
Who Needs Human Code Reviews When We Have AI?

In our quest to master AI and automation, we have been experimenting with pull request reviews. It turns out this very blog post was written in a code editor and submitted as a pull request. How hard would it be to have an AI review the pull request?
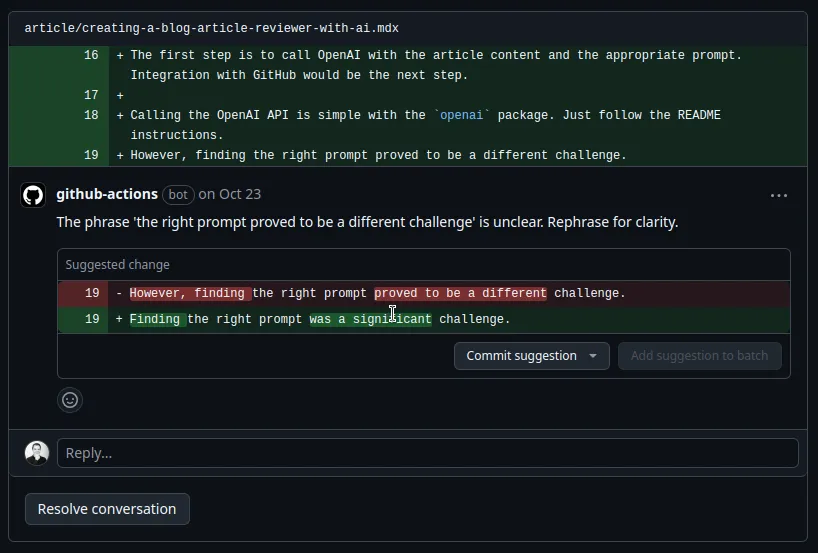
We built a bot leveraging an LLM from OpenAI that reviews the pull requests on the blog repository. The bot provides comments and suggestions to improve the article. The bot is integrated with GitHub actions, so it runs automatically on every pull request. It even reviewed this very article!
The Big Picture
I built a GitHub action that triggers on every pull request. The action retrieves the diff of the pull request, sends it to OpenAI’s chat completion API with custom instructions, and uses the result to create a review on the pull request with the comments and suggestions.
Calling the OpenAI API is pretty straightforward, thanks to the openai package. The difficulties are elsewhere:
- How do you properly prompt the LLM to review an article?
- How do you use the LLM response to create a review with the GitHub API?

The Quest for the Right Prompt
I went through numerous iterations of the prompt to get the AI to provide the right feedback. It really is an iterative process, as I discovered many ways the AI could fail by testing it on various inputs.
Before writing a prompt, I recommend gathering a few examples of the input you want to process, focusing on diversity and edge cases. I also recommend running the prompt many times on the same content to see how the AI behaves.
Here are the lessons I learned.
The AI Loves To Explain What It Does
The OpenAI’s LLMs systematically justify their response. I only wanted the result. I had to add instructions to prevent the AI from explaining itself.
Do not explain what you are doing.The AI Can Generate JSON Rather Reliably If You Ask Correctly
If the LLM response has to be read by a program, as in my case, it’s better to have it in a structured format. You can make the AI use a specified JSON structure by providing a response template.
Respond with the following JSON structure:
[ { "comment": "<comment targeting one line>", "lineNumber": <line_number>, "suggestion": "<The text to replace the existing line with. Leave empty, when no suggestion is applicable, must be related to the comment>", "originalLine": "<The content of the line the comment apply to>" }]Note the AI tends to wrap the result in a ```json tag, even when you tell it not to.
Additionally, with models 4o-mini and above, when you set the response_format.type to json_schema, you can provide the json_schema for the answer. For example:
{ response_format: { type: "json_schema", json_schema: { name: "review-comments", schema: { type: "object", properties: { comments: { type: "array", items: { type: "object", properties: { comment: { type: "string" }, suggestion: { type: "string" }, originalLine: { type: "string" }, lineNumber: { type: "number" }, }, }, }, }, }, }, }}The AI Does Not Know How To Count
To generate comments on a specific line, I needed to provide the line number. Initially, I passed the article directly and asked the LLM to include a line number for each comment. It did generate line numbers, but they were wrong. They were often larger than the size of the text.
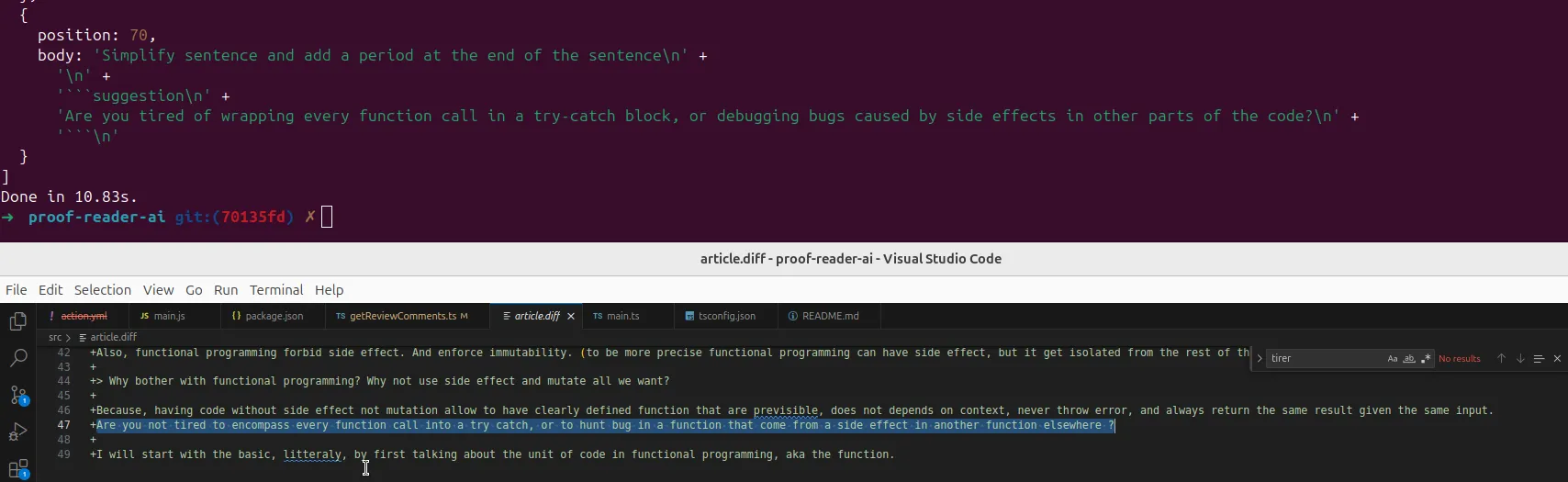
Interestingly, the AI could quote the correct line when asked to.
So, I modified the prompt to add line numbers at the start of each line. This helped improve the LLM accuracy when citing line numbers, although it still got it wrong occasionally.
The AI Result Is Random By Default
It should be obvious, but I was still surprised by how the same prompt could yield vastly different results. Lowering the temperature helped to get more consistent results.
The AI Sometimes Fails
Given the previous two points, it was necessary to check the AI output to make sure it could be transformed into a proper diff.
I instructed the AI to include the original line along with the comment. With the additional info, I was able to check the comment position and fix it if needed.
But not always. In the case where I was not able to locate the target line properly, I discarded the comment altogether.
The AI Always Tries To Do Something
The code review bot runs on every push. If the first draft often needs improvement, the final draft is usually good and doesn’t need any changes.
However, when asked to suggest improvements, the AI will always provide some, even if there’s nothing to fix. I had to explicitly tell it to return an empty array if no changes were needed.
Provide comments and suggestions ONLY if there is something to improve or fix,otherwise return an empty array.The Final Prompt
Given all the lessons learned, here is the prompt I ended up with:
Your task is to review pull requests on a technical blog.
Instructions: - Do not explain what you're doing. - Provide the response in the following JSON format, and return only the json:
[ { "comment": "<comment targeting one line>", "lineNumber": <line_number>, "suggestion": "<The text to replace the existing line with. Leave empty, when no suggestion is applicable, must be related to the comment>", "originalLine": "<The content of the line the comment apply to>" } ] - returned result must only contain valid JSON - Propose changes to text and code. - Fix typos, grammar, and spelling - ensure short sentence - ensure one idea per sentence - simplify complex sentences - No more than one comment per line - One comment can address several issues - Provide comments and suggestions ONLY if there is something to improve or fix ; otherwise return an empty array.
Git diff of the article to review:Integrating With The GitHub API
To integrate with the GitHub API in a GitHub action, I used @octokit/rest.
This was a three-step process:
- Retrieve the current pull request details
- Retrieve the diff
- Create the review
Retrieving the Current Pull Request Details
In a GitHub actions context, you must first execute the actions/checkout@v3 action to checkout the code. Then, using the GITHUB_EVENT_PATH environment variable, you can read the repository information:
const { repository, number } = JSON.parse( readFileSync(process.env.GITHUB_EVENT_PATH || "", "utf8"),);return { owner: repository.owner.login, repo: repository.name, pull_number: number,};Retrieving the Diff
To retrieve the diff for the current pull request, use octokit.pulls.get:
const response = await octokit.pulls.get({ owner, repo, pull_number, mediaType: { format: "diff" },});Creating the Review
After retrieving the LLM comments, you can create a code review:
await octokit.pulls.createReview({ owner, repo, pull_number, comments, event: "COMMENT",});A GitHub comment consists of a line, path, and body. I placed the comment and the suggestion in the body like this:
body: `The phrase ‘for what I wanted I needed to’ is awkward. Rephrase for clarity.
I needed to do the following:`;
Be careful to remove any indentation, as it could change the suggestion into a block quote.
The Result
The bot is now running on the Marmelab blog repository. It reviews every pull request and provides comments and suggestions to improve the article. It detects basic grammar and spelling mistakes and also provides simple tips to improve the text.
However, it’s far from perfect. It always offers suggestions even on text it suggested itself. It often suggests comments that simplify too much, losing the full meaning.
It lacks additional context to mimic style from other articles, and with its limited memory, it cannot currently load sufficient examples in the code to achieve that.
We also need to tweak the prompt to keep a consistent style between articles. The AI is very good at mimicking the style of the input, so we need to include the text of past articles in the prompt.
In other terms, we still need humans to review the articles. However, the bot can catch the low-hanging fruits and help the human reviewer focus on the more complex issues.
Conclusion
Here is the repository of the GitHub actions: AI Article Reviewer. The action has been published on github actions marketplace. Feel free to try it by adding the following workflow:
name: AI Code Reviewer
on: pull_request: types: - opened - synchronizepermissions: write-alljobs: review: runs-on: ubuntu-latest steps: - name: Checkout Repo uses: actions/checkout@v3
- name: Proof Reader AI Action uses: marmelab/proof-reader-ai@main with: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # The GITHUB_TOKEN is there by default so you just need to keep it like it is and not necessarily need to add it as secret as it will throw an error. [More Details](https://docs.github.com/en/actions/security-guides/automatic-token-authentication#about-the-github_token-secret) OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }} OPENAI_API_MODEL: "gpt-4o-mini" # Optional: defaults to "gpt-4o-mini" do not support model prior to 4Authors
Full-stack web developer at marmelab, loves functional programming and JavaScript.