
Cut Through The Noise: AI-Curated News Digests

With so many sources of information available, it’s easy to become overwhelmed by information overload. Let’s use AI to select and summarize the most relevant articles.
The Problem: Information Overload
As a developer, I need to stay informed of the latest trends. I have many sources of information: newsletters, RSS aggregators, social networks, blogs, etc. However, I often find myself buried under a pile of articles, struggling to extract the most relevant information efficiently. It’s easy to fall into information overload.
I appreciate when a newsletter provides a summary of the most important articles. The curator has already done the hard work of sifting through the noise to find the most important news. But there is no curator for my personal interests. So I have to manually curate the articles myself, which is time-consuming and tedious.
I would love to have a personal curator. They would know my interests and my sources, and produce a curated list of articles based on these interests every week.
There is no such thing as a personal curator. The next best thing is an AI-powered curator. Let’s build it!
My Personal Curator
I developed a CLI tool that leverages AI to curate a list of articles based on a set of interests. The tool is designed to be flexible and easy to use:
# Get the 5 best articles about AI and React from Hacker News$ npx curate -m 5 -i AI React -a https://news.ycombinator.comIt outputs the summary of the most relevant articles to STDOUT:
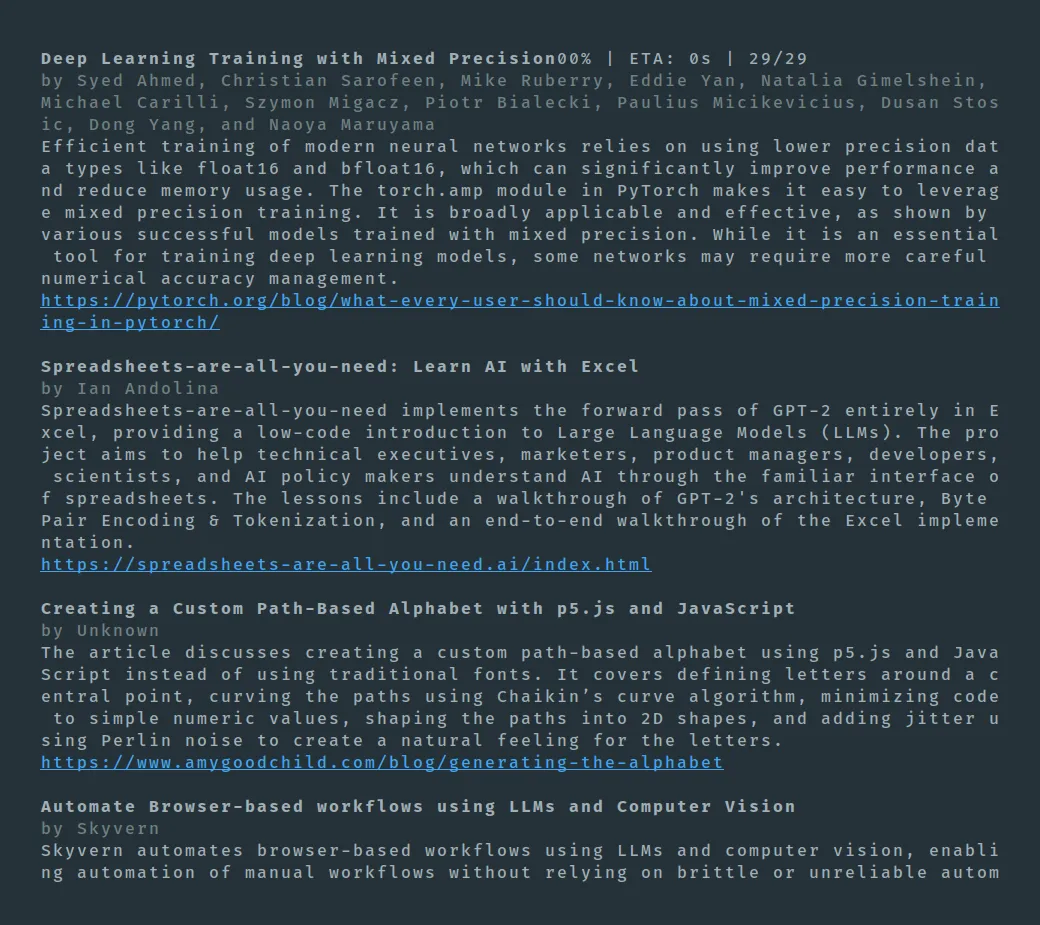
I published this Curator Agent as a npm package. Feel free to install it and give it a try: curator-ai.
The source code is available on GitHub: marmelab/curator-ai. In this article, I will walk you through the process of building this tool, from the initial idea to the final implementation. I’ll cover the main challenges I faced and the solutions I found to overcome them.
The Big Picture
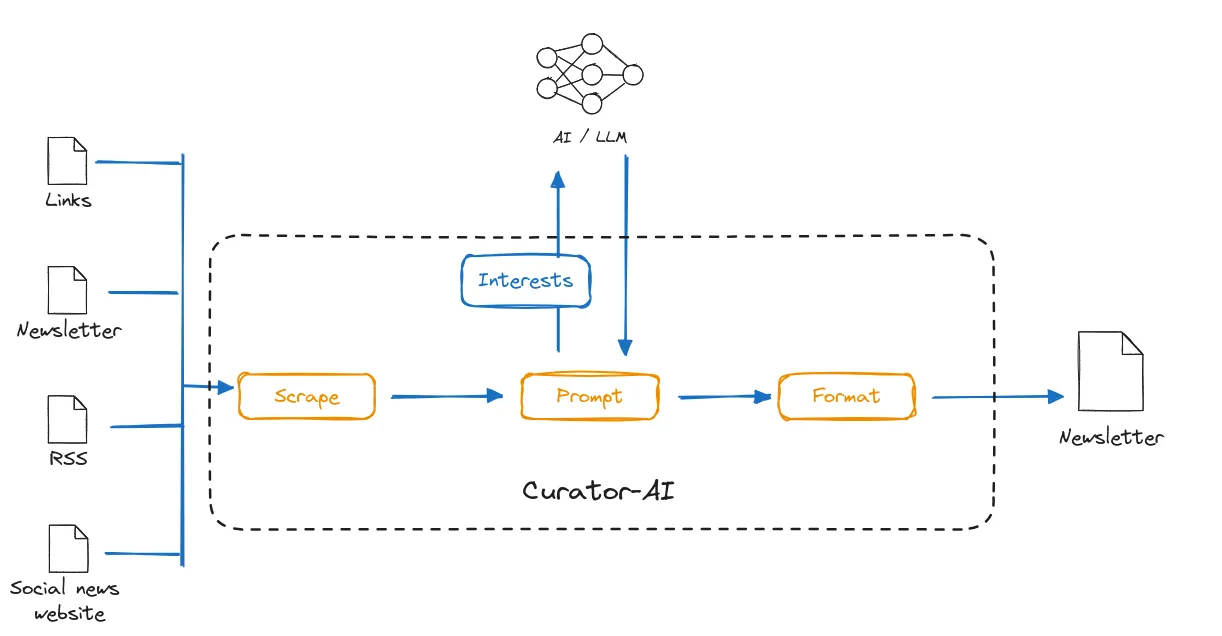
The tool needs three inputs:
- the resources to analyze (RSS feeds, articles, social news websites, etc.),
- the reader’s interests for (AI, React, PHP, …),
- and how many articles they want to read.
The tool must execute several tasks:
- Fetch the articles.
- Extract the content of the articles and remove navigation links, social links, etc.
- Summarize and rate each article based on the interest list.
- Format and send the final newsletter.
Steps 1, 2, and 4 can be done with JavaScript. Large Language Models (LLMs) have unique capabilities that are required to achieve the third step:
- Natural Language Processing: AI can understand and interpret human language. This capability allows them to analyze the content of articles and identify key information.
- Relevance Ranking: AI can determine the relevance of articles based on specific interests or criteria.
- Generating Summaries: AI can generate concise summaries of articles, distilling the most important information into a few sentences.
For this tool, I chose the OpenAI API because Marmelab already has a subscription for it, and because its GPT-4 model is better at processing large inputs. To call it with Node.js, I used a package called OpenAI Node API Library. The main challenge of the AI part is to create the right prompt.
Now, let’s dive into the details of each step.
Building a Command-Line Interface
To build a CLI in Node.js, I made the no-brainer choice: commander. It is simple but powerful, with good support for parsing arguments and options.
The curate command looks like the following:
# Get the 5 most relevant summaries about AI and React, based on a list of RSS feedsOPENAI_API_KEY=XXX curate --rss https://dev.to/feed --interests AI React --max 5
# Summarize a list of articles based on URLs passed directly as parametersOPENAI_API_KEY=XXX curate --urls https://example.com/article1 https://example.com/article2 --max 10
# Summarize a list of articles based on a file containing URLsOPENAI_API_KEY=XXX curate --aggregator-file myFile.txt --max 5The source is standard commander code:
#!/usr/bin/env nodeimport { program } from "commander";import fs from "node:fs";import cliProgress from "cli-progress";
const helpText = `Examples: $ curate -a https://news.ycombinator.com/ -i science space research -m 3`;program .name("curate") .description("Read, select and summarize a list of articles") .option("-u, --urls [urls...]", "Wep pages to curate") .option( "-f, --url-file <filename>", "Text file containing a list of URLs to curate, one per line", ) .option("-a, --aggregators [urls...]", "Aggregator web pages to curate") .option( "-F, --aggregator-file <filename>", "Text file containing a list of aggregator URLs to curate, one per line", ) .option("-r, --rss [urls...]", "RSS feed to curate") .option("-i, --interests [interests...]", "List of interests") .option("-m, --max <number>", "Max number of articles to return", "5") .addHelpText("after", helpText) .showHelpAfterError() .action(async (options) => { // get links from urls // ... // get links from aggregators // ... // deduplicate urls // ... // curate // ... // print summaries // ... });
program.parse();Scraping The Articles
In the most simple case, the user provides a list of article URLs:
OPENAI_API_KEY=XXX curate --urls https://example.com/article1 https://example.com/article2 --max 10After fetching the URLs with fetch(), I extract the text content using the popular cheerio library. But Cheerio returns the entire text of the page, including the navigation, social widgets, etc. How do I extract only the main content of the page?
My first attempt was to ask the AI to clean up the content on the page. It worked relatively well, but it was expensive. So I decided to use a specialized library for that. I discovered Readability, the standalone version of the Firefox Reader View that strips away clutter like buttons, ads, background images, and videos. It works well enough and is simple to use.
The final scrape function looks like this:
// in scrape.tsimport { Readability } from "@mozilla/readability";import * as cheerio from "cheerio";import { JSDOM } from "jsdom";
export interface ScrapeOptions { url: string; maxContentSize?: number;}
export const scrape = async ({ url, maxContentSize = 12000,}: ScrapeOptions) => { const response = await fetch(url); // fetch the HTML content of the page const $ = cheerio.load(await response.text()); // create a new cheerio instance const dom = new JSDOM($.html()); // create a new JSDOM instance because Readability needs it const article = new Readability(dom.window.document).parse(); // parse the content with Readability to keep only the article content return article?.textContent.substring(0, maxContentSize); // return the content of the article};The CLI also accepts a list of aggregator URLs (like Hacker News, dev.to, etc.) from which I must extract the article links. I won’t go over the details here, but I used the cheerio library to extract the links from the page and then called the scrape function for each link.
The CLI also accepts a list of RSS feeds. I used the rss-parser library to extract the article links from each feed.
Finally, since several sources may reference the same article, I deduplicate the list of URLs using a simple Set.
Prompting The LLM
For each article, I want the LLM to rate it according to my interests, and to summarize it. I wrote a summarizeArticle function for that. For example, for the following lists of articles:
https://marmelab.com/blog/2023/11/28/using-react-admin-with-your-favorite-ui-library.htmlhttps://marmelab.com/blog/2023/12/11/how-we-tackled-ocr-on-handwritten-historical-documents.htmlThe summarizeArticle function returns a list of JSON objects like this:
[ { "title": "Using React-Admin With Your Favorite UI Library", "author": "Gildas Garcia", "summary": "React-admin, a frontend framework using React, can be used with any UI library, such as Ant Design, Bootstrap...", "relevancy_score": 100, "link": "https://marmelab.com/blog/2023/11/28/using-react-admin-with-your-favorite-ui-library.html" }, { "title": "Optical Character Recognition on Handwritten Documents", "author": "Jonathan ARNAULT", "summary": "Optical Character Recognition (OCR) has various applications, but it faces challenges when applied to historical...", "relevancy_score": 90, "link": "https://marmelab.com/blog/2023/12/11/how-we-tackled-ocr-on-handwritten-historical-documents.html" }]The OpenAI prompt examples illustrate how to summarize notes. This is not exactly what I want, but it’s close enough to get me started. After some tweaking, the prompt looks like this:
You will be provided with a technical article, and your task isto summarize the article as follows:
- Summarize the main takeaways. The summary should start with the most important information, not with an introduction like "The article discusses...".- Rate it by relevancy from 0 (not relevant) to 100 (very relevant). The more the article talks about {{user interests}}, the more it is relevant.- Shape your answer in JSON format, not in markdown or HTML. Do not include a JSON header. Include the following fields: - title: the article title - author: the article's author - summary: the summary of the article. The summary should be short: at most 3 sentences and 80 words. - relevancy_score: the relevancy scoreI use this prompt in the summarizeArticle function:
// in curate.tsimport { getCompletion } from "./getCompletion";import prompt from "./prompt";
export const summarizeArticle = async ({ text, link, interests = [] }) => { const completion = await getCompletion({ messages: [ { role: "system", content: prompt(interests) }, { role: "user", content: text }, ], }); if (!completion.message.content) return; try { return { ...JSON.parse(completion.message.content), link }; } catch (e) { console.error(e); return; }};The actual call to the OpenAI API takes place in the getCompletion function:
// in getCompletion.tsimport OpenAI from "openai";import { config } from "dotenv";
config();
export const getCompletion = async ({ messages, model = "gpt-3.5-turbo-1106", temperature = 0.7, top_p = 1,}) => { if (!process.env.OPENAI_API_KEY) { throw new Error("OPENAI_API_KEY not set"); } const openAI = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); // we ask the AI with our prompt const completion = await openAI.chat.completions.create({ messages, model, temperature, top_p, }); return completion.choices[0];};Keeping the N Most Relevant Articles
The rest is easy: I have to keep the most relevant summaries. Each article has a relevancy_score given by the LLM based on the user’s interests. The getMostRelevant function sorts the articles by relevancy_score and keeps the max most relevant ones.
const getMostRelevant = ({ summaries, max = 5 }) => summaries.sort((a, b) => b.relevancy_score - a.relevancy_score).slice(0, max);Rendering the Results
I used chalk to render the results on the console in a readable way. For instance, the curate -f links.txt -i react -m 3 might produce the following result:
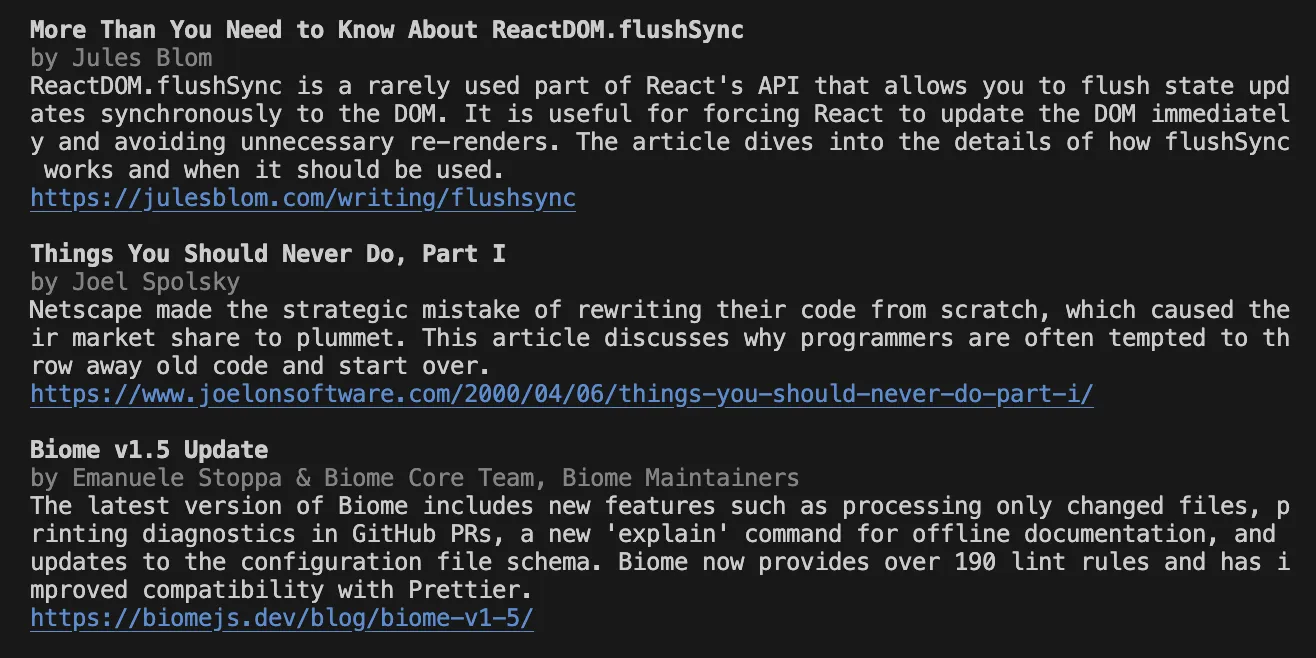
Since the program produces a JSON output, it’s easy to render the results in other ways, like in a generated HTML page, or an email.
Challenges
I had to face quite a few challenges in the process of building the AI curator, such as:
- Costs: I tried to use LLMs for link extraction, content extraction, and the final newsletter formatting. It works, but it’s more expensive than doing those things by hand. The choice of the LLM is also crucial (GPT4 is better than GPT3.4-turbo, but much more expensive). The cost varies depending on the number of sources and the size of the articles, but I’d say that generating one newsletter with GPT-3.5 routinely costs a few cents. It’s acceptable for a personal project, but it would probably be too expensive for a customer-facing app. The obvious way of reducing costs would be to use chunking and embeddings to reduce the input tokens sent to the LLM.
- Relevance: The AI is not perfect. It sometimes misses the point of the article, returns non-JSON output, or gives a low relevancy score to an article that is actually relevant. LLMs don’t know how to count: my instructions for a concise summary are often overlooked. I had to tweak the prompt to get better results. And trying to reduce the costs by switching to a smaller model often results in less relevant summaries. To further improve the result, a control LLM could be used to check the summaries and ask for a new one if the result is not good enough.
- Speed: Generating a newsletter may take several minutes if there are many articles to summarize. This is not a problem in my case, as the generation of the newsletter can be done at night by a cron. I just inserted a progress bar to reassure the user that the program was still running. But for customer-facing apps, reducing the response time of LLM-based apps is crucial. It implies fetching the articles in parallel, using streaming to render the result as soon as possible, and caching the results.
These are common challenges that you will face when building any AI-powered tool. We’ll probably publish more articles on these topics in the future.
Conclusion
With the combination of JavaScript and the OpenAI API, I managed to reduce the time I spend reading news, without the fear of missing out (FOMO) important information.
If you’re a developer looking to stay informed, you will probably appreciate this tool that extracts valuable insights from an ocean of information.

You can give it a try by installing the Curator AI package on your own machine.
The result is fine for my use, but it could benefit from a web frontend where other users could fill in their interests and get a personalized newsletter. This would require a backend to store the user’s interests and the articles, and a frontend to display the newsletter. The backend could also cache the results to avoid calling the LLM too often. This is left as an exercise for the reader.
Authors
Full-stack web developer at marmelab, Adrien was previously working as an instructor in Alsace. He loves music and plays drums.