficher un plateau, ainsi que ses jetons, dans une console. Cela me servira par ailleurs à afficher mon jeu dans le CLI.
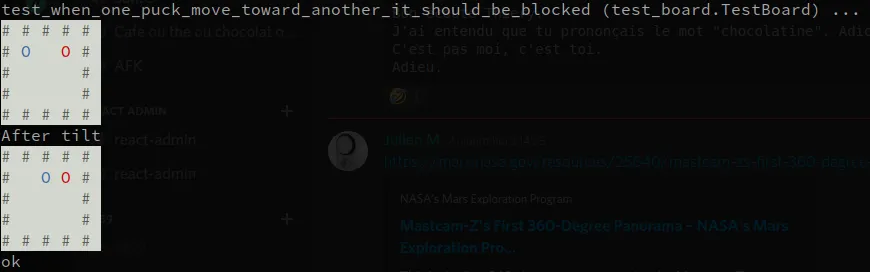
Je reprendrai ce principe sur certains des sprints suivant, tant il est pratique de pouvoir, en un coup d’œil, comprendre ce qu’il s’est passé.
Les code reviews ça prend trop de temps ! (c’est faux!)

Dans mes expériences passées j’ai eu à cœur de mettre en place des revues de code systématiques, et j’ai quelques fois dû me confronter à un argument souvent avancé : “On n’a pas le temps de faire des revues de code…”.
Bien sûr, dans ce contexte d’intégration l’enjeu n’est pas le même que sur un projet dont dépend un client, mais la problématique du temps était bien présente à la vue des backlog bien chargés qui m’étaient présentés à chaque sprint.
Je me suis donc plié à ces pratiques bien intégrées à Marmelab, les Pull Request (PR) et les revues de code. Toutes mes modifications ont été revues par au moins une personne, débouchant bien souvent sur des échanges et des ajustements du code. A chaque fois, j’apprenais ou je partageais une nouvelle connaissance. La revue de code a un intérêt à la fois pour le relu ET pour le relecteur.

Une story = Une PR ? Spoiler : non
Un travers dans lequel je suis néanmoins tombé est de vouloir trop faire coller mes PR aux stories définies dans le backlog. Il arrive, souvent même, qu’une story nécessite un ensemble de tâches techniques, qui individuellement sont l’histoire d’1h ou moins, mais qui mises ensemble s’étalent facilement sur une journée… Et cela pose problème lorsque l’on part du principe, comme moi, 1 PR = 1 story…

Par ce raisonnement, je me suis retrouvé quelques fois dans des petits effets tunnels, ne délivrant une PR qu’au bout d’une journée ou plus, bien souvent en tout début de sprint.
Cela pose plusieurs problèmes, d’abord, le fait de ne rien pouvoir montrer au Product Owner, qui ne peut alors que croire votre parole et ne peut pas faire de retours sur ce que vous avez fait. Par le même effet, la revue de code pourra lever des problèmes de conception ou de bonnes pratiques qui auraient pu être levés beaucoup plus tôt, et qui auraient été beaucoup plus facile à rectifier.
Je retiens de cela qu’une fréquence minimale de 2 à 3 PR par jour est un bon rythme, forçant par ailleurs à limiter la taille de celles-ci.
Feedback - Montrer plutôt que décrire
En complément de PRs régulières, un autre outil que l’on a tous à portée de main est tout simplement de montrer ce que l’on a fait. Faire une PR sans image ou animation montrant de quoi il s’agit sera toujours moins pertinent.
Montrer ce que l’on a fait permet de mettre une fonctionnalité sur un bout de code, le relecteur saura tout de suite de quoi il s’agit.
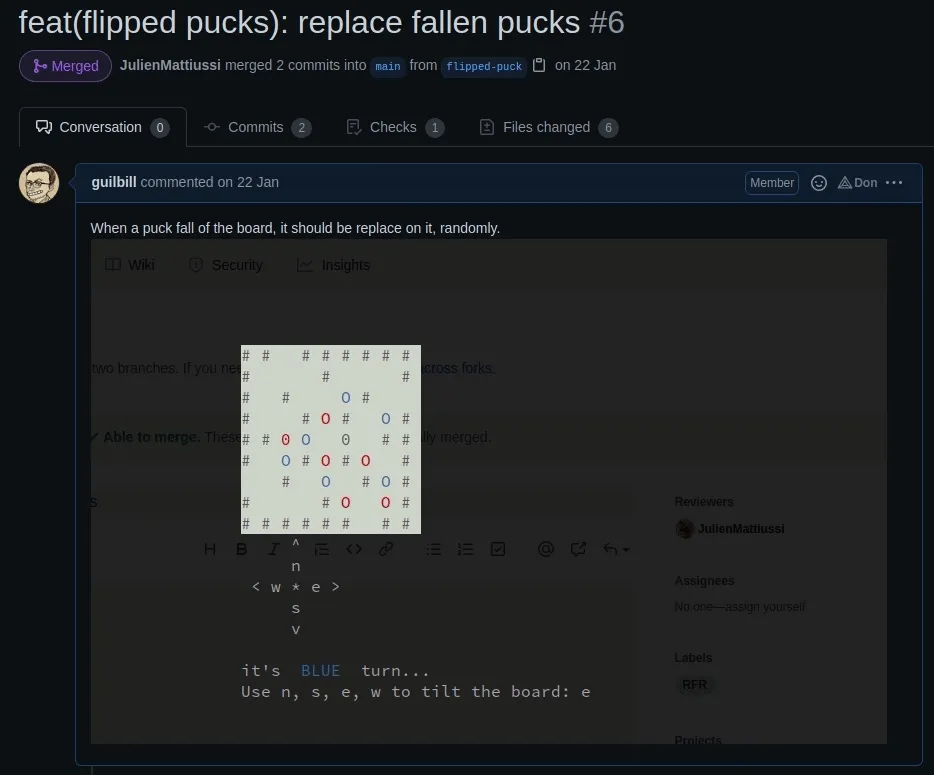
Cela permet également de recueillir très rapidement des retours utilisateurs. Le relecteur est en quelque sorte un de vos premiers utilisateurs et pourra déjà vous faire des remarques pertinentes.
La démo - Faire les bons compromis
À chaque fin de semaine, je devais faire une démonstration. Dans un temps relativement court (35-40 min), je devais montrer le résultat du travail de la semaine et et en faire une rétrospective en me concentrant sur ce que j’ai appris, les difficultés ressenties et la façon dont je les ai surmontées.
Dans le temps très condensé des sprints, il peut être tentant de délaisser la préparation de cette démo au profit du développement des dernières features. C’est une erreur classique qui a deux gros inconvénients : une démonstration non maîtrisée et des développements de dernières minutes menant bien souvent droit vers “l’effet démo”.

J’ai été tenté par ce biais… Le dernier jour du sprint, le jour de la démo donc, un bug plutôt critique, m’a été remonté : en faisant une certaine combinaison de mouvement le jeu plantait complètement, empêchant de terminer la partie et par la même occasion mon coach de valider ma dernière PR, qui apportait pourtant quelques effets “Waouh”.
Il m’a été difficile de m’asseoir sur le fait d’avoir ces dernières modifications pour ma démo. Face à cette situation, la solution que je trouve la plus adaptée est de se “time boxer”, se donnant ainsi une chance de résoudre le problème en un temps donné et, passé ce temps, de se concentrer sur ce qui fonctionne déjà.

Concrètement, je me suis mis une limite en fin de matinée pour me laisser au moins 2 h pour préparer ma démonstration. Passé cette limite et faute d’avoir trouvé l’origine du bug, j’ai dû abandonner l’idée de montrer mes derniers développements, avec un chagrin infini… Mais!!! Passé cette tristesse, j’ai pu préparer ma démo sereinement, avec la tranquillité d’esprit de celui qui sait que son programme tourne, est testé et éprouvé. Confort Ô combien appréciable en situation de pression.
Conclusion
La période d’intégration de Marmelab n’est pas banale, elle est exigeante et éprouvante sur la durée, demandant un investissement fort dès le démarrage. En contrepartie, elle offre une formation accélérée que seul ce format permet.
Passer par un projet concret, permet de se frotter à des difficultés réelles beaucoup plus formatrices qu’une revue théorique d’un cours en ligne par exemple.
La contrainte de temps et les backlogs (sur)chargés permettent également d’éprouver notre capacité à gérer une certaine pression, et à savoir prioriser de manière pragmatique (quick win…).
Cet exercice, auquel on accepte de se plier en rejoignant Marmelab, est néanmoins accompagné de manière très bienveillante par les coachs et les product owners.
Pour conclure, cette expérience m’a permis d’en apprendre beaucoup d’un point de vue technique et méthodologique, mais également, d’un point de vue personnel, sur moi-même et ma manière de gérer une pression ou de réagir à un échec. L’important lorsque l’on tombe n’est pas la chute, mais la manière dont on va se relever.
Vous pouvez retrouver le code de ce projet sur github.
Authors
Full-stack web developer at marmelab, Guillaume can turn complex business logic into an elegant and maintainable program. He brews his own beer, too.