
Dive Into GraphQL Part I: What's Wrong With REST?

This is the first post in the Dive Into GraphQL Series. Surprisingly, this post will not talk about GraphQL itself, but about the problems it solves. And they mostly boil down to REST.
Update 25/09/17: Fix inaccuracies in the way multiple HTTP requests affect browser performance, and missing HTTP/2 mention.
REST Unlocked API Centric Architectures
First, nothing is wrong with REST per se. REST was a perfectly valid solution to the problem of building API centric architectures. Before REST, exposing a (SOAP) web service required complex tooling, hours of configuration, and a very large manual. And consuming such a web service required proprietary SDKs, resource intensive preparation and validation, and a very large manual, too. At the time, consuming a web service from a browser wasn’t even conceivable (think parsing XML WSDL with JavaScript) except for Microsoft.
REST, invented in 2000 and popularized in 2007, shined because of its simple syntax. REST made requests and responses easy to build and parse, which is why frontend and backend developers around the world adopted it quickly. REST was also stateless and cacheable, which made scaling a piece of cake. It worked so well that today, API centric architectures are everywhere, and REST is the tooling of choice.
But the world has changed since 2007. And the few shortcomings of REST, which were a good trade-off back then, are now a big pain for productivity, performance, and maintainability.
Let’s see why.
The Internet is Now Mobile
In 2015, Google announced that for the first time, it had received more searches from mobile devices than from desktop. Since then, mobile Internet consumption has progressed steadily as developing countries jumped on the mobile Internet bandwagon, skipping cable connection altogether. So let’s face it: the web apps that we’re building today will be mostly used on mobile devices, and not on WiFi.
Mobile devices over 4G or 3G are slower than on WiFi, because the latency overhead of radio communication oscillates between 100ms and 600ms on 4G (up to 3500ms on 3G), and also because the quality of mobile connections varies a lot, which affects throughput in addition to latency.
For a single HTTP request, the response time dangerously approaches 1 second, which is the user’s flow of thoughts limit according to UX expert Jakob Nielsen. That means that the maximum number of HTTP requests a mobile app can make without losing the user’s attention is one.

Let’s not forget battery life. Radio communications are power hungry, so mobile devices turn off the device radio as soon as possible, losing the channel they had established with the radio tower. To make a new HTTP request, a mobile device must wake up the radio, and request some bandwidth to the radio tower. This can drain the battery pretty quickly if app designers don’t count their HTTP requests.
API-centric applications particularly suffer from latency and battery life on mobile, because they query their REST backend like crazy.
Service-Oriented Architectures Suck (for Clients)
Imagine a Twitter-like mobile application using a REST API for backend. Let’s list the resources the application must fetch to display the main page:
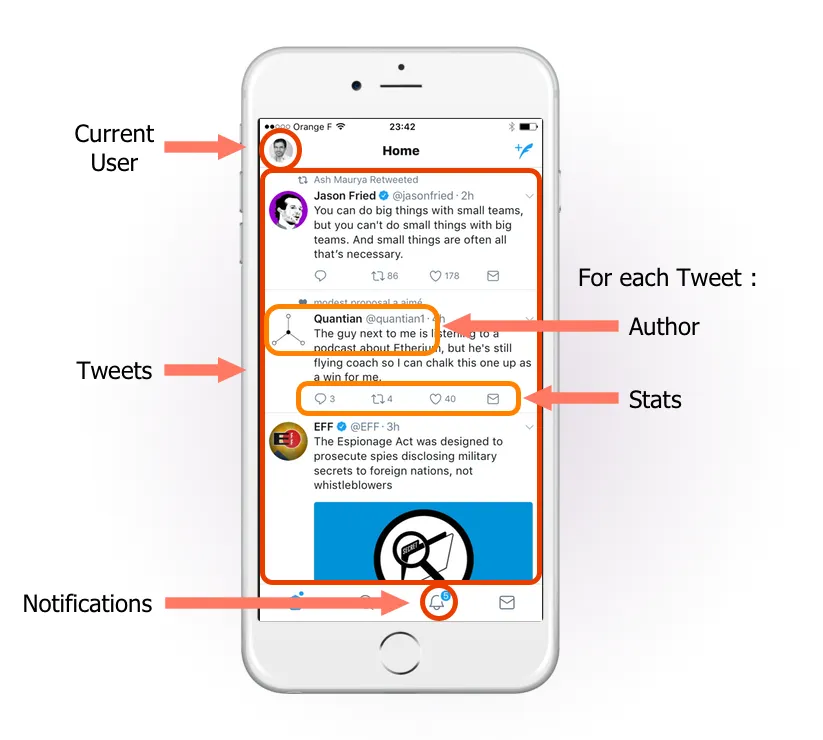
REST backends expose one resource per endpoint. So the mobile app must send requests to several endpoints:
GET /userto grab the current user name and avatarGET /notificationsto get the number of unread notificationsGET /tweetsto get the list of the latest 20 tweetsGET /users?ids=[123,456,789,...]to get the profile of the authors of the latest 20 tweetsGET /tweet_stats?ids=[123,456,789,...]to get the stats of the latest 20 tweetsPOST /viewsto send the view stats for the tweets displayed on screen
That’s 6 HTTP requests - not even counting the requests for the avatar images, or the embedded media. Request 4 and 5 must wait the return from request 3. So that simple page will require more than 1 second to grab the data it needs, even though mobile browsers can make between 4 and 6 concurrent HTTP requests.
Besides, web and mobile apps tend to use more than one service provider (understand: more than one HTTP domain). It’s very common to see applications rely on different REST providers for authentication, avatars, comments, analytics, etc. The latency problem becomes even more painful in this case, because each new domain requires a specific DNS lookup, and the HTTP client can’t share keepalive connections between domains.
To summarize, the main downside of REST is that it makes clients slow by default, especially on mobile.
Grouping Requests Requires Work
One solution is called data inclusion. The idea is to request several related resources from one single endpoint, hoping the server knows the relationship between the two. Something like:
GET /tweets?include=authors,stats
This allows to merge requests 3, 4 and 5, but that’s all. Data inclusion doesn’t allow to request aggregates of unrelated data (like tweets and notifications).
In 2013, Facebook introduced another solution. They called it the Batch endpoint. It’s a REST endpoint where you can send several sub-requests in the batch query parameter:
curl \ -F 'access_token=...' \ -F 'batch=[{"method":"GET", "relative_url":"me"},{"method":"GET", "relative_url":"me/friends?limit=50"}]' \ https://graph.facebook.comInternally, the Facebook server queries their data stores, and groups the results into a single JSON response:
[ { "code": 200, "headers":[ { "name": "Content-Type", "value": "text/javascript; charset=UTF-8" } ], "body": "{\"id\":\"…\"}"}, { "code": 200, "headers":[ { "name":"Content-Type", "value":"text/javascript; charset=UTF-8"} ], "body":"{\"data\": [{…}]}}]For purists, this batch endpoint is not RESTful at all, since it doesn’t really expose a resource. In addition, it doesn’t work when you need to pipe the response of one call (e.g. the list of tweets) to another one (the tweet authors profiles).
Lastly, implementing the batch endpoint strategy takes time. It’s basically like developing a proxy server. I know it because marmelab has developed a Node.js middleware that does just that, called koa-multifetch. That’s a component that every application developer should include in their REST server in order to reach a decent level of performance. That’s why developing a fast mobile app is so expensive.
No Standard Means Too Many Standards
REST is not a standard, it’s an architectural style, a set of loose principles. These principles leave a lot of latitude to developers for implementation. For instance, the recommended HTTP response code for a DELETE request can be either 200 or 204. As for pagination, you can use either a page query parameter, a Content-Range header, or, why not, limit and offset. The lack of unique REST standard for queries and responses caused the explosion of REST standards: Open API, OData, Hydra, JSend, etc.

When you need to query a web service, you can’t just use a standard REST client, because there is no such thing as a standard REST client. You must either build a custom REST client from scratch, or tweak a highly configurable and highly complex general purpose REST client. Either way, this takes time. And when you need to develop a web service backend, you can’t just use the REST framework for your language. You must first spend a week in discussions with all the developers and software architects around you, and try to decide which REST flavor you should use. Oh, and don’t get me started on content type negotiation or HATEOAS.
The open-source boom has only accelerated the trend: Today, if you need a REST library, you have to choose from a heck of a lot of options. For JavaScript alone, there are over 900 rest client npm packages.
So yes, freedom leads to diversity, but in the case of data communications over the Internet, diversity means waste. The lack of REST standard impacts the speed of development a great deal.
Frontend And Backend Developers Need A Contract
REST doesn’t have the notion of schema, a contract that describes exactly what a web service is supposed to return. Just like with standards above, the absence of schema leads to the multiplicity of possible documentation formats: JSON Schema, RAML, Swagger, etc.
In many companies, backend developers still use a Word document to describe the resources and fields of their API. There are so many things to describe in an API contract that hand-made specifications are often incomplete. They lack description of error cases, data types, boundaries for arguments, etc. And they take ages to write, so they are always outdated.
The thing is, without a clear contract describing the API, frontend and backend developers must make assumptions until they plug their components together. The more assumptions they make, the longer the integration phase lasts.
The absence of a single schema in REST causes delays in development and frustration to developers.
Agile Leads To Bloated Response
APIs tend to change over time. But if the server API changes, all the consumers break.
The usual solution is called versioning: the server exposes several versions of the web service, and for a given version, the API never changes. Of course, there is no standard for REST versioning, but we’ve already talked about that. As for the service consumers, they should be informed about the new release, and spend time updating their API calls.
However, Agile software development leads to shorter release cycles. These days, a popular web service can easily change several times a month. Asking developers to change the code of their service consumers so often is not an option.
That’s why some APIs don’t use versioning but evolution instead. The idea is to never remove or modify a field in a resource response, but always add a new field instead. For instance, imagine that you’ve developed the response for a GET /users/:id request as follows:
{ "id": 123, "name": "John Doe"}Then a Product Manager comes and asks for the ability to display middle names on tablets - but we still need to display the same name as before on mobile. No problem, just add a new field:
{ "id": 123, "name": "John Doe", "full_name": "John W. Doe"}Until a new Product Manager (they change every 6 months) changes the UI completely in order to support name suffix, because the new boss insists on being called Edwin Denison Lowell, III. As the end users will upgrade their apps gradually, it’s important to support the previous name format, too. OK, let’s add more fields.
{ "id": 123, "name": "John Doe", "full_name": "John W. Doe", "full_full_name": "John W. Doe Sr."}You get the idea.

The problem is that the longer a web service lives, the larger the resources become. In the Twitter API, a tweet consists of more than 30 fields, most of which you don’t need if you want to display the top tweets about your company on a TV set in your meeting room.
But REST only contains the notion of resource - there is no notion of fields that you could use to, for instance, restrict the response to only the details you need. Attempts at mitigating this (sparse fieldsets, partial responses) exist, but they’re always optional. The default rule in REST is to require an entire resource, with all the fields. So REST web services become slower and slower over time, because their responses become heavier and heavier.
HTTP CRUD Only
REST is modeled after HTTP. It uses the HTTP verbs (GET, POST, PUT, etc.), requires HTTP transport, and suffers from the same performance and security problems as HTTP. Even if Roy Fielding’s original REST paper describes REST as protocol agnostic, REST is de facto HTTP only.
Also, most of the discussions about REST describe CRUD (Create, Retrieve, Update, Delete) interactions only. For other communication scenarios (file upload, commands, remote procedure call, etc), you’re on your own.

For instance, many modern apps require real-time updates. HTTP communication is based on a request and a response, it’s not designed to push updates without any request. Consequently, addressing the Publish/Subscribe scenario in REST requires a rather hacky approach:
- Client A sends a
GET /eventsrequest to a central server every 10 seconds or so. - One day, client B sends a
POST /eventsrequest to the central server, with an event in the body - Next time client A sends a
GET /eventsrequest to the central server, it receives the event emitted by client B
What a waste of resources (especially on mobile)! The only solution in HTTP REST land is to turn client A into a server:
- Server A sends a
POST /subscriptionsrequest to the central server, with a callback URL ofhttp://serverA.com/remote_eventsas parameter. - client B sends a
POST /eventsrequest to the central server, with an event in the body. - The central server sends a
POST /remote_eventsto server A, with the event in the body.
But how do you do that if client A is a mobile device? Does that imply turning every smartphone into a web server? It’s not a viable solution.
Modern protocols like WebSockets or HTTP/2 solve one part of the problem (the protocol), but they don’t specify the data exchange format to use. And REST feels out of place for Pub/sub with these protocols. For instance, WebSockets doesn’t have the notion of verb like HTTP - just messages. As a result, applications often use other architectures (like WAMP) in addition to REST to handle these scenarios.
The Solution(s)
To summarize, the REST architecture makes applications slow, harder and more expensive to develop, and too limited in functionality. These problems are real. Many companies suffer from REST, and many have tried to find a better alternative.
Maybe we can patch REST by adding all that it lacks: HTTP/2 for request multiplexing, batch endpoints, sparse fieldset selectors, schemas, Swagger documentation, etc. There are entire frameworks like API platform dedicated to this task. My opinion is that it’s like trying to eat soup with a fork. You may manage to do it eventually, but is it really a good idea? I consider that REST doesn’t really match modern web apps requirements. And that’s unfortunate, given how much Marmelab, my company, has invested into REST.
Why not use SQL over HTTP? SQL has UNION, JOIN, HAVING, GROUP BY, and it’s standardized. Queries are validated against a database schema. But SQL restricts the possible actions to SELECT, CREATE, UPDATE, and DELETE, so it’s still too limited in terms of use cases. SQL also has a strong relational bias, which makes is far from ideal to query document or graph databases. But let’s keep the idea of using a declarative query language.
If you think you can address the limited functionality shortcoming by using plain old Remote Procedure Call (RPC), you’re on the right track. But the risk is to fall back to SOAP, and nobody wants to fall into the pit of utmost complexity again.

Google invented Protocol Buffers to address the performance and schema pain points, and made it public in 2008. It’s a language-neutral, platform-neutral extensible mechanism for serializing structured data. That’s a good solution, but it does not address the problem of complex queries and aggregations. Nor does Apache Thrift, another binary protocol for RPC.
Much closer to the holy grail is Falcor, open-sourced by Netflix in mid-2015. Falcor is both a server middleware and a client SDK. But it’s a tool, not an architecture. And it’s JavaScript-only; if you’re doing Objective-C or Kotlin, you’re out of luck. Falcor doesn’t offer a schema and static types, and it lacks a powerful query language.
Conclusion
There must be a better way. What we really need is to replace REST with a new architecture that allows to:
- Query aggregates of resources (e.g. tweets and profile, in one round trip), even from different domains
- Query an explicit list of fields, never a complete resource
- Provide a schema describing the syntax of the request and response
- Be a standard, but not too tied to the HTTP protocol
- Support Publish/Subscribe scenarios out of the box
- Shift the emphasis from the server to the client.
I believe that an innovative tool recently published by Facebook solves this problem (hint: it starts with a G). Read the next post in this series to discover what it looks like.

If you want to read more on the subject by other authors, I recommend the following articles:
- From REST to GraphQL, by Jacob Gillespie
- GraphQL IS The Better REST, by the GraphCool team
- GraphQL vs. REST, by the Apollo team
- REST APIs are REST-in-Peace APIs, by Samer Buna
Authors
Marmelab founder and CEO, passionate about web technologies, agile, sustainability, leadership, and open-source. Lead developer of react-admin, founder of GreenFrame.io, and regular speaker at tech conferences.