Dive Into GraphQL Part II: Anatomy of a GraphQL Query

In the first post of the Dive Into GraphQL Series, I’ve explained why REST isn’t such a good fit for today’s web and mobile applications. REST makes applications slow, harder and more expensive to develop, and too limited in functionality. We need a new hero, an architecture that allows to:
- Query aggregates of resources (e.g. tweets and profile, in one round trip), even from different domains
- Query an explicit list of fields, never a complete resource
- Provide a schema describing the syntax of the request and response
- Be a standard, but not too tied to the HTTP protocol
- Support Publish/Subscribe scenarios out of the box
- Shift the emphasis from the server to the client.
My conviction is that GraphQL, a query language invented by Facebook, is a great candidate. This conviction is based on several months of development with GraphQL, and is shared by many developers at Marmelab. I’ll explain what GraphQL is in this post.
But first, let’s bust a few misconceptions about GraphQL.
What GraphQL Is Not
First and foremost, GraphQL is not a query language for graph databases. That would be Gremlin. There is a concept of graph in GraphQL, but learners don’t understand it until they’re halfway through the docs (and I’ll explain it in the next post). In the meantime, many curious developers give up, thinking this doesn’t concern them if they use a relational or a document database.
So in my opinion, GraphQL’s biggest flaw is its name. Any other name would have been better, like, why not, “Caramel”. Not that it can’t happen to anybody else: I named “admin-on-rest” a React library that can work with any REST or GraphQL backend. So let’s make that clear: GraphQL works with any database - relational, key/value store, document, and graph. You can even use it in front of a REST API.

GraphQL is not a React library, it is not even just a JavaScript library. I know, most of the tutorials you’ll find about GraphQL use JavaScript, but it’s only because JS developers tend to write a lot of code, so they want to share it (pun intended). GraphQL is a specification, with implementations in many languages. You can use GraphQL on the client side in JS, Objective-C or Java. You can use GraphQL on the server side in JS, Go, Python, Ruby, PHP, etc.
GraphQL is not a transport protocol. You can use GraphQL with any transport - HTTP, WebSockets, you can even send GraphQL queries as text files by Bittorrent if you feel like. That makes it different from REST, which is tied to the HTTP protocol, and built on the HTTP grammar (GET, POST, PUT, etc.).
Following on from that idea, GraphQL doesn’t deal with authentication, authorization, compression, caching, content negotiation, etc. That’s your responsibility.
GraphQL intentionally doesn’t include built-in filtering, sorting, computations, or joins. You carefully design all of those yourself to fit the needs of the API consumer, just like REST.
Your First GraphQL Query
Now, instead of describing what GraphQL is, let’s look at what it does in comparison with REST. For instance, requesting a single tweet from an API usually looks like the following in REST:
----------------------------------- request GET /tweets/123 HTTP 1.1 Host: http://rest.acme.com/ ----------------------------------- response HTTP/1.1 200 OK Content-Type: application/json { "id:" 123, "body": "Lorem Ipsum dolor sit amet", "user_id": 456, "views": 45, "date": "2017-07-14T12:44:17.449Z" // etc. }In GraphQL over HTTP, the equivalent would be:
----------------------------------- request POST / HTTP 1.1 Host: http://graphql.acme.com/ Content-Type: application/graphql { Tweet(id: 123) { id body date } } ----------------------------------- response HTTP/1.1 200 OK Content-Type: application/json { "data": { "Tweet": { "id:" "123", "body": "Lorem Ipsum dolor sit amet", "date": "2017-07-14T12:44:17.449Z" } } }There are several things to note from this example:
- In REST, the API exposes one endpoint per resource (
/tweetsis such an endpoint), while in GraphQL, there is a single endpoint for the entire API (/in the example) - Just like REST, the body of a GraphQL response is a JSON object. However, the format of the response is normalized, and the content is always available under a
datakey. - In GraphQL, parameters are passed between parentheses (here:
(id: 123)) and inside the query. - In REST, you ask for a complete resource, while in GraphQL, you have to explicitly list the fields you want (
id,body, anddatein this example). - GraphQL queries use a special query language called… graphql. It looks like JSON but not really. We’ll see that very soon.
- The GraphQL request uses a special content type
application/graphql - Unlike REST, GraphQL isn’t tied to HTTP semantics. To read a resource, GraphQL uses a
POSTHTTP request.

If you’re a die hard REST fan, this last point will probably make you cringe. What, using POST to read a resource? Isn’t it as criminal as drowning kittens? Here is worse for you: In GraphQL, you can also use GET to make the same query if you feel like:
----------------------------------- request GET /?query=query%20%7B%20Tweet(id%3A%20123)%20%7Bid%20body%20date%20%7D%7D Host: http://graphql.acme.com/ ----------------------------------- response HTTP/1.1 200 OK Content-Type: application/json { "data": { "Tweet": { "id:" "123", "body": "Lorem Ipsum dolor sit amet", "date": "2017-07-14T12:44:17.449Z" } } }```
If you feel shocked, please bear with me. In a few minutes, you'll see how great an idea that is. So yes, GraphQL servers usually don't care about the HTTP verb. It's more common to use `POST` for everything (read and write queries) because it's more readable in tutorials. As explained earlier, you don't even have to use HTTP at all to communicate with a GraphQL server.
As a side note, you can see with the `GET` request that newlines and tabulations aren't significant in graphql queries.
## GraphQL is Remote Procedure Call, Not Resource-Based
In [the previous post](/blog/2017/09/04/dive-into-graphql-part-i-what-s-wrong-with-rest.html), I introduced the use case of the mobile Twitter home page:
<Image src={Media_1a0c25ac} alt="Mobile Twitter" class="responsive"/>
To render this page, the application needs to read the 10 latest tweets, not just one. Here is how you would do it in REST:
```plaintext ----------------------------------- request GET /tweets/?limit=10&sortField=date&sortOrder=DESC HTTP 1.1 Host: http://rest.acme.com/ ----------------------------------- response HTTP/1.1 200 OK Content-Type: application/json [ { "id:" 752, "body": "consectetur adipisicing elit", "user_id": 249, "views": 12, "date": "2017-07-15T13:17:42.772Z", // etc. }, { "id:" 123, "body": "Lorem Ipsum dolor sit amet", "user_id": 456, "views": 45, "date": "2017-07-14T12:44:17.449Z" // etc. }, // etc. ]```
In GraphQL, just like you called the `Tweet` query to get one tweet, you usually call the `Tweets` query to get several tweets. But then again, you need to list the fields you want to appear in the response:
```plaintext ----------------------------------- request POST / HTTP 1.1 Host: http://graphql.acme.com/ Content-Type: application/graphql { Tweets(limit: 10, sortField: "date", sortOrder: "DESC") { id body date } } ----------------------------------- response HTTP/1.1 200 OK Content-Type: application/json { "data": { "Tweets": [ { "id": "752", "body": "consectetur adipisicing elit", "date": "2017-07-15T13:17:42.772Z", }, { "id": "123", "body": "Lorem Ipsum dolor sit amet", "date": "2017-07-14T12:44:17.449Z" }, // etc. ] } }```
`Tweet` and `Tweets` are query names, defined by the server. As a matter of fact, GraphQL is at its core a Remote Procedure Call (RPC) language: it lets the client call procedures (queries) on the server. That means it's absolutely not limited to CRUD (Create, Retrieve, Update, Delete) scenarios.
I should warn you though: There is no convention for _naming_ queries. Some GraphQL servers will use `Tweets` for a list of tweets, others may use `allTweets`, others `getTweetPage`, etc. I know that [naming things is one of the two hard things in computer science](https://martinfowler.com/bliki/TwoHardThings.html), but I still regret that the GraphQL spec didn't take a step further.
## Aggregates
You may wonder why the GraphQL response contains a `Tweets` key in the response, instead of putting the list of tweets directly under `"data"`. Well, that's because you can query for several resources at the same time - in a single round trip:
```plaintext ----------------------------------- request POST / HTTP 1.1 Host: http://graphql.acme.com/ Content-Type: application/graphql { Tweets(limit: 10, sortField: "date", sortOrder: "DESC") { id body date } User { full_name } NotificationsMeta { count } } ----------------------------------- response HTTP/1.1 200 OK Content-Type: application/json { "data": { "Tweets": [ { "id": "752", "body": "consectetur adipisicing elit", "date": "2017-07-15T13:17:42.772Z", }, { "id": "123", "body": "Lorem Ipsum dolor sit amet", "date": "2017-07-14T12:44:17.449Z" }, // etc. ], "User": { full_name: "John Doe" }, "NotificationsMeta": { count: 12 } } }```
In addition to the `Tweets`, I called the `User` query to get the details about the connected user, and the `NotificationsMeta` query to get the number of pending notifications. GraphQL lets me aggregate several queries into one HTTP request.
<Image src={Media_6f67bf3f} alt="Road Train" class="responsive"/>
There is still one thing missing, though: the author's name and avatar for each tweet. In REST, you'd have to wait for the response to the first query to get the `user_id` for each tweet, then query the `/users` endpoint with these ids. This would block the rendering of the page until the second response has returned. In GraphQL, you can query the author directly in the tweet:
```plaintext ----------------------------------- request POST / HTTP 1.1 Host: http://graphql.acme.com/ Content-Type: application/graphql { Tweets(limit: 10, sortField: "date", sortOrder: "DESC") { id body date Author { username full_name avatar_url } } User { full_name } NotificationsMeta { count } } ----------------------------------- response HTTP/1.1 200 OK Content-Type: application/json { "data": { "Tweets": [ { "id": "752", "body": "consectetur adipisicing elit", "date": "2017-07-15T13:17:42.772Z", "Author": { "username": "alang", "full_name": "Adrian Lang", "avatar_url": "http://avatar.acme.com/02ac660cdda7a52556faf332e80de6d8" } }, { "id": "123", "body": "Lorem Ipsum dolor sit amet", "date": "2017-07-14T12:44:17.449Z", "Author": { "username": "creilly17", "full_name": "Carole Reilly", "avatar_url": "http://avatar.acme.com/5be5ce9aba93c62ea7dcdc8abdd0b26b" } }, // etc. ], "User": { full_name: "John Doe" }, "NotificationsMeta": { count: 12 } } }```
So GraphQL allows you to group many queries into one, including queries for related resources. That way, you can always get all the data you need for a screen in a single request. Indeed, the last query is enough to render the entire Twitter home page in one roundtrip. Mission accomplished!
<div class="tips">
If you're wondering how a GraphQL server works, [the third post in this series](/blog/2017/09/06/dive-into-graphql-part-iii-building-a-graphql-server-with-nodejs.html) will answer your questions. It's a tutorial for building a GraphQL server for a Twitter app. For now, please consider that the server already exists, and free your mind from these server-side considerations.
</div>
## Introspecting a GraphQL Server
Wait, how did I know that I could call the `Tweets`, `User`, and `NotificationsMeta` queries on the server? I mean, apart from the fact that I'm actually writing this tutorial? To put it otherwise, how do I, a frontend developer, know which queries, and which fields in each query, I can call on a GraphQL backend?
<Image src={Media_3b160043} alt="We need a map! Photo by rawpixel.com on Unsplash" class="responsive"/>
GraphQL answers that requirement by exposing a map of the queries. Every GraphQL server can answer a special query called `__schema` - it's called the _introspection_ query. It's not a [particularly readable query](https://gist.github.com/craigbeck/b90915d49fda19d5b2b17ead14dcd6da), and you never write it by hand anyway (all GraphQL clients can do introspection in one command), so let's look at the result of this query instead: it's the server _schema_. For my example Twitter API server, the GraphQL schema looks like this:
```graphql# entry pointstype Query { Tweet(id: ID!): Tweet Tweets(limit: Int, sortField: String, sortOrder: String): [Tweet] TweetsMeta: Meta User: User Notifications(limit: Int): [Notification] NotificationsMeta: Meta}
type Mutation { createTweet(body: String): Tweet deleteTweet(id: ID!): Tweet markTweetRead(id: ID!): Boolean}
type Subscription { tweetPublished(userId: ID!): Tweet}
# custom typestype Tweet { id: ID! # The tweet text. No more than 140 characters! body: String # When the tweet was published date: Date # Who published the tweet Author: User # Views, retweets, likes, etc Stats: Stat}
type User { id: ID! username: String first_name: String last_name: String full_name: String name: String @deprecated avatar_url: Url}
type Stat { views: Int likes: Int retweets: Int responses: Int}
type Notification { id: ID date: Date type: String}
type Meta { count: Int}
# custom scalar typesscalar Urlscalar DateWhoa, this server exposes a lot of things! At a glance, I can tell by reading the schema that:
- I can read data about tweets, users and notifications (the
type Querylists the read entry points) - I can create and delete tweets, and mark one as read (the
type Mutationlists the write entry points) - I can subscribe to new tweets published for a given user (the
type Subscriptionlists the pub/sub entry points)
Each of these entry points have a return type, and the schema lists the available fields for all these types. So for instance, the Tweets query returns a list of records of the Tweet type, which exposes id, body, date, Author, and Stats fields. These fields are also typed, either with a scalar type (Int, String, or ID, which is like a String), or with a custom type (User and Stat), for which I can also see the available fields.
A GraphQL schema is like the Swagger of REST APIs. It contains all you need to know to interact with the server.
In practice, and unlike in this article, development in GraphQL is schema-first. Frontend and backend developers start by agreeing on a schema. They define the contract between the frontend and the backend. Then, each team develops their own part, without any surprise. You’ll see how that works in the next post in this series.
Note: GraphQL recommends using the ID type for primary keys. That means that GraphQL expects record to be identified by a string. This also explains why, in the GraphQL results above, the Tweet.id field has string values even though the values are numeric.
Note: You may have noticed the scalar Date declaration. It’s a type declaration that most schemas contain, because the GraphQL specification doesn’t define a Date type by default!
GraphQL is a Declarative Query Language
You probably noticed that the schema syntax looks a lot like the query syntax. That’s because it’s the same. This JSON-like, comma-free, no-semicolon language is called the graphql language. It’s used to describe types, queries, mutations, fragments, subscriptions. There is an entire website dedicated to it, but you’ve already learned the basics:
- GraphQL provides built-in scalar types for
String,Int,Float,Boolean, andID. - You can define an Object type by starting a
typedeclaration. An Object type contains fields, one per line. Each field has a name and a type, which can be either an object type, or a scalar type - Object fields can have parameters (as in the
Notificationsquery), inside parentheses. These parameters have types, too. - Required fields have an exclamation point stuck to their type name (e.g.
ID!) - You can add comments (starting with a
#sign) - The schema can contain annotations, called directives (as the
@deprecatedname field) - You can define a Scalar type by starting a
scalardeclaration

The schema doesn’t explain how the server fetches the result, it describes what the result should look like. In that sense, the graphql language is, just like SQL, a declarative language. But unlike SQL, a GraphQL request and response are very much lookalike - you always know what to expect.
In practice, in order to write a GraphQL query, I first think about the result I’m expecting, for instance:
{ Tweets: [ { id: 752, body: "consectetur adipisicing elit", date: "2017-07-15T13:17:42.772Z", Author: { username: "alang", full_name: "Adrian Lang", avatar_url: "http://avatar.acme.com/02ac660cdda7a52556faf332e80de6d8" }, { id: 123, body: "Lorem Ipsum dolor sit amet", date: "2017-07-14T12:44:17.449Z", Author: { username: "creilly17", full_name: "Carole Reilly", avatar_url: "http://avatar.acme.com/5be5ce9aba93c62ea7dcdc8abdd0b26b" }, }, // etc. ], User: { full_name: "John Doe" }, NotificationsMeta: { count: 12 }}Then I remove the colons, commas, and the values. Finally, I add in the parameters. The result is the GraphQL query to get that result:
{ Tweets(limit: 10, sortField: "date", sortOrder: "DESC") { id body date Author { username full_name avatar_url } } User { full_name } NotificationsMeta { count }}With GraphQL, I’m sure of what the response contains, regardless of the technology used to implement the GraphQL server. I started appreciating this advantage after my first GraphQL project, when I understood that all I had learned on the first project was directly applicable to the second one.
If you feel that repeating the list of fields you want in every query is cumbersome, check out GraphQL fragments - they’re kind of like macros.
Mutations and Subscriptions
I’ve already explained how to call a Query:
{ Tweet(id: 123) { id body date }}Actually, GraphQL expects the request to start with a keyword defining the type of entry point targeted by the request. In the absence of keyword, it falls back to query, but I can also make it explicit:
query { Tweet(id: 123) { id body date }}And just like that, you’ve just learned how to call mutations and subscriptions: just prefix the request with the proper keyword:
mutation { createTweet(body: "Hello, world!") { id body date }}subscription { tweetPublished(userId: 123) { id date body Author { username full_name avatar_url } }}A GraphQL query can only contain one of the three keywords query, mutation, and subscription. That means you can’t aggregate read and write operations in a single query.
Note: GraphQL doesn’t specify the transport to use for the realtime subscriptions. It’s usually WebSockets, but you can use iOS push notifications, long polling, or even email!
It’s a good practice to name your requests. You can add a name between the keyword and the opening bracket, like so:
query getTweetDetail { Tweet(id: 123) { id body date }}This will come in handy when debugging GraphQL on the client side, as debug tools list the queries made by the client by name.
Variables And Prepared Queries
In the first example, I’ve asked for the Tweet of id 123:
----------------------------------- request POST / HTTP 1.1 Host: http://graphql.acme.com/ Content-Type: application/graphql { Tweet(id: 123) { id body date } }To build such a query, I have to concatenate or interpolate a value (123) into a string. This opens the path to injection attacks - not SQL injection, but GraphQL injection.
To make this query safe, I can transform the 123 value into a $id variable, and tell GraphQL to bind the 123 value to this variable. If this sounds like prepared statements in SQL, that’s on purpose.
To use a variable in a GraphQL query, I have to declare it at the top of the query, before the opening bracket, and specify its type. As for the variable value, I can pass it in the query string, as a serialized JSON object:
----------------------------------- request POST /?variables={"id":123} HTTP 1.1 Host: http://graphql.acme.com/ Content-Type: application/graphql ($id: ID!) { Tweet(id: $id) { id body date } }Now the query is safe from injection attacks. In addition to allowing reusability of queries, graphql variables facilitate cumbersome String interpolation and escaping.
If you’re looking for a way to remember the GraphQL syntax, I recommend the GraphQL cheat sheet by Hafiz Ismail.
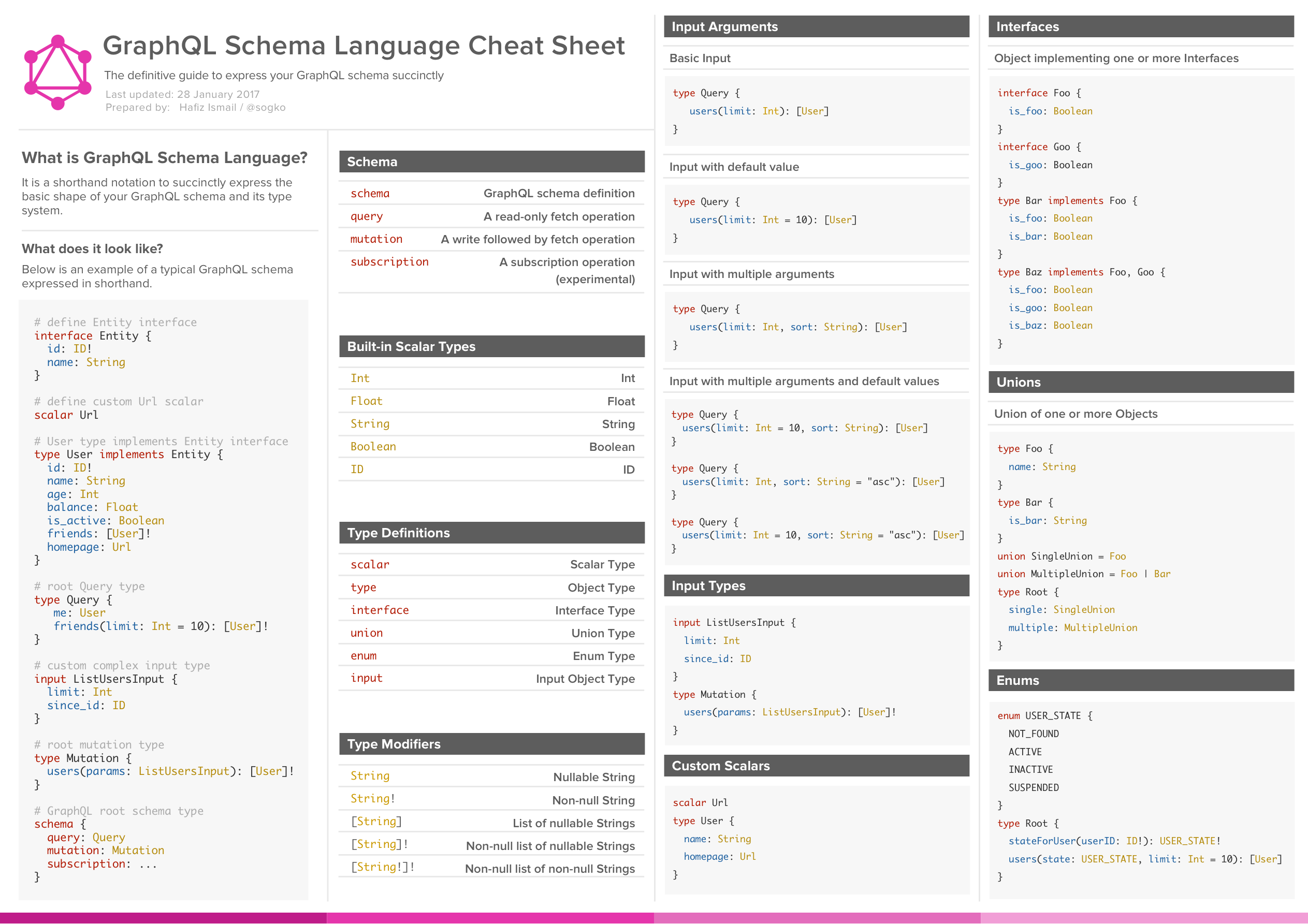{kind=link}
GraphQL Sits Between the Client and the Server
At that point, developers often wonder: Okay, GraphQL is a language, but how does that translate into my software architecture?

Basically, a GraphQL server is an API gateway, a proxy between clients and a backend server. The backend server can be anything (REST API, relational database, NoSQL database). You can even use several backends and hide them behind a single GraphQL (proxy) server.
The GraphQL server comes in various languages, the first one being Node.js. But you’re not constrained to JavaScript if it doesn’t make sense for your team. You won’t have to write much code on the server anyway - you can even use a Backend-as-a-Service tool like the excellent GraphCool to deal with the GraphQL server side for you.
There is also usually a small GraphQL SDK sitting on the client side, helping to build requests and decode responses. This is entirely optional, but that’s the advantage of using a standard: you don’t have to rewrite the code for every project.
GraphQL In a Nutshell

So GraphQL is a “query language”, just like HTTP verbs and resource URLs are the “query language” of REST. But this language is much more developed and standardized than REST.
- GraphQL is an API gateway, or a proxy server that sits in front of data backends.
- GraphQL is a DSL to express the business logic exposed to clients
- GraphQL is a declarative query language. Clients get what they ask for.
- GraphQL is designed for Remote Procedure Call, and not limited to CRUD.
- GraphQL is a strong, statically typed language. It makes development faster and less error-prone.
- GraphQL supports read, write, and subscribe operations
- GraphQL moves the center of gravity towards the client. The client decides what fields they get in the response, not the server.
- GraphQL works on HTTP… but not only. It’s a specification for fetching and updating data that can be implemented in any protocol
- GraphQL supports aggregations and combinations of multiple resources in a single request out of the box
- GraphQL servers offer built-in API documentation
- GraphQL supports API evolution, and allows for deprecation warnings
- GraphQL does not care about the backend storage. You can keep your database, you can even keep your REST API if it’s still used.
All in all, GraphQL is not the next REST, it’s the next SOAP, redesigned from the ground up with the most important lesson learned from REST: simplicity. And I believe it’s a great idea.

Okay, you’ve read enough about what GraphQL is. It’s time to develop with GraphQL, for real. In the next post of this series, I’ll teach you to develop a GraphQL server in Node.js for a Twitter-like mobile app.
Authors
Marmelab founder and CEO, passionate about web technologies, agile, sustainability, leadership, and open-source. Lead developer of react-admin, founder of GreenFrame.io, and regular speaker at tech conferences.