
Optical Character Recognition on Handwritten Documents

In this article, we will explain how we approached the problem of OCR on handwritten population censuses, and the lessons we learned from this experimentation. This article will trace the libraries and online services we tested, as well as how we applied scientific publications from the University of Rouen to perform historical document analysis.
Indexing Historical Documents
Optical Character Recognition (OCR) is a mature technology with a wide range of usage, from document analysis to real-time translation using Google Lens’ “Scan and Translate” feature. Cloud platforms even offer services that detect administrative document layouts and extract structured text from them.
Yet, some OCR tasks remain challenging. For instance, using OCR to index historical documents doesn’t currently yield good enough results. This is because archives are handwritten, some of the scans have poor contrast, and many of the entries do not comply with the document structure, as shown in the picture below.
 |
|---|
| Source: POPP Dataset |
To perform document analysis and text recognition, the current solution of our client relies on humans to read and extract text from scans. But this method is quite slow (this can take months to years to obtain results), error-prone, and expensive.
Our client wanted to explore new advances in Artificial Intelligence, and especially in OCR, to automate part of this process and reduce the time to obtain structured data from their documents. They mostly need to extract first names and last names from civil registry scans.
Trial of OCR Open Source Libraries
The first open-source library we tested was Tesseract, as it is well-known in the OCR space and backed by deep learning. However, while Tesseract works really well for black-on-white typewritten text, it does not match our use case: handwritten text is not supported by default, and it requires image quality improvement to improve inferences. This is why we decided to stop experiments with this library.
 |
|---|
| Line Recognition using Tesseract |
The second open-source library we evaluated was OpenCV, a leading library in the field of computer vision. Though OpenCV has a wide range of features (from image manipulation to object recognition), it also provides text detection and text recognition features. Text recognition relies on external Deep Learning models that must be provided by the user. Yet, we did not manage to do recognition on a single line of text, as the documentation of OpenCV is quite obscure on this feature, this is why we chose to drop OpenCV usage.
Since we were not able to use open-source libraries to perform OCR on historical documents due to domain constraints, we decided to try cloud services provided by Amazon Web Service, Microsoft Azure, and Google Cloud.
Investigation on OCR Cloud Services
First of all, we decided to test AWS Textract with handwritten population censuses from 1936, since we usually work with this cloud provider in our projects at Marmelab.
We used Textract to analyze whole pages, with layout detection, and the results were not as good as we hoped. While the table detection is quite good, the model skips some words, has a hard time recognizing some words due to spidery writing, or splits words crossing lines into two cells. This is especially a problem when we need to be sure that the names are correctly detected and not split into two parts.
Furthermore, as of today, it is impossible to train a custom model with our own data to fine-tune the AWS-provided model to improve detection, this is why we decided not to continue with AWS Textract service.
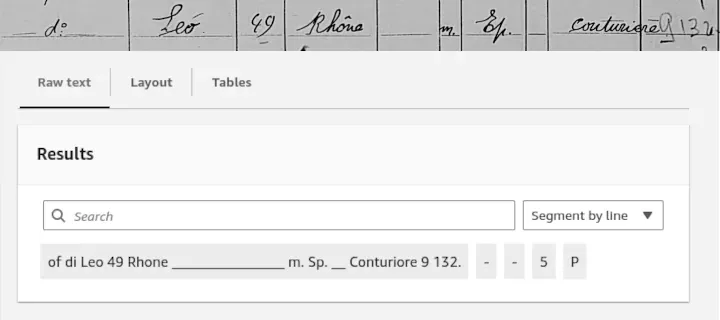 |
|---|
| Line Recognition using AWS Textract |
Secondly, we evaluated Azure AI Document Intelligence (ex Azure Form Recognizer) as our client uses Azure as its main cloud provider. Similarly to Textract, AI Document Intelligence provides layout and table detection in addition to Optical Character Recognition.
The results are quite equivalent to what AWS provides for the same task: table cell detection is great, but it suffers from the same problem with the recognition of crossing-lines words as its competitor. The main advantage of Azure AI Document Intelligence when compared to AWS Textract is that it can be fine-tuned with user-provided data. Yet, we chose not to continue with the service due to the crossing-lines word problem.
 |
|---|
| Line Recognition using Azure AI Document Intelligence |
Finally, the last cloud service we experimented with was Google Cloud Document AI, which provides, similarly to its competitors, table layout and cell extraction as well as Optical Character Recognition.
However, the layout detection provided by the service is quite… hazardous for our use case, as the model matched columns but not lines most of the time with our images. Hence, the model chooses to provide line-based recognition in this situation, which, ironically, gives better results than other cloud providers for historical document tables. The pre-trained model had the same issue with spidery writing as the OCR services provided by other cloud providers but can be fine-tuned with user-provided data. In the end, we chose not to continue with Google Cloud due to the hazardous layout detection.
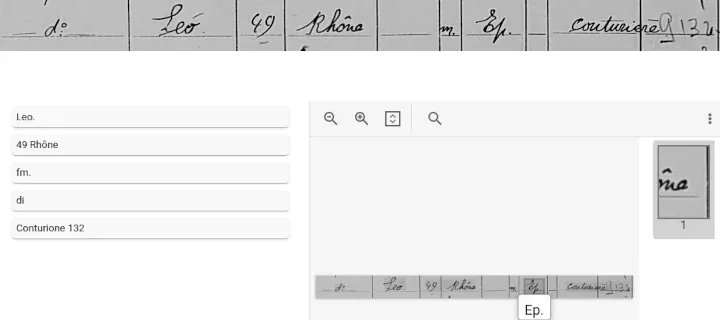 |
|---|
| Line Recognition using Google Cloud Document AI |
Since cloud-provided services did not match our needs for Optical Character Recognition on historical documents, we decided to search for a state-of-the-art solution in scientific literature.
Scientific Literature on OCR of Historical Documents
During our research on the topic, we found an interesting paper called Projet d’Océrisation des recensements de la Population Parisienne (POPP). The publication comes from a lab called LITIS at the University of Rouen, France. In this project, the research team focused on Optical Character Recognition on population census of Paris for 1926, 1931, and 1936. Since we were working on censuses from the same period, this project caught our attention and we decided to have a look at their methodology.
The POPP project defines a novel procedure to extract data from historical tables. The process consists of three different steps:
- First, the authors extract tables from the double-page spreads, unwrap them, and then extract lines from those tables using DhSegment (EPFL). DhSegment is a fine-tuned ResNet-50 model dedicated to extracting data from historical documents ;
- Then, the authors perform OCR on the extracted line using a custom model based on the BLSTM architecture. To improve detection results, they used the teacher-student model approach, and obtained a 4.52% Character Error Rate (CER) and 13.57% Word Error Rate (WER) on the validation dataset ;
- Finally, they integrated domain knowledge (dictionaries for names, list of common abbreviations for regions and countries, etc.) after OCR to improve detection.
Replicating the POPP Procedure
Our customer asked us to do a spike to validate this approach for their use case. During 1 sprint (2 weeks full-time by a team of 2 developers and a facilitator), we experimented with their procedure as follows:
We used the last version of DhSegment, based on the Torch Framework to crop tables from the double-page spreads. For this, we needed to label and fine-tune the model on a dataset of 80 double pages and obtained good results on the validation and test datasets.
We also used OpenCV to unwrap the tables using a 2D rotation matrix. However, we did not have time to perform line extraction during this sprint as we chose to focus on OCR technologies.
For the OCR part, we decided to try TrOCR, which is a state-of-the-art OCR model from Microsoft. However, when we performed detection on the cropped lines using the French version of the model, we faced the fact that the model was only returning plain text, with no separator (e.g. comma or slash).
To solve this challenge, we decided to fine-tune the French model using the training dataset made available by the POPP project to match their output format (where columns are divided using slashes, with additional metadata added) on Google Collab.
We obtained a 6% Character Error Rate (CER) and a 22% Word Error Rate (WER) after one epoch of training, but, we did not manage to fine-tune the model on Google Collab due to connection failure to the dataset drive during training, and the lack of remaining time on the sprint ;
We also did not have time to integrate domain knowledge during our tests and skipped this part.
 |
|---|
| Results Obtained after One Epoch of Fine-Tuning |
These results were encouraging, yet not good enough to replace human work. At the end of the spike, the customer decided to stop the exploration and to discuss with the authors of the paper to see if they could provide us with insights on how to improve the results.
Transformers for Full Page Recognition
We met the research team from the LITIS Lab at the University of Rouen and showed them our results. They quickly told us the limitations we should expect from the POPP procedure, and to which point we could improve our results. This discussion revealed that this algorithm was not the best fit for our use case.
They also exposed their advances on OCR on historical documents. They are now working on a new project called Exo-POPP, which focuses on information extraction about marriages using full-page text analysis.
They are now using a Transformer-based algorithm. Transformers models are heavily used in language modeling as they capture relationships between parts of a text; this is especially interesting in the context of marriage historical documents, as they are usually represented as full-text paragraphs.
Their preliminary results are quite promising, in particular, because they no longer need to detect tables and lines. Their new algorithm (unpublished to this date) processes full page scans and uses domain knowledge to fix OCR errors. Their model is also capable of extracting named entities (such as first name, last name, date, etc.) from unstructured text, which is a great improvement over the previous method.
We are now waiting for the publication of their new algorithm to test it on our use case.
Conclusion
While Optical Character Recognition has rapidly evolved in the last decade, the analysis of historical documents still faces challenges: the junction of handwritten text and the poor scan quality of some documents make Character Recognition harder. Yet, the addition of domain knowledge helps improve detection accuracy. Furthermore, the recent advances in Deep Learning with the introduction of transformers-based models can enhance detection with full-page recognition, instead of single-line analysis.
In this experiment, we learned that cloud-based document vision services do work for many traditional use cases (well-structured documents, typewritten text, etc.). Those services abstract away most of the difficulties of using deep learning models with SDKs while providing a good character recognition rate.
For use cases not covered by cloud services, we learned that using open-source libraries requires a lot of work and scientific expertise. Results are never good enough out of the box, and it is necessary to fine-tune the models to obtain good results. This is a time-consuming task and requires a lot of data to train the models.
Finally, when engineering hits its limits, it is necessary to turn to scientific literature to find new approaches to the problem. Talking with researchers in the domain is a great way to learn about the state of the art, and get a glimpse of what the future holds.
Authors
Full-stack web developer at marmelab, Jonathan likes to cook and do photography on his spare time.