
EdgeDB, A New Competitor In The Database Area

EdgeDB is a new database that classifies itself as a Graph-Relation database. It is different from standard SQL and requires a specific query language, EdgeQL, to be used. EdgeQL looks like this:
SELECT User { email password: { hash }}FILTER .email = "my@email.com";EdgeDB also provides tools such as migrations and clients for different languages.
Let’s dig into how to use EdgeDB, the difference with other databases like PostgreSQL, performance considerations, and some caveats.
Creating a Simple Database
The recommended way to create a database is by using the EdgeDB CLI. It will generate files describing your database, that you can commit to your Git repository - it’s a “database-as-code”.
❯ edgedb project init No `edgedb.toml` found in `/home/guillaume/dev/examples`or above Do you want to initialize a new project? [Y/n] > Y Specify the name ofEdgeDB instance to use with this project [default: examples]: > examplesChecking EdgeDB versions... Specify the version of EdgeDB to use with thisproject [default: 2.5]: > 2.5┌─────────────────────┬──────────────────────────────────────────┐ │ Projectdirectory │ /home/guillaume/dev/examples │ │ Project config │/home/guillaume/dev/examples/edgedb.toml │ │ Schema dir (empty) │/home/guillaume/dev/examples/dbschema │ │ Installation method │ portable package│ │ Version │ 2.5+57f7823 │ │ Instance name │ examples │└─────────────────────┴──────────────────────────────────────────┘ Version2.5+57f7823 is already installed Initializing EdgeDB instance... [systemctl]Created symlink/home/guillaume/.config/systemd/user/default.target.wants/edgedb-server@examples.socket→ /home/guillaume/.config/systemd/user/edgedb-server@examples.socket.[systemctl] Created symlink/home/guillaume/.config/systemd/user/default.target.wants/edgedb-server@examples.service→ /home/guillaume/.config/systemd/user/edgedb-server@examples.service. Applyingmigrations... Everything is up to date. Revision initial Project initialized. Toconnect to examples, run `edgedb`The EdgeDB CLI created an automated startup script for SystemD, a common service manager in Linux. So the database will start automatically. The CLI also created a few files:
edgedb.tomlis just the regular configuration file for EdgeDB instance. By default, it only sets the database version.dbschema/default.esdlis the database schema for thedefaultmodule. Simple applications can fit in this module, but we can create new modules to separate the databases.
Writing A Schema
Apart from some parts like back references, the EdgeDB schema is self-explaining, and it’s aimed to be simple to read.
module default {
type User { required property email -> str { constraint exclusive }; required property createdAt -> datetime { default := datetime_current() }; link password := .<user[is Password]; # It's a back reference. User does not own the reference, Password contains the reference. multi link notes := .<user[is Note]; }
type Password { required property hash -> str; required link user -> User { constraint exclusive; # one-to-one on target delete delete source; } }
type Note { required property title -> str; required property body -> str; required property createdAt -> datetime { default := datetime_current() }; required link user -> User { on target delete delete source; }; }}You can also create abstract types and extend them in your type to have common properties like CreatedAt:
abstract type CreatedAt { property createdAt -> datetime { default := datetime_current(); readonly := true; };}To create a migration script, just run edgedb migration create. To migrate an existing database, run edgedb migrate.
Relearning Everything for Querying
Forget almost everything you know about databases. EdgeQL is a very different query language than SQL. And it’s normal, they want to be a Graph-relational database, not a relational database.
The query SELECT 1 + 1 is a basic mathematical operation that returns the result of 2. Well, it’s not the most complicated query, but the query does work. Let’s dig a bit further.
Based on the previous schema, to query users and their passwords, we can use the following query.
SELECT User { email password: { hash }};The syntax is a graph select. We don’t need to use an INNER JOIN, the database handles this for us.
For filtering the syntax is to use FILTER:
SELECT User { email password: { hash }}FILTER .email = "my@email.com";Also straightforward, ordering follows the same principle as ORDER BY.
Any Client to Help Me Write Queries?
Using an ORM helps to prevent injection, and to use a familiar API to interact with a database. EdgeQL is also vulnerable to “SQL” injections. Fortunately, EdgeDB provides multiple clients for different languages. Python, Javascript/Typescript, Go and Rust are officially supported. Community-supported clients are also proposed for .NET and Elixir. You can also enable EdgeQL-over-HTTP using a built-in extension. Another extension exists for GraphQL.
As a Typescript user, I used the official client. The client can read the schema and generate the connector and types for TypeScript, it’s the same as for Prisma.
Let’s see an example query from TypeScript, again with the same schema:
import edgedbClient from "edgedb";import edgedb from "./dbschema/edgeql-js";
const client = edgedbClient.createClient();
const user = await edgeDb .select(edgeDb.User, (user) => ({ ...edgeDb.User["*"], filter: edgeDb.op(user.email, "=", edgeDb.str(email)), })) .run(client);This code is strongly typed. The build will fail if the select query is wrong.
However, let me will emit some doubts about the generated client. It is written in typescript and needs to be transpiled to Javascript. It can break your tooling by adding a new layer of folders in the dist folder.
Does It Run Fast?
While I tried to use EdgeDB, Prisma was so close to it in terms of TypeScript API that I decided to compare EdgeDB to Prisma.
I did some tests, they may not represent real use cases, nor correct ones but at least they are unopinionated.
You can find my benchmark test suite on my github repository
I did use Postgresql 14 with Prisma, to have the latest performance benefits. If we use a new database, let’s use one of the latest versions of Postgresql. I benchmarked Prisma + Postgres with EdgeDB client + EdgeDB. The test run with 1000 rows. Select is fetching all rows.
I stop teasing you, here are the results.
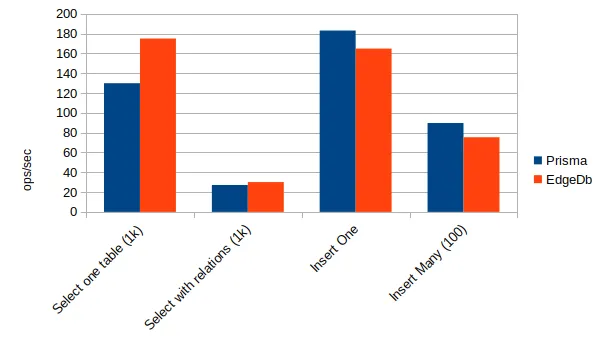
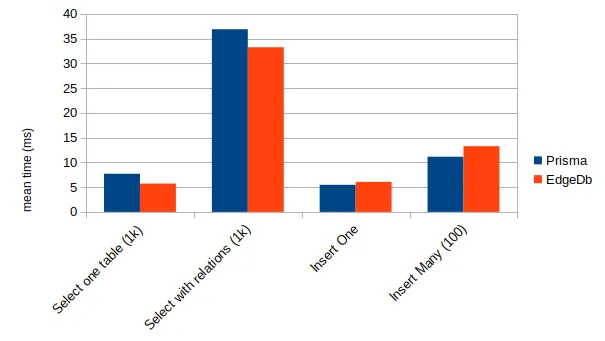
EdgeDB has a similar performance to Prisma. There is no red flag using it for performance.
While working on these charts, I got some very bad performances for EdgeDB with a very specific case. The case in question is selecting an empty table. Prisma was 6 times faster, while EdgeDB got almost the same result as selecting on a table. I suppose that Prisma does nothing about the data when there are no results, but EdgeDb does something.
One interesting thing is my benchmark has completely different results than theirs benchmarks, a lot in favor of EdgeDB with large benefits. Did I do something wrong? Or did they do something wrong on their side? I do not know.
Not So Different
EdgeDB claims to be a new database Engine, but it uses PostgreSQL as its underlying engine as claimed on the EdgeDB homepage. But having a wrapper you can’t use a specific extension, like sharding.
I’m not sure if I’m going to use EdgeDB in a real project. This would imply learning and mastering a very specific language for querying the database, for me and my coworkers. I would be tied to their databases. This is true for anything, choosing an ORM has also consequences but it’s a bit more simple to migrate from one client to another, you can have both at the same time with the same database. So it’s up to you.
I fail to see a real use case for EdgeDB. The database is PostgreSQL with a different syntax - this is not a true graph database. I may be wrong, but for me, it’s just a specialized ORM with a custom query language.
Authors
Full-stack web developer at marmelab, Guillaume was initially a Java guy. Fan of anime and video games, he can develop an AI that beats you every time.