
Bull: Traitements asynchrones en Node.js


Nous avons mis en place un système de workers en tâche de fond sur une application web pour l’INIST-CNRS. Cela nous a donné l’occasion d’utiliser Bull, une librairie de gestion de queue basée sur Redis. Voici ce que nous avons appris au passage.
Contexte: Le web sémantique, c’est fantastique
Marmelab collabore au Linked Open Data Experiment (LODEX), un projet open source porté par l’INIST. Cet institut du CNRS a pour mission l’accés, l’analyse, la fouille et la valorisation de l’information scientifique (publications et données de recherche).

Le projet LODEX valorise des jeux de donnés produits par des chercheurs et des documentalistes en “facilitant la curation et la sémantisation de données brutes pour les connecter au web de données via les normes et les standards du web sémantique”. En termes profanes, il s’agit, à partir d’un jeu de données scientifiques (json, xml, csv, …), de le nettoyer, l’enrichir et d’en générer un site web permettant de l’explorer soit manuellement (via des pages web), soit automatiquement (via le web sémantique).
Marmelab à l’INIST - Les enrichissements c’est reversant
L’une de nos missions consiste à développer une fonctionnalité d’enrichissement de données. Concrètement, l’idée est de permettre aux utilisateurs de compléter les données avec des informations provenant de sources externes via des web services. Ces informations peuvent aller de la langue détectée sur la base d’un texte, à la déduction de l’éditeur sur la base d’un DOI (identifiant unique des articles scientifiques).
Par exemple, un chercheur dispose d’un corpus contenant des résumés de texte. Il souhaite enrichir ce corpus avec les langues utilisées par ces résumés.
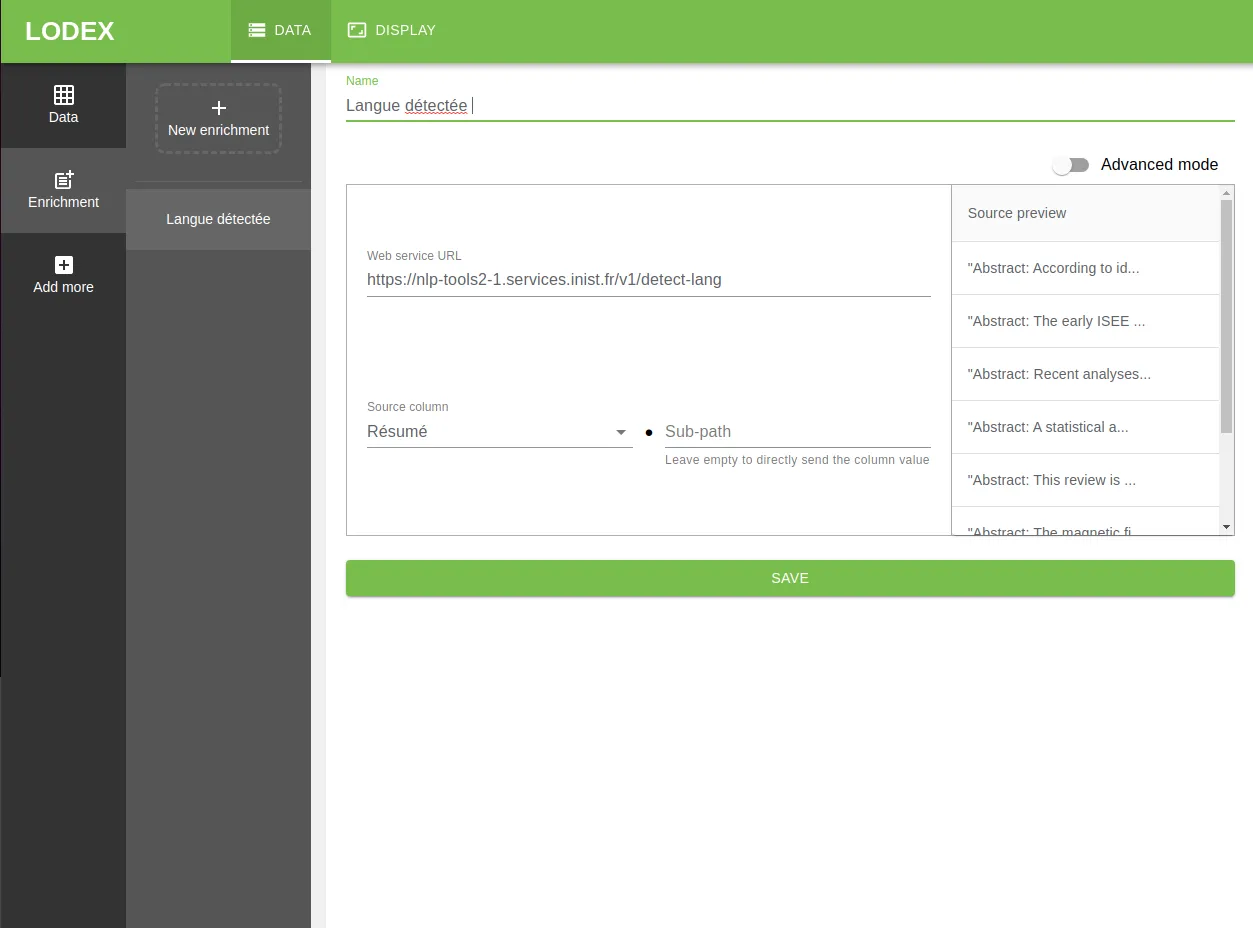
Il envoie donc tous les “résumés” à un webservice et celui-ci renvoie un résultat pour chaque ligne. Ce résultat devient une nouvelle colonne et se retrouve publié avec les autres caractéristiques. Ce qui nous donne :
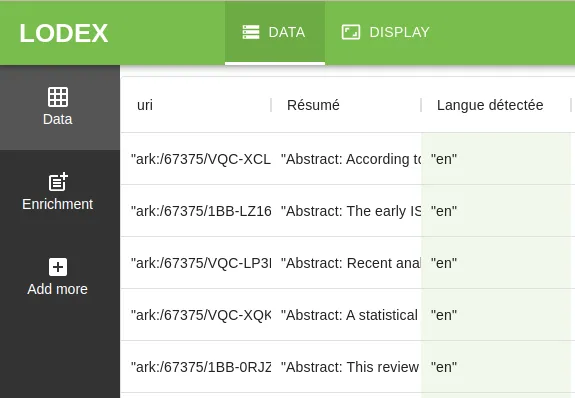
Cependant, les jeux de données peuvent être très conséquents, et les enrichir peut être très long (plusieurs heures). Pas question dans ces conditions de bloquer l’interface de l’application lors d’un enrichissement.
La solution que nous avons choisie est de traiter les demandes d’enrichissement en tâche de fond, et d’indiquer la progression de l’enrichissement dans l’interface.
Bull: La solution aux traitements long
Pour réaliser nos traitements en tâches de fond, nous avons utilisé Bull. C’est une librairie Node qui implémente un principe de file d’attente basé sur Redis. Redis fournit en effet la possibilité de gérer des files d’attente, Bull nous met à disposition une API permettant d’exploiter cela plus facilement.
Le fonctionnement est très simple :
- On définit une file d’attente (queue)
- On définit une tâche (job)
- On ajoute la tâche à la file d’attente.
- On définit une nouvelle tâche qu’on ajoute à la file d’attente, ainsi de suite.
Mise en place de la première file d’attente
L’un des avantages de Bull est sa simplicité d’utilisation. Après avoir ajouté bull dans nos dépendances, l’url d’une base Redis suffit pour obtenir une Queue :
import Queue from "bull";
const workerQueue = new Queue("Worker", "redis://127.0.0.1:6379");Afin de garder une configuration et une installation simplifiée de l’application, nous décidons que Redis sera inclus dans l’image Docker du projet.
FROM node:12-alpine AS releaseRUN apk add --no-cache su-exec redis[...]ENTRYPOINT [ "/app/docker-entrypoint.sh" ]CMD [ "npm", "start" ]Dans /app/docker-entrypoint.sh nous ajoutons la commande permettant de démarrer Redis en arrière-plan :
#!/bin/shredis-server &chown -R daemon:daemon /app /tmpexec su-exec daemon:daemon $*Premier exemple
Voici comment nous avons utilisé Bull pour enrichir les données: une fois la file d’attente créée, nous lui indiquons ce qu’elle va devoir faire lorsqu’elle reçoit quelque chose. Pour cela nous utilisons la méthode process :
const processEnrichment = (job, done) => { console.log(`Processing job ${job.id}, with data ${job.data}`); // code du worker // ... done();};// ajouter un process à la queuewokerQueue.process(processEnrichment);Et là où nous avons besoin d’enrichir une donnée, nous ajoutons un message dans la file avec worker.add():
// déclenche le process avec job = { data: ... }workerQueue.add({ data: ... });Second exemple
Un autre objectif de cette mission est d’améliorer l’expérience utilisateur. À cet égard, il nous semble pertinent de mettre en place les tâches de fond également sur la publication (l’étape qui génère le site web).
Par défaut la première tâche dans la file d’attente est la première à être traitée. Les autres seront traitées dans l’ordre d’ajout. On appelle ça le “FIFO” (first in first out), c’est le mode par défaut.
Dans notre cas, il peut y avoir plusieurs publications en attente, chaque changement ou modification réalisé par un administrateur générant une publication. Nous souhaitons ne prendre en compte que la dernière. FIFO n’était donc plus pertinent. Nous avons utilisé une alternative : le “LIFO” (last in first out).
Pour éviter de traiter les autres publications en attente (workerQueue.getWaiting()), nous les supprimons (job.remove()) avant de traiter le job courant :
const publisherQueue = new Queue( 'Worker', 'redis://127.0.0.1:6379', defaultJobOptions: { lifo: true, },});publisherQueue.process((job, done) => { // job est le dernier job reçu par la file d'attente (LIFO) publisherQueue.getWaiting().then(waitingJobs => { waitingJobs.forEach(waitingJob => waitingJobs.remove()); }); processPublication(job, done);});Faire cohabiter deux queues
Nous souhaitons donc utiliser le mécanisme qui permet de traiter des tâches de fond à la fois pour l’enrichissement de données et pour la bublication. Avec deux Queue, nous aboutissons à quelque chose comme cela :
const publisherQueue = new Queue("Publisher", "redis://127.0.0.1:6379");const enricherQueue = new Queue("Enricher", "redis://127.0.0.1:6379");
publisherQueue.process((job, done) => { processPublication(job, done);});
enricherQueue.process((job, done) => { processEnrichment(job, done);});Et le tour est joué, mais… Nous avons besoin de traiter les publications et les enrichissements de manière séquentielle. Nous avons cherché une solution à notre souci en utilisant 2 files comme nous le faisons ici, sans trouver. La seule option que nous avons trouvée est de n’utiliser qu’une seule file, et d’ajouter une notion de type à nos jobs pour pouvoir différencier leur traitement :
export const workerQueue = new Queue("Worker", process.env.REDIS_URL);
// la première option permet de définir la concurrence, ici, nous ne voulons pas de concurrence, nous mettons 1.workerQueue.process(1, (job, done) => { if (job.data.jobType === PUBLISHER) { processPublication(job, done); } if (job.data.jobType === ENRICHER) { processEnrichment(job, done); }});Abort! Abort! Comment annuler une tache en cours ?
Nous avons notre file d’attente, qui traite les publications et les enrichissements de manière séquentielle. Mais comme nous le disions, un enrichissement peut être très long, et si l’utilisateur se rend compte qu’il a fait une erreur à la configuration de son enrichissement, il n’est pas envisageable qu’il attende la fin du traitement pour pouvoir le corriger. Nous devons pouvoir annuler la tâche en cours.
Bull nous permet d’annuler le job en cours :
const getActiveJob = async () => { const activeJobs = await workerQueue.getActive(); // Nous ne traitons qu'un job à la fois return activeJobs?.[0];};
const cancelJob = async (ctx) => { const activeJob = await getActiveJob(); activeJob.moveToFailed(new Error("cancelled"), true);};Mais Bull n’est pas responsable du processus lancé par le job (via la méthode process).
Il faut donc créer une vérification dans notre tâche de fond. Pour cela, nous avons utilisé la méthode isActive, qui retourne true si le job est en cours, false sinon :
worker.process((job, done) => { aVeryLongProcess(job, done);});
const aVeryLongProcess = async (job, done) => { let isActive = await job.isActive(); for (const line of job.data.aLotOfLines) { // if job is no longer active, we stop processing. if (!isActive) { return; } await aVeryLongProcess(data); isActive = await job.isActive(); }};La manière d’utiliser Bull restera la même quels que soient vos projets. C’est un outil puissant qui en plus des cas montrés ci-dessus, vous permet aussi de donner des priorités à vos taches, de les organiser, ou de dire si certaines taches sont séquentielles ou parallèles.
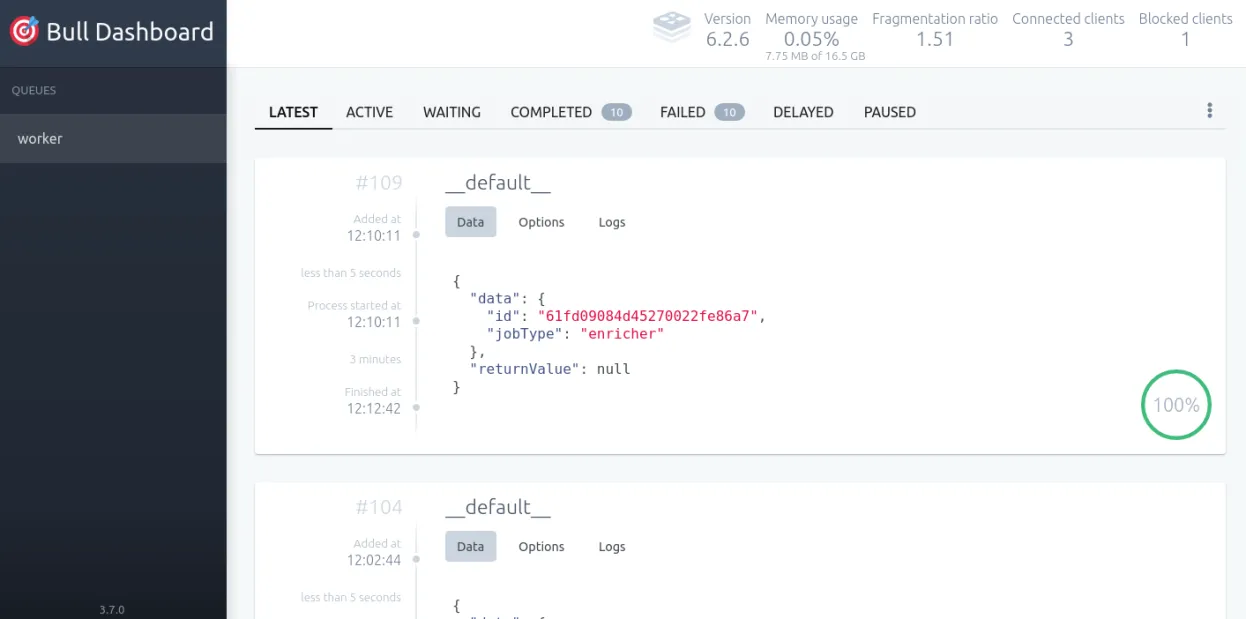
Un dashboard et des logs
Le développement avec un gestionnaire de queue peut être quelquefois compliqué à débugger et à analyser, du fait du côté asynchrone du traitement. Pour nous aider sur cet aspect, nous choisissons d’utiliser la librairie @bull-board, qui permet de générer un dashboard.
Sur ce projet, nous utilisons koa, nous montrons ici comment nous avons mis en place @bull-board avec koa.
Nous avons créé un middleware à l’aide du KoaAdapter fournit par @bull-board, et l’avons enregistré dans notre app koa :
import Koa from "koa";import { KoaAdapter } from "@bull-board/koa";import { createBullBoard } from "@bull-board/api";import { BullAdapter } from "@bull-board/api/bullAdapter";
const app = new Koa();
const serverAdapter = new KoaAdapter();
serverAdapter.setBasePath("/bull");
createBullBoard({ queues: [new BullAdapter(workerQueue)], serverAdapter,});app.use(serverAdapter.registerPlugin());Note : @bull-board fournit d’autres adaptateurs pour les frameworks différents.
Conclusion
Implémenter un système de file d’attente a amélioré notre projet. La gestion des tâches longues n’était pas ergonomique, il fallait attendre la fin de chaque tache pour pouvoir en lancer une nouvelle. Depuis l’ajout de Bull, les utilisateurs de LODEX peuvent lancer des tâches les unes à la suite. La librairie est complète, rapide et adaptée à la production.
Authors
Full-stack web developer at marmelab, Guillaume can turn complex business logic into an elegant and maintainable program. He brews his own beer, too.
Full-stack web developer at marmelab, Anthony seeks to improve and learn every day. He likes basketball, motorsports and is a big Harry Potter fan