
Thumbless OS: What If AI Was Generating The UI?

TL;DR: We built a proof-of-concept of a new mobile OS based on a LLM, where the concept of application disappears and the UI adapts to the current task.
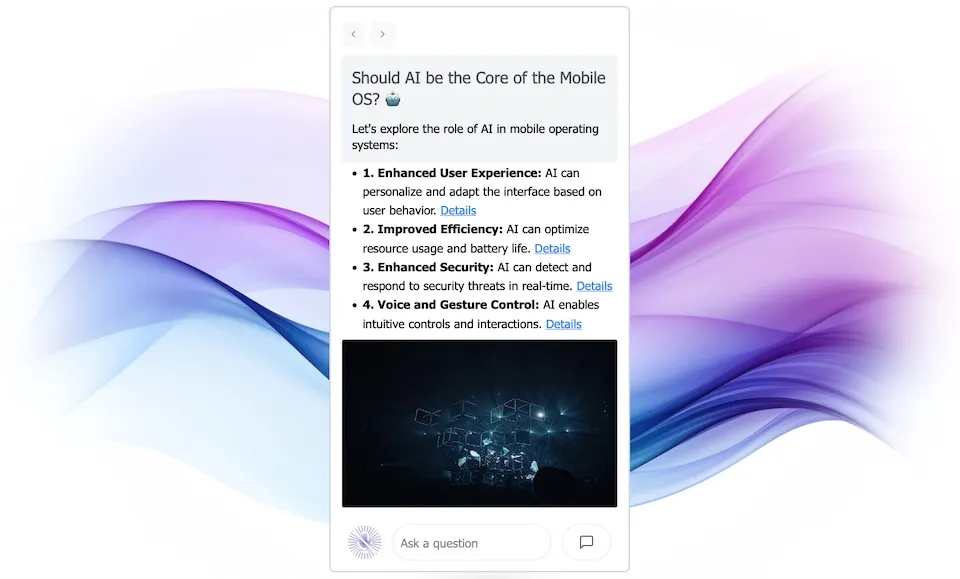
Here is a brief demo (turn on the sound):
YouTube might track you and we would rather have your consent before loading this video.
This is not another chatbot UI. The main differences are:
- The system uses the screen as a whiteboard to summarize the current answer and provide relevant actions
- The UI can include navigation links, images, emojis, and other rich content
- The user interacts with the system through voice or touch controls
- The system can adapt the UI to the task at hand, rather than being limited to a fixed set of screens
- The system can browse the web, search for information, and interact with other services
- The system capabilities can be expanded using MCP servers
Our prototype is called Thumbless OS. Read on to learn why we’ve built this, how it works, and what we learned in the process.
Applications: The Walled Gardens Of Computer Interaction
All computer systems today are built around the concept of applications. Example applications are email clients, media players, hotel booking systems, productivity tools, games, navigation software, social media platforms, and more. Each application is a self-contained environment with its own user interface, data, and functionality.
This model has served us well for decades, but it also has significant limitations. Users have to switch between different applications to accomplish their tasks. Applications that try to do too much end up being bloated and complex, while those that do too little are frustrating to use. Each application has its own user interface, which can lead to a steep learning curve and inconsistent experiences across different apps.
Recently, applications have gained AI superpowers. This made the problem more blatant. An AI assistant provided by a particular application can only help with tasks related to that application. For example, a calendar assistant can help you schedule a meeting, but it can’t help you book a train or a hotel for that meeting. It’s often frustrating, especially considering that the AI is capable of much more.
Maybe it’s time to reconsider the concept of applications altogether.
Putting AI At The Heart Of The System
LLMs can adapt to a wide range of tasks. The rise of AI assistants has shown that users are willing to interact with their devices in new ways, such as through voice or text.
But LLMs have strong limitations, too:
- they require a text or a voice interface,
- they are often verbose,
- they are not consistent,
- they are error-prone.
When using LLMs through a chatbot interface, users have to sift through long responses to find the information they need, and they often have to repeat themselves or rephrase their requests to get the desired result. In comparison with the Graphical User Interface (GUI) that we are used to, this is a step back.
But what if we could combine the best of both worlds? What if we could use LLMs to power the system, and let them build and render the user interface on the fly, adapting to the current task? This concept is called Generative UI.
Think of it as a teacher, who uses the whiteboard in the classroom to summarize the lesson and provide relevant examples. Except in this case, the whiteboard is interactive, allowing users to explore the information, take actions, and navigate through the system, using either voice commands or touch controls.
Such a system wouldn’t need the concept of applications. It could learn new capabilities on the fly, and adapt its user interface to the task at hand. It would open up new possibilities for interaction, turning our devices into powerful assistants that can help us with anything we need.
Prior Art
I know of two attempts to build such systems:
- Generative User Interfaces in Vercel AI SDK UI (open-source SDK)
- The T Phone concept by Deutsche Telekom (demo) (private, based on brain.ai’s Natural app)
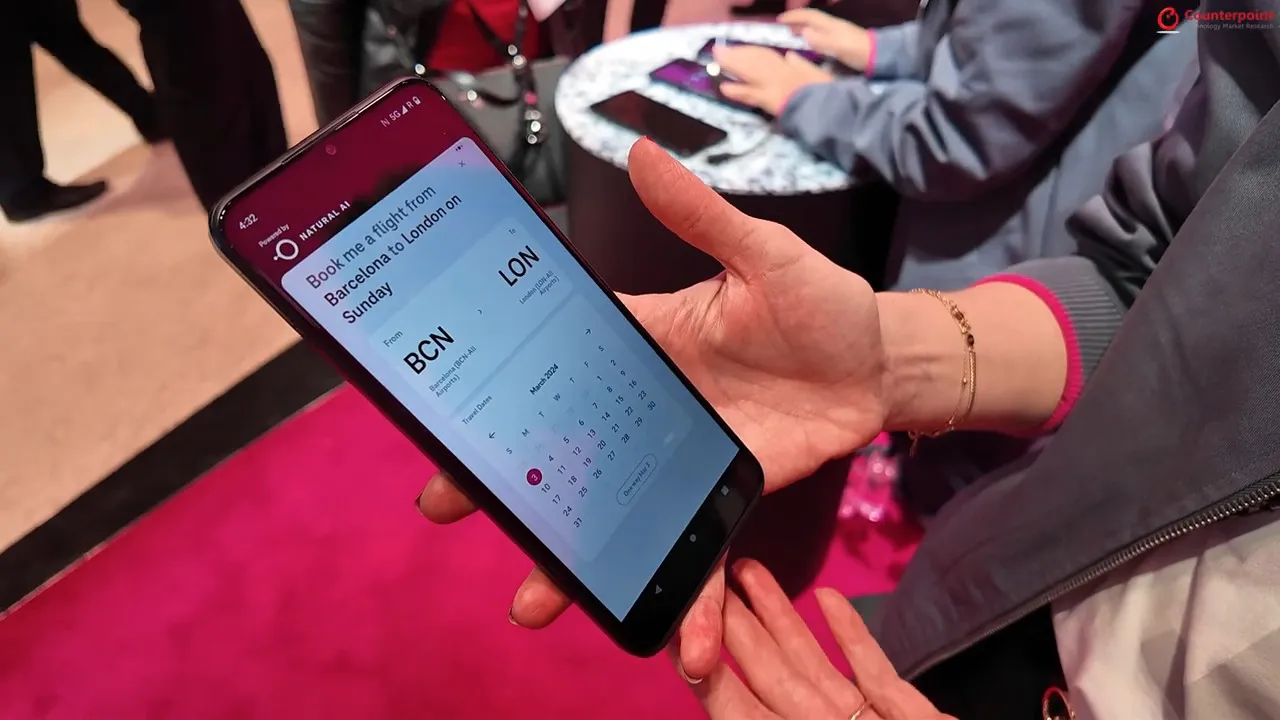
The user interface is richer than for a plain chatbot, but both solutions show the same limitation: The assistant can’t generate a screen that hasn’t been planned in advance by the developer. Ask a buying assistant to explain the concept of gravity, and it’ll fall back to text only. So these solutions don’t really break the barriers of the application concept.
Thumbless OS: A Proof-Of-Concept
We wanted to explore this idea further, so we built a proof-of-concept called Thumbless OS. Think of it as a mobile operating system that uses a large language model (LLM) as its core.
We’ve added one key tool to the LLM: the ability to render HTML on the screen. The LLM effectively treats the screen as a whiteboard it can draw on.
The HTML can use custom Tailwind CSS class names and emojis to make the content more engaging. Whenever the user interacts with the LLM, we include the current whiteboard HTML in the prompt, so that the LLM can modify the UI instead of replacing it entirely.
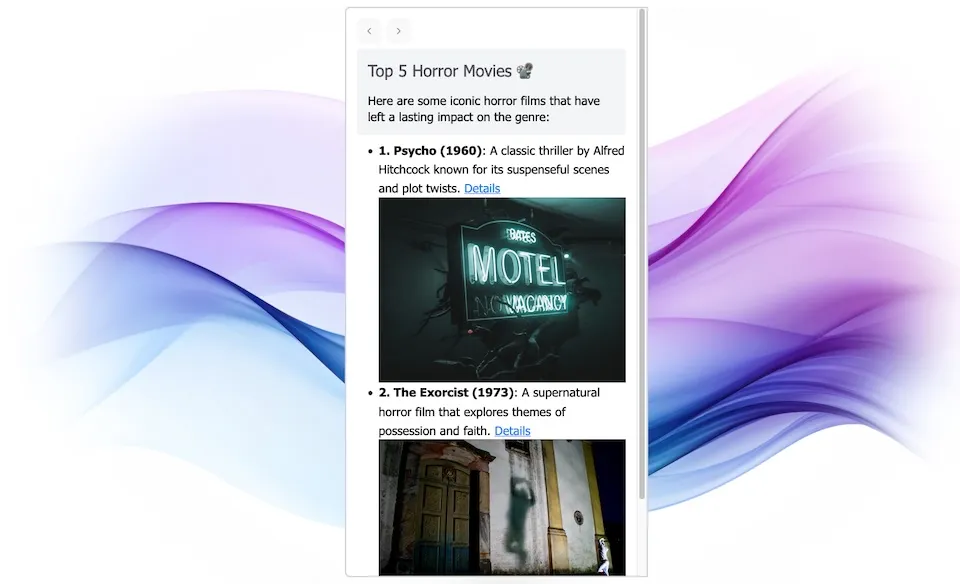
To improve the user interface and the capabilities of the assistant, we’ve added a few more tools:
- The ability to use hyperlinks to continue the conversation, so that users can navigate using their hands rather than their voice
- The ability to navigate in the conversation history using “back” and “forward” commands
- The ability to browse the web and search for information
- The ability to look for an image on the web and embed it in the HTML
- The ability to use a custom MCP server to extend the capabilities of the system
We’ve carefully designed the LLM prompt to let it use its superpowers to the fullest, while keeping the user interface simple and intuitive.
The code is open source and available on GitHub: marmelab/thumbless-os
What We Learned
Building Thumbless OS was quite a learning curve, showing us both the potential and the real problems with an AI-first operating system. Here’s what we found:
-
AI-Generated GUIs Are Too Simple: The UIs the LLM made were often basic. This isn’t a shock; good UI design is hard. Even the best LLMs can’t compete with a team of human experts, especially for structured content like calendars or product lists. Giving the AI example UIs might help, but it feels like we’d be bringing back the app concept we wanted to get rid of.
-
HTML Is A Complex Language For an LLM: When the LLM calls the “draw to whiteboard tool”, it passes some HTML code that is sometimes invalid. We’ve seen instances of
<ul></ul>tags before the<li>tags, and other similar issues. But using a simpler language, like Markdown, would limit the UI capabilities. We need a better way to let the LLM create rich UIs without overwhelming it with complexity. -
Static HTML Is Not Enough: The LLM-generated HTML is static and only supports basic interactions. It can’t handle dynamic content or user interactions beyond simple links. Users expect more from a modern OS, namely the ability to provide microinteractions and partial refreshes. This could be enabled by allowing the LLM to generate JavaScript code that the whiteboard would execute, but that’s too big a risk given the current state of LLM security.
-
LLMs are slow web servers: Asking the LLM to redraw the screen on each user interaction makes each interaction take a few seconds and harms the user experience. Using an embedded LLM could speed things up, especially where the network is slow.
-
Image Search/Generation is a must: Adding images to the whiteboard really improved the UX, but it slowed down the response (we’ve cut the demo video at the beginning of this article to skip the image query time). Our simple method (querying Unsplash with keywords) was inefficient and the results were just okay. Ideally, the OS should describe exactly the image it wants to display, and a specialized service would then provide that image, either from an image bank or through rapid AI generation (like Flux, under 0.5 seconds).
-
User Confirmation Breaks the Flow: Because LLMs aren’t perfectly reliable and an OS-level agent has so much power, we constantly had to ask users for confirmation. This turned into an endless “are you sure?” loop. Users quickly started clicking “yes” without reading, which defeats the purpose. Until AI is more reliable, no UI trick can fix this.
-
MCP Servers Are A True Universal API: By adding MCP servers, we managed to expand the OS’s capabilities significantly, without needing custom UIs for each function. Thumbless OS can now search and book movie tickets, comment on GitHub code changes, and manage daily appointments. However, the security implications aren’t fully addressed yet. Applications typically handle per-service user accounts, so coupling Thumbless OS with a user federation service like Keycloak might be a good idea.
-
One Model Leads to Inconsistent Results: Using a single, general model like
gpt-4o-mini-realtime-previewfor everything led to inconsistent behavior, especially when it had to choose from more than five tools. We realized we should probably split tasks: a smaller model to route requests via tools calling, and the main conversational model just for talking. This would make it more reliable. -
Developing Conversational Agents Is Frustrating: Hallucinations and the lack of reproducibility are a real pain for developers. Features that work one day might fail the next. This unreliability is a major roadblock for a true OS, especially one that handles personal data and takes actions for users.
-
Error Correction Is Essential: Even top AI APIs sometimes fail without warning. Their overall quality isn’t what we’re used to. So, any app using AI APIs needs a lot of safeguards to avoid crashing all the time. This slows down development.
In short, Thumbless OS showed us the exciting future of AI in operating systems, but also how much work is still needed in AI reliability, specialized models, and smart UI generation before it can become a reality.
Conclusion
Even though it has strong limitations and often fails, Thumbless OS feels like a real human assistant. During our tests, we were blown away by its ability to adapt to our needs, provide relevant information, and suggest actions.
We think this approach is a glimpse of what the future reserves us. If one day the reliability and hallucination concerns of LLMs are properly solved, this would easily replace the OS and all the apps we’re using today.
Perhaps that’s what like Jonathan Ive’s mysterious “io” product will look like. If so, this idea is worth billions ;)
Authors
Marmelab founder and CEO, passionate about web technologies, agile, sustainability, leadership, and open-source. Lead developer of react-admin, founder of GreenFrame.io, and regular speaker at tech conferences.