
We attended the first dot AI conference.

It’s the first time there’s a dot conference about AI. And since we always try to discover what’s behind new trends and technologies, we were there!
We already went to a few dot conferences, dotJs, dotScale but for those who don’t know how it works, the conference invites the best speakers of the field (their words) to talk about a subject of their choice.
Neural Networks as a Developer
Our first speaker was Lian Li, she is a developer at Datenfreunde. She mostly does AI on spare time and went through the same path as most developers, she learned AI by experimenting.
X might track you and we would rather have your consent before loading this tweet.
In her talk, she gave her feedback on how she built an AI for the now-famous game 2048.
She started from scratch with some deep learning using synaptic js without much result, and then started going towards reinforcement learning.
Reinforcement Learning algorithms work with just a few concepts:
- state of the game
- available actions
- a reward function for an action in a particular state
As an example, if you’re in the first state, the action ”⇩” should have a very negative reward, because it’s impossible. But on the second state, the action ”⇧” should have a very positive reward because it makes your score go from 84 to 116.


The reward can also be delayed in case we can’t know for sure if it’s a good or a bad move after every step. In this case, we can only know the actions were good ones when the game is over and we get the final score.
For her first Reinforcement Learning algorithm she chose to use reinforcejs to keep being on a js stack.
She developed it incrementally and, step by step, found out what was working better.
The reward function is very important, and implementing a naïve function like returning the score at the end does not work. It needs to be normalized, or it screws up the entire network.
It’s very important to find a good balance between exploration and exploitation. While training our model, most of the actions we try are the result of our neural network prediction. But we need to add a part of random actions for our AI to explore different paths than those it knows already or it will just find an acceptable solution and stop there, doing the same actions over and over again. Lian advised to decrease that randomness factor over time. A lot of exploration at first, then less and less over time.
Don’t stop at a single hidden layer. Even if reinforcejs is not made to build custom network architectures, we can add hidden layers and make results more accurate.
Even with all those tricks, she told us the results were better, but not all that good.
Real World Application for Neural Networks
Our second speaker, Pierre Gutierrez, works in the field and we felt it, his presentation was clearly headed to the initiated.
We discovered a use-case of image recognition through neural networks. He used image recognition to label images associated to travels. This generated data could then be used, alongside all the other data (destination, price, activities), to predict which travel the users were more prone to be interested in (and to buy).
The most important point probably was that to be useful to the real world, neural networks alone are not sufficient. They are nonetheless an important part of a global artificial intelligence strategy.
As to the most important piece of advice, always try to do transfer learning. What is transfer learning? Another scary word to explain a simple concept. Use existing and trained networks! Extend them and specify them for your own needs but don’t start from scratch. He mentionned Caffe Model Zoo for that use.
Neural Networks Everywhere
Yufeng Guo, who is a developer advocate for machine learning at Google, talked about TensorFlow and more specifically how we can use neural networks on mobile devices.
We’re not talking about training models on the mobile device, but actually using a trained model there, even offline!
TensorFlow allows this, and he showed us a very simple app were it would recognize his favorite chocolate bars through the camera of his phone, even with airplane mode activated.
This probably is the most interesting part of neural network. While training is long, hard and complicated, prediction consists of basic operations and is quite fast.
To go further, we could think of a progressive web app. The service workers would allow to use the neural network even offline. And when back online, keep the trained model updated to its latest version so it’s always as accurate as possible, without needing any server for execution.
Google translate app does exactly that.
More Image Recognition
Charles Ollion talked to us about how they use neural network at Heuritech.
Their business: Recognizing clothes or accessories that are worn on pictures. It could be a Dior handbag or Levis Jeans.
He explained that he combined many steps in order to reach what they expected.
We could think that a simple convolution over the entire image could fit the use case, but for a very precise detection it doesn’t. Imagine you need to recognize the brand of the handbag with all the “noise” added by the surroundings, it’s almost impossible.
They needed to stack up different neural network models. The first one is to use classification and localization networks to predict what objects are and where they are on the image: results in a bounding box around objects. (Faster R-CNN)
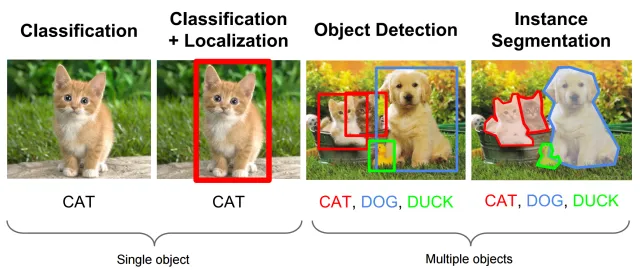
The second one is to detect objects and segment them, it’s all about knowing exactly where objects are. (Mask R-CNN)
The point is to identify which objects are on the picture, and extract all of them into other smaller pictures without background.
Here, neural networks are used to enrich and improve the initial data. They reduce the scope by removing all meaningless data, and make it possible for a conventional neural network to guess the right things (labels).
Neural Networks in the Physical World
Then we had Laurent Smadja talking, he’s the Perception Team Research Advisor at Navya. He cares about recognizing things on images! Yes, more image recognition.
You know Navya, it was probably the most well known French tech company at the CES this year. They build self-driving shuttles for specific needs. He told us they were mostly used for venues or for factories…

He briefly explained the history of neural networks and summed it up by saying that the concept behind what we know today was already there 80 years ago. We just didn’t have the computing power or the training data needed for it to work.
Computing issues have mostly been solved by using GPUs instead of CPUs. It needs some more technical engineering in a car than in a datacenter, especially because of legislation, but that’s about it.
Data is mostly held by GAFAs and fed by you and me, everyone using any technology service, phone, television, computer is feeding data. We can say it’s mostly obtained with some kind of crowd sourcing.
Knowing that the future of AI depends mostly on the data makes me realize that GAFAs have a tremendous power on the AI field. They have it all, computing power and a hell of a lot of training data on every subject.
Neural Networks in Space
Mathias Ortner, gave us feedbacks on how they use neural networks at Airbus defense & space.
Their work is to capture images from satellites and sell them, but they have to detect images worth selling. As you could guess, those images are HUGE, and manual checking is just impossible !
Which images are not worth selling ? Well if there are clouds passing in front of the camera! And it can be tricky, even for the human eye, to know the difference between a cloud and a snowy mountain.


He explained that as a data scientist, his everyday job is to train many and many neural networks with different configurations, and to keep those with the best results. Some kind of A/B testing or genetic selection.
Things are moving so fast we need to be able to change easily
He explained that there’s no final model and there will never be, training data is always changing, so are neural network models, new research papers come and go everyday.
And it’s most likely only the start.
How Does It Work ?
Arnaud Bergeron, core contributor of Theano showed us how to implement specific operations to be executed on particular GPU, through CUDA or OpenCL.
To be honest, I didn’t understand much as he really went into the details of the implementation.
It was still interesting to have a sight at how the inner mechanisms work but I’m not sure it will ever be useful to me.
Embedding
Olivier Grisel, contributor of scikit-learn talked about neural networks for recommender systems.
The most important point was that our data isn’t always as predictible as expected. For a recommender system, the informations about how our user behaves might look really different from one to another. If the data size changes, the inner structure of the neural network is supposed to change as well.
For that part, he showed us how embedding could be used. Embedding - as I understood it - allows to take length-variable inputs and encode them into a continuous vector space, which becomes our neural network input.
Conclusion
Ok, we got it, neural networks can do image recognition rather well, there are tutorials everywhere about it. What I expected to be covered are the other fields neural networks could be applied to.
I got half the answer in the term that combining image recognition data with other data, and methodologies, can lead to really efficient artificial intelligence.
When we try to apply neural networks to solve different problems, like Lian Li with her 2048, or us trying with connect four and awale, it’s still pretty inefficient. How did Google do with AlphaGo ? We don’t quite know.
My feeling is that neural networks are still a field where intuition and experimentation are essential. It makes it hard to get into if you’re not a data scientist.
About dot AI itself, for a first edition, it definitely was a success: the venue was great, the talks were qualitative, and the breaks allowed to share our small experience with all the other attendees around a good coffee and some muffins. Thanks to the organizers for making such an enjoyable conference!
Authors
Facilitator at marmelab, Florian also gives lectures to IT students. He's a biker, plays the guitar, and brews his own beer.