
DevFest Dijon 2024: Retour sur les bancs de la fac


Des salles de conférences aux noms de ducs comme Philippe Le Hardi, Jean Sans Peur ou bien encore une chouette placardée en logo de partout : il n’y a plus de doute, ce DevFest se déroule bien en pleine capitale bourguignonne !
Voici un topo de nos sujets préférés au cas où vous auriez manqué cette édition.

En plein cours magistral (source : Linkedin)
Alerte, tout brûle ! Comment gérer des incidents techniques
Si quelqu’un pense qu’il y a un incident, c’est que c’est sûrement le cas
Alexis Chotard nous a présenté l’envers du décor de PayFit, une “licorne” française qui propose un outil de gestion de paie et de ressources humaines.
Malgré la sensibilité du domaine (tout le monde veut recevoir sa paye à temps), ils sont sujets à de nombreux incidents (1/jour en moyenne). Alexis nous a proposé un retour d’expérience sur la gestion (récente) des incidents chez PayFit.
Un premier conseil est de classer les incidents en se basant sur différentes métriques (durée, nombre d’utilisateurs impactés, période, scope de la fonctionnalité cassée). Ils ont défini pour cela 4 niveaux de criticité qui permettent de prioriser les urgences.
Ensuite, lors de chaque incident, une personne est désignée pour faire le suivi. C’est elle qui coordonne les opérations qui se traduisent en plusieurs étapes pour s’assurer de la bonne résolution du problème :
- Détection (via des métriques métiers de préférence, sinon techniques)
- Communication (interne pour alerter et s’organiser pour résoudre le souci et externe pour avertir les utilisateurs)
- Résolution (stabilisation, limitation des impacts, passage en mode dégradé)
- Améliortion (mesure de différentes métriques sur la gestion de l’incident)
- Post-mortem (pour comprendre les origines et identifier les leviers d’actions pour éviter que ça ne se reproduise)
La conférence était dense mais distribuait plein de bons conseils et de bonnes pratiques. On retient :
- avoir une procédure existante “à dérouler” lors des urgences,
- ne pas blâmer des individus,
- faciliter la discussion entre les différentes équipes/métiers, et surtout
- l’importance des post-mortems pour identifier les axes d’améliorations.
Un autre aspect intéressant (mais survolé ici) concernait le focus plus “métier” des incidents en utilisant des métriques moins techniques (par exemple en comparant un nombre de vidéos visionnées plutôt que le nombre d’erreurs 500 reçues).
Au passage, merci à Alexis d’avoir mis en ligne ses slides !
Microservices, maxi supplice
On doit vous avouer que le titre nous a beaucoup aguiché, peut-être en raison de quelques expériences traumatisantes… Yann Jacquot et Alexis Stefanski ont présenté les différentes étapes de la fusion de 4 services en un seul bon gros monolithe, moins prétentieux mais beaucoup plus fonctionnel !
Tout commence par un mauvais choix technique dès le démarrage du projet CircularX : l’équipe fait au plus simple en reprenant en partie une architecture microservices éprouvée de la maison mère.
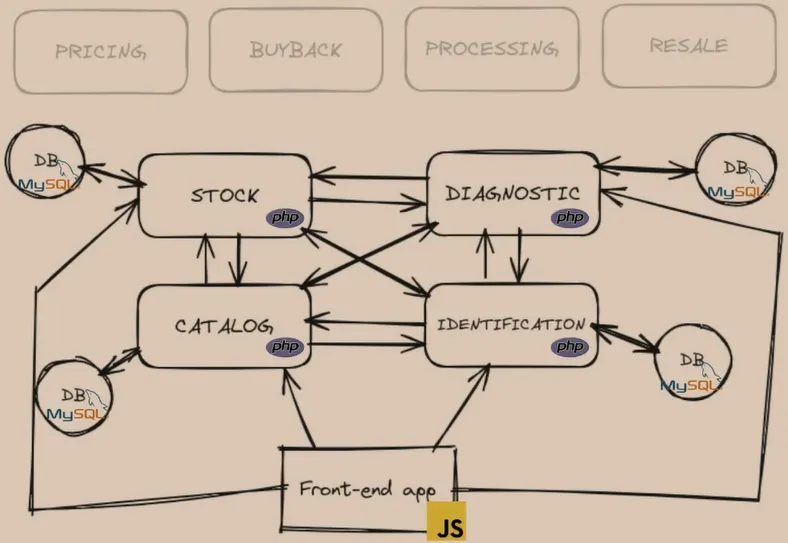
Très vite, ils se retrouvent avec de gros problèmes de performance : lenteurs et indisponibilités dues à des appels croisés entre services, mais aussi un couplage très fort entre chaque entité, ce qui complique le développement. Il n’y a pas de doute, ils sont face à un monolithe distribué.
Pour en venir à bout et revenir sur une architecture monolithique, ils ont établi des prérequis pour réussir leur migration dans le temps imparti (3 mois) et sans downtime :
- s’assurer d’être en capacité de revenir en arrière à tout moment de la migration,
- mettre en place des outils de monitoring pour évaluer les impacts des modifications (mise en place de l’APM sur Sentry, tests de charges et métriques AWS)
- définir l’ordre de fusion des services, pour avancer de façon incrémentale et pas en mode “Big Bang”.
On a découvert AWS Database Migration Service, qu’ils ont utilisé pour faire de la réplication de données entre les BDD des services et la BDD du monolithe. Ce service leur a permis de rollbacker à tout moment sans perte de données.
On a aussi vu comment ils ont rendu la fusion des services transparente aux yeux des clients, en redirigeant les requêtes HTTP vers le monolithe grâce à une API Gateway en amont. Ce qui a d’ailleurs donné lieu à des situations marrantes où certains services s’appelaient eux-mêmes.
Au final, leur plan d’action donnait ceci :
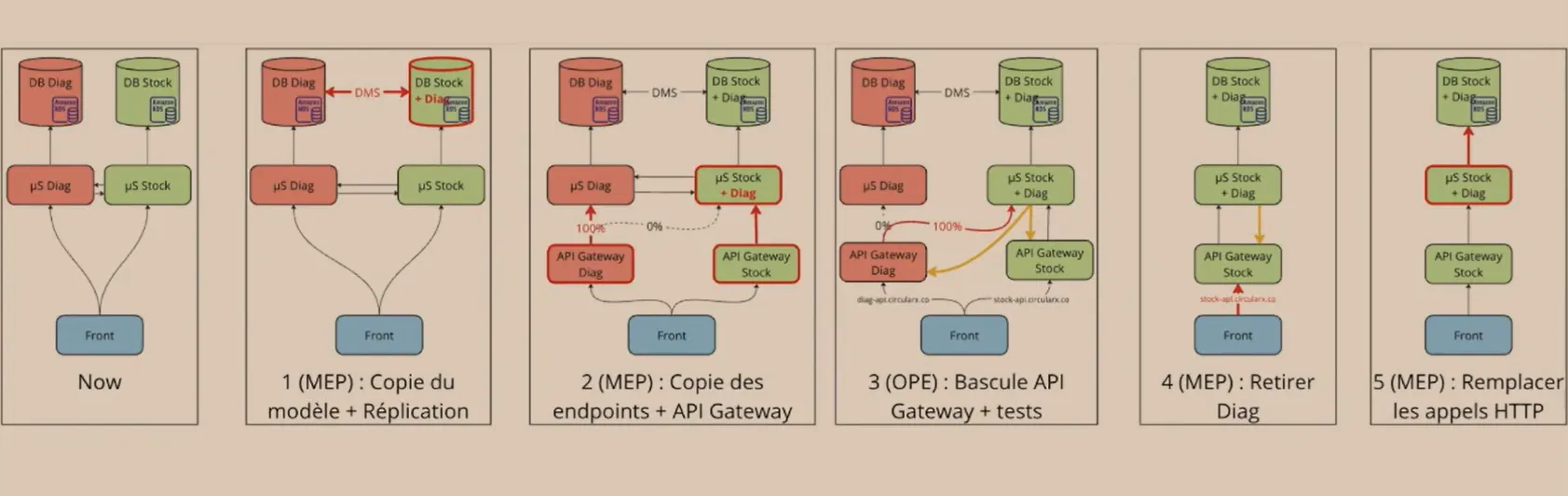
Les 2 comparses ont présenté honnêtement et avec un brin d’humour les succès (migration effectuée dans les temps, grosse amélioration de performances), mais aussi les erreurs commises durant cette migration pas si évidente. C’est un bon point de départ pour qui souhaite retravailler son architecture un peu trop distribuée.
La présentation, déjà donnée à Touraine Tech 2024, est d’ailleurs disponible en ligne :
Chrome DevTools from Zero to Hero
Quand on crée des applications web on passe pas mal de temps dans un navigateur, et pourtant il y a un tas d’outils qu’on ne connaît pas forcément. L’objectif de Simon Belbeoch à travers cette présentation était de nous en faire découvrir quelques-uns.
D’abord, un comportement méconnu de console.log, qui “lazy load” les informations :
const toto = { a: 1, b: 2 };console.log(toto);toto.a = 3;Contrairement à ce à quoi on peut s’attendre, la ligne console.log(toto); affiche {a:3,b:2} et pas {a:1,b:2}.
On a eu le droit ensuite à une liste de tips utilisables à la fois dans le navigateur ou dans NodeJS :
- le triptyque des logs
console.info,console.warnetconsole.error, - affichage d’un tableau avec possibilité de tri, avec
console.table([{firstName: "Tyrone", lastName: "Jones"}, {firstName: "Janet", lastName: "Smith"}]), - se simplifier la vie avec
console.time("label"),console.timeLog("label")etconsole.timeEnd("label")pour évaluer le temps passé dans une fonction, - obtenir la stack trace via
console.trace(), - compter le nombre de fois qu’un bout de code est exécuté via
console.count("label"), - logguer une erreur conditionnellement avec
console.assert(), - activer le debugger via le code en ajoutant une instruction
debuggern’importe où, - accéder à l’élément du DOM sélectionné dans le navigateur en utilisant la variable
$0.
Pour finir, il nous a offert une chouette cheathseet (pour Mac) qui condense ces infos ainsi que d’autres raccourcis :

Sans être révolutionnaire, cette présentation rapide et légère (20 minutes) nous a permis de découvrir (ou redécouvrir) quelques astuces toujours pratiques qui peuvent servir au quotidien. On aurait adoré une deuxième partie pour présenter des sujets plus “avancés” comme l’utilisation du profiler.
Les tendances en architecture, entre mythes et réalité
Adrien Nortain nous a proposé de prendre du recul sur les effets de mode et les révolutions auto-proclamées dans la jungle des architectures logicielles, côté back et front.
En retraçant, dans une première partie, une généalogie des concepts, il a souligné les origines parfois “antiques” (programmation fonctionnelle - 1930, POO - 1960, …) de pratiques contemporaines, tout en invitant l’auditoire à ne pas négliger les fondamentaux théoriques derrière ces architectures.
Enfin, Adrien Nortain nous a proposé un tour d’horizon des systèmes émergents tels que la Cell Based Architecture, l’Edge Computing ou encore le Modulith ou Modular Monolith (EN).
Le tout en 50 minutes, avec une tendance assumée au name dropping, laissant une foule de lectures à prévoir en 2025 pour ceux qui souhaitent approfondir ces concepts !
Comment ne plus avoir peur de vos fichiers de log ?
Inexistants, pas assez ou trop nombreux, en tout cas jamais pertinents, les logs sont souvent les parents pauvres de nos projets. Dans cette conférence, Virginie Pageaud place ce sujet, à priori peu passionnant, au centre du débat.
Cet outil, souvent laissé à l’appréciation et au seul profit des équipes de développement, peut pourtant devenir essentiel pour les missions d’exploitation et d’astreinte.
Quelques idées générales et bonnes pratiques :
- définir les personas des utilisateurs des logs tout au long du cycle de vie du projet (développement, tests, exploitation),
- inclure l’existence de logs clairs et utiles dans la Definition of Done,
- établir une classification claire des traces selon le contexte du projet, par exemple :
- réserver
WARNINGpour des fonctionnalités dégradées, - utiliser
ERRORuniquement si une action immédiate est nécessaire,
- réserver
- faire référence au métier de l’utilisateur (par exemple, spécifier un produit par sa référence métier plutôt que par son ID en base de données),
- expliciter l’écart entre les données reçues et attendues,
- spécifier les actions métiers à mener et les informations requises pour celles-ci,
- prendre en compte le cadre réglementaire (RGPD, Cyber Resilience Act) concernant les durées de rétention et les données sensibles ou confidentielles.
Sans apporter de révolution copernicienne à notre métier, cet éclairage a souligné l’intérêt d’accorder aux traces une attention méritée au sein de nos projets.
On a aussi aimé
- TDD décortiqué : voyage initiatique au coeur du TDD, pourquoi en faire, mais surtout comment.
- Les différents modes de synchronisation des data platforms chez Carrefour : 50 minutes pour (essayer de) comprendre comment Carrefour France aggrège les TO de données quotidiennes des Carrefour à travers le monde.
Conclusion
On n’est pas habitués aux événements d’une journée (on participe surtout à des conférences sur 2 jours), on aime bien cet aspect concentré : il y a toujours plusieurs sujets intéressants sur chaque créneau.
On sent que ce “petit événement” devient grand : avec plus de 400 participants, une trentaine de speakers qui viennent des 4 coins de la France, mais aussi des locaux un peu surchargés par tout ce petit monde.
C’est une super nouvelle que ce genre d’événements apparaissent aux 4 coins de la France et réussissent à prendre de l’ampleur ! Un grand merci aux bénévoles et speakers !
Authors
Full-stack web developer at marmelab, Arnaud is a Software Engineer with a strong environmental conscience. He brews his own beer, which is a good way to prepare for the future.
Full-stack web developer at marmelab, Antoine can detect a one pixel shift in a web page. He is also passionate about basketball.