
Dive Into GraphQL Part III: Building a GraphQL Server With Node.js

The previous posts in the Dive Into GraphQL Series explained why GraphQL looks like a good fit for mobile applications. But what matters the most about frameworks and libraries is the developer experience. Usability ultimately decides which library will survive. In my experience, GraphQL offers fantastic tooling, and developing applications with GraphQL is a pleasure. Let’s see that in practice by building a GraphQL server from scratch.
- The Target
- Start With a Schema
- Building a Basic GraphQL Server
- GraphiQL
- Writing Resolvers
- Handling Relationships
- Plugging The Server To Real Databases
- The 1+N Queries Problem
- Managing Custom Scalar Types
- Error Handling
- Server Logging
- Authentication & Middleware
- Unit Testing Resolvers
- Integration Testing of the Query Engine
- Splitting Resolvers
- Composing Schemas
- Conclusion
If you’re mostly interested in developing GraphQL clients, you can skip this post. You can find ready-to-use GraphQL servers requiring no coding:
- json-graphql-server, which takes a JSON of your data as input (highly recommended, because marmelab built it!)
- GraphCool, a GraphQL backend-as-a-service
The Target
My objective: Allowing a mobile app to display a list of tweets in one single round trip. I’ll use Node.js for that job, because it’s the language we’ve been using for the past 4 years at marmelab. But you could use any other language you want, from Ruby to Go, and including PHP, Java, and C#. I’ll follow the best practices learned by the marmelab developers.
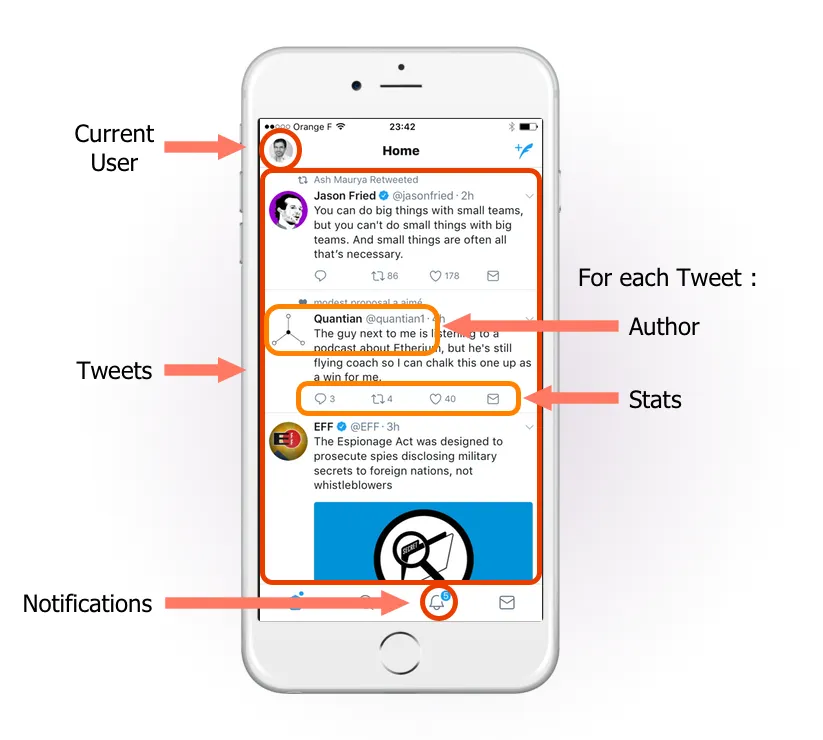
To help display this page on the frontend, the server must be able to generate the following response:
{ "data": { "Tweets": [ { "id": 752, "body": "consectetur adipisicing elit", "date": "2017-07-15T13:17:42.772Z", "Author": { "username": "alang", "full_name": "Adrian Lang", "avatar_url": "http://avatar.acme.com/02ac660cdda7a52556faf332e80de6d8" } }, { "id": 123, "body": "Lorem Ipsum dolor sit amet", "date": "2017-07-14T12:44:17.449Z", "Author": { "username": "creilly17", "full_name": "Carole Reilly", "avatar_url": "http://avatar.acme.com/5be5ce9aba93c62ea7dcdc8abdd0b26b" } } // etc. ], "User": { "full_name": "John Doe" }, "NotificationsMeta": { "count": 12 } }}I want modular and maintainable code, with unit tests. Sounds difficult? You’ll see that thanks to the GraphQL tooling, it’s not much harder than building a REST client.
Start With a Schema
When I develop a GraphQL server, I always start on the white board. I don’t start coding right away ; instead, I discuss with the product and frontend dev teams to decide which types, queries and mutations must be exposed. If you know the Domain-Driven Design (DDD) approach, you’ll be in a familiar place. The frontend development team cannot start coding until they have a server exposing data. Agreeing on an API contract allows just that.
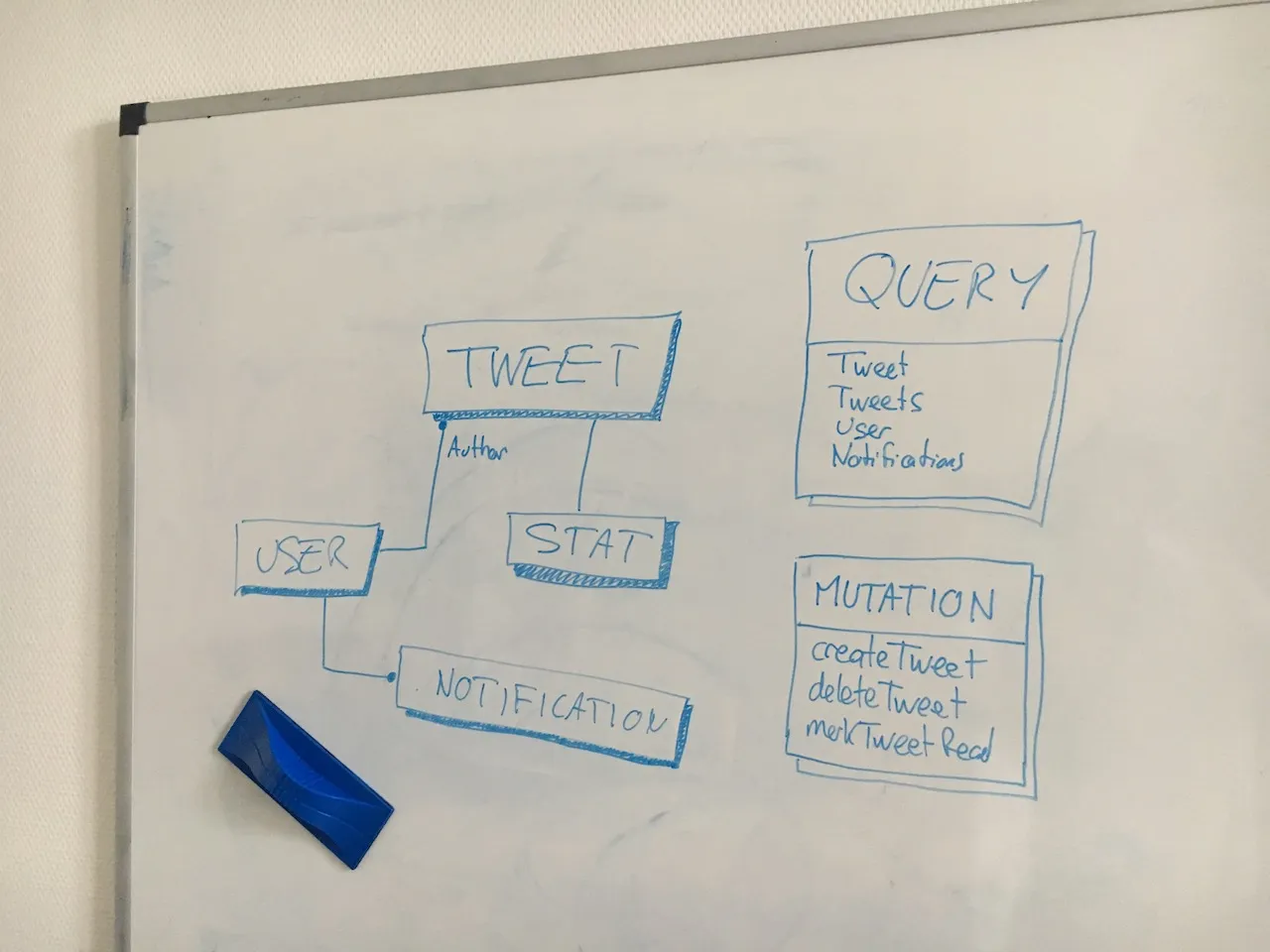
Naming is hard! Don’t underestimate the time necessary to design a good contract. Especially since the names you choose will stay forever - remember, GraphQL APIs have no versions, they evoluate. Also, try to make your schema self explanatory, because it’s the first piece of code that new developers will read.
Here is the GraphQL schema I’ll use throughout this tutorial:
type Tweet { id: ID! # The tweet text. No more than 140 characters! body: String # When the tweet was published date: Date # Who published the tweet Author: User # Views, retweets, likes, etc Stats: Stat}
type User { id: ID! username: String first_name: String last_name: String full_name: String name: String @deprecated avatar_url: Url}
type Stat { views: Int likes: Int retweets: Int responses: Int}
type Notification { id: ID date: Date type: String}
type Meta { count: Int}
scalar Urlscalar Date
type Query { Tweet(id: ID!): Tweet Tweets(limit: Int, sortField: String, sortOrder: String): [Tweet] TweetsMeta: Meta User: User Notifications(limit: Int): [Notification] NotificationsMeta: Meta}
type Mutation { createTweet(body: String): Tweet deleteTweet(id: ID!): Tweet markTweetRead(id: ID!): Boolean}I’ve briefly explained how the schema syntax works in the previous post in this series. What you need to know is that types are like REST resources. You can use types to define entities, which have a unique id (like Tweet and Stat). You can also use types to define value objects, who live inside entities and therefore don’t need an identifier (like Stat).
Make types as small as possible, and compose them. For instance, even if the stats data live alongside the tweet data in your database, make them two separate types. They are two different concepts anyway. And when the time comes to move the stats data out to another database, you’ll be glad you designed the schema like that.
The Query and Mutation types have a special meaning: they define the entry points to the API. Yes, that means you can’t have a custom type named Query or Mutation - these are reserved words in GraphQL. And one thing that can be confusing is that the name of fields of the Query type are often the same as the entity types - but that’s only by convention. Instead of exposing the Tweet query to retrieve a Tweet entity, I could have decided to name it getTweet - remember, GraphQL is a Remote Procedure Call (RPC) protocol.
The official GraphQL schema documentation gives all the necessary details to build your own schema. Go read it, it’s ten minutes well spent.
You may find GraphQL tutorials where the schema is written in code, using classes like GraphQLObjectType. Don’t do that. It’s verbose, tedious, and non declarative. The graphql language was designed to facilitate the process of writing a schema, you should use it!
Building a Basic GraphQL Server
In Node.js, the fastest way to build an HTTP server is to use the express microframework. I’ll expose the GraphQL entry point at http://localhost:4000/graphql.
> npm install express express-graphql graphql-tools graphql --saveexpress-graphql creates a graphql server app based on a schema and resolver functions. graphql-tools is a server-agnostic package that deals with schema, query parsing and validation. The first package is authored by Facebook, the second one by Apollo.
// in src/index.jsconst fs = require("fs");const path = require("path");const express = require("express");const graphqlHTTP = require("express-graphql");const { makeExecutableSchema } = require("graphql-tools");
const schemaFile = path.join(__dirname, "schema.graphql");const typeDefs = fs.readFileSync(schemaFile, "utf8");
const schema = makeExecutableSchema({ typeDefs });var app = express();app.use( "/graphql", graphqlHTTP({ schema: schema, graphiql: true, }),);app.listen(4000);console.log("Running a GraphQL API server at localhost:4000/graphql");I start the server with:
> node src/index.jsRunning a GraphQL API server at localhost:4000/graphqlTo test the new graphql endpoint, I send a test HTTP request with curl:
> curl 'http://localhost:4000/graphql' \> -X POST \> -H "Content-Type: application/graphql" \> -d "{ Tweet(id: 123) { id } }"{ "data": {"Tweet":null}}It works!
And since it knows my schema, the GraphQL server validates the query before executing it. If I request a field that is not declared in the schema, I get an error:
> curl 'http://localhost:4000/graphql' \> -X POST \> -H "Content-Type: application/graphql" \> -d "{ Tweet(id: 123) { foo } }"{ "errors": [ { "message": "Cannot query field \"foo\" on type \"Tweet\".", "locations": [{"line":1,"column":26}] } ]}The express-graphql package creates a GraphQL endpoint accepting both GET and POST requests.
Another great package for developing GraphQL servers for express, koa, HAPI and Restify is apollo-server. Its syntax isn’t much different, so this tutorial also applies if you use it.
GraphiQL
The server seems to run properly, but curl isn’t the best GraphQL client for testing. Instead, I’ll use GraphiQL (pronounced “Graphical”), a web client with a graphical user interface. Think of it as an equivalent of Postman for GraphQL.
Because I added the graphiql option in the graphqlHTTP middleware execution, GraphiQL is already running. When I load the GraphQL endpoint (http://localhost:4000/graphql) in a browser, I see the web GUI. It sends an introspection query to the API, grabs the entire schema, and builds an interactive documentation for that endpoint. Clicking on the “Docs” link on the top right of the window reveals the documentation:
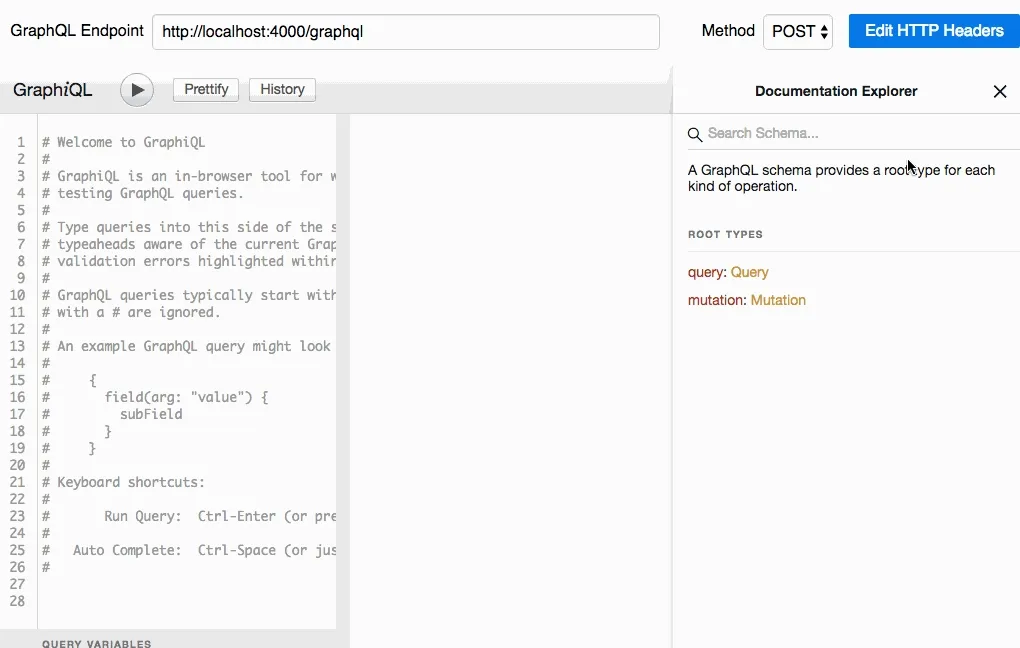
Thanks to the schema, the server provides an auto generated API documentation. That means that I don’t need to add a Swagger server.
The documentation for each type and field comes from the schema comments (i.e. the lines starting with a # sign). Use comments extensively, frontend devs will thank you for it.
But that’s not all: Using the schema, GraphiQL is able to autocomplete my queries with Intellisense-like suggestions!
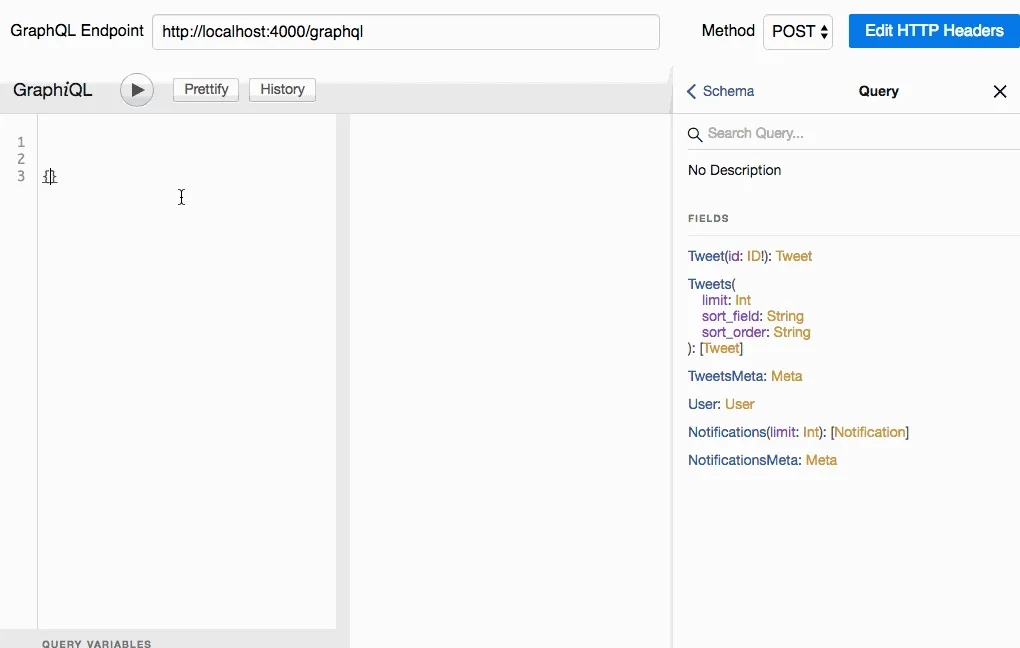
That’s usually when they see that kind of demo that developers become hooked. GraphiQL is the killer app for GraphQL, and a must have for GraphQL development. Don’t forget to disable it on production, though.
You can also install GraphiQL as a standalone app, based on Electron. Download the Windows, OS X, or Linux executable at https://github.com/skevy/graphiql-app/releases.
Writing Resolvers
So far, the server returns an empty response for every query. I’ll make it return real data using resolver functions. But first, I need the data. Let’s start with a simple in-memory storage:
const tweets = [ { id: 1, body: "Lorem Ipsum", date: new Date(), author_id: 10 }, { id: 2, body: "Sic dolor amet", date: new Date(), author_id: 11 },];const authors = [ { id: 10, username: "johndoe", first_name: "John", last_name: "Doe", avatar_url: "acme.com/avatars/10", }, { id: 11, username: "janedoe", first_name: "Jane", last_name: "Doe", avatar_url: "acme.com/avatars/11", },];const stats = [ { tweet_id: 1, views: 123, likes: 4, retweets: 1, responses: 0 }, { tweet_id: 2, views: 567, likes: 45, retweets: 63, responses: 6 },];Now I have to tell the server how to answer the Tweet and Tweets queries. Here comes the resolver map, an object following the same structure as the schema, and exposing one function per field:
const resolvers = { Query: { Tweets: () => tweets, Tweet: (_, { id }) => tweets.find((tweet) => tweet.id == id), }, Tweet: { id: (tweet) => tweet.id, body: (tweet) => tweet.body, },};
// pass the resolver map as second argumentconst schema = makeExecutableSchema({ typeDefs, resolvers });// proceed with the express app setupThe official express-graphql documentation advises using a rootValue option instead of adding the resolvers via makeExecutableSchema(). Don’t do that - it’s a dead end. You won’t be able to define type resolvers that way.
The signature of resolver function is (previousValue, parameters) => data. That’s enough to let the server answer basic queries:
// query { Tweets { id body } }{ data: Tweets: [ { id: 1, body: 'Lorem Ipsum' }, { id: 2, body: 'Sic dolor amet' } ]}// query { Tweet(id: 2) { id body } }{ data: Tweet: { id: 2, body: 'Sic dolor amet' }}Here is how that works: the server walks the query one curly brace at the time using resolver functions, passing the previous step as the first argument to the resolver. So for the { Tweet(id: 2) { id body } } query, the following steps happen:
- The first query is
Tweet. There is a resolver for that (Query.Tweet). As there is no previous value, the function executes with a null first argument. The second argument is the parameters passed to the query ({ id: 2 }in JS). The resolver returns atweetwhich, according to the schema, is of theTweettype. - For each field in the tweet, the server executes the resolver functions (
Tweet.idandTweet.body). It passes the result of the previous step (the tweet) as parameter.
The Tweet.id and Tweet.body resolvers are so basic that, actually, I don’t have to declare them. In the absence of a field resolver, GraphQL falls back to a simple object lookup.
Mutation resolvers aren’t much harder to write than query resolvers. For instance:
const resolvers = { // ... Mutation: { createTweet: (_, { body }) => { const nextTweetId = tweets.reduce((id, tweet) => { return Math.max(id, tweet.id); }, -1) + 1; const newTweet = { id: nextTweetId, date: new Date(), author_id: currentUserId, // <= you'll have to deal with that body, }; tweets.push(newTweet); return newTweet; }, },};Keep you resolvers small. GraphQL is supposed to be an API gateway, a thin layer on top of your domain. Resolvers should only contain code related to parsing the request and shaping the response - sort of like a controller in an MVC framework. Anything other than that should be isolated in agnostic model objects, ignorant of GraphQL.
You can find a complete documentation on resolvers in the Apollo website.
Handling Relationships
Now, the interesting part begins. What I want is to give the server the ability to execute complex queries with aggregations, like so:
{ Tweets { id body Author { username full_name } Stats { views } }}In SQL, this would work with two joins (on User and Stat) and a SQL execution engine of millions of lines of code. The GraphQL implementation is much shorter: I just need to add the proper resolver functions to the Tweet type:
const resolvers = { Query: { Tweets: () => tweets, Tweet: (_, { id }) => tweets.find((tweet) => tweet.id == id), }, Tweet: { Author: (tweet) => authors.find((author) => author.id == tweet.author_id), Stats: (tweet) => stats.find((stat) => stat.tweet_id == tweet.id), }, User: { full_name: (author) => `${author.first_name} ${author.last_name}`, },};
// pass the resolver map as second argumentconst schema = makeExecutableSchema({ typeDefs, resolvers });With these resolvers, the server can answer the query to get the desired result:
{ data: { Tweets: [ { id: 1, body: "Lorem Ipsum", Author: { username: "johndoe", full_name: "John Doe", }, Stats: { views: 123, }, }, { id: 2, body: "Sic dolor amet", Author: { username: "janedoe", full_name: "Jane Doe", }, Stats: { views: 567, }, }, ]; }}I don’t know about you, but the first time I saw that, I thought it was magic. How can a simple list of resolver functions let the server execute such a complex query? It turns out it’s easy to understand, but very smart.
Once again, GraphQL walks the query using resolver functions. Let’s see the query again:
{ Tweets { id body Author { username full_name } Stats { views } }}Now, let’s follow the resolver path:
- For the
Tweetsquery, GraphQL executes theQuery.Tweetsresolver with no argument (since it’s the first step). The resolver returns atweetsarray which, according to the schema, is an array of theTweettype. - For each tweet, GraphQL executes the resolver functions for
Tweet.id,Tweet.body,Tweet.Author, andTweet.Statsin parallel. It passes the result of the previous step (the tweet) as parameter. - I haven’t provided resolver functions for
Tweet.idandTweet.bodythis time, so GraphQL uses the default field resolver. As for theTweet.Authorresolver, it returns anauthor, which, according to the schema, is of theUsertype. - On this
User, the query executes resolvers forusernameandfull_namein parallel, passing the result of the previous step (the author) as a parameter. - Same for the
Stat, for which the default field resolver is used.
So that’s the heart of the GraphQL server, and the smartest idea in the package. It works for queries of any level of complexity. That’s also the “aha” moment, where the word “Graph” in “GraphQL” reveals its sense.
You can find an explanation of the GraphQL execution system in the graphql.org website.
Plugging The Server To Real Databases
In the real world, resolvers use a database or an API to store data. Connecting resolvers to a data store isn’t much different from what I’ve written previously, except that the resolvers must return promises. So for instance, if the tweets and authors were stored in a PostgreSQL database, and if the stats were stored in a mongoDB database, then the resolver map would look like:
const { Client } = require('pg');const MongoClient = require('mongodb').MongoClient;
const resolvers = { Query: { Tweets: (_, __, context) => context.pgClient .query('SELECT * from tweets') .then(res => res.rows), Tweet: (_, { id }, context) => context.pgClient .query('SELECT * from tweets WHERE id = $1', [id]) .then(res => res.rows), User: (_, { id }, context) => context.pgClient .query('SELECT * from users WHERE id = $1', [id]) .then(res => res.rows), }, Tweet: { Author: (tweet, _, context) => context.pgClient .query('SELECT * from users WHERE id = $1', [tweet.author_id]) .then(res => res.rows), Stats: (tweet, _, context) => context.mongoClient .collection('stats') .find({ 'tweet_id': tweet.id }) .query('SELECT * from stats WHERE tweet_id = $1', [tweet.id]) .toArray(), }, User: { full_name: (author) => `${author.first_name} ${author.last_name}` },};const schema = makeExecutableSchema({ typeDefs, resolvers });
const start = async () => { // make database connections const pgClient = new Client('postgresql://localhost:3211/foo'); await pgClient.connect(); const mongoClient = await MongoClient.connect('mongodb://localhost:27017/bar');
var app = express(); app.use('/graphql', graphqlHTTP({ schema: schema, graphiql: true, context: { pgClient, mongoClient }), })); app.listen(4000);};
start();Apart from the fact that the code now needs to be in an async function (because the database connections can only be retrieved in an asynchronous way) I stored the database connections in the GraphQL server context, which is passed as third argument to all resolver functions. The context is a good place to store the currently logged in user, or any other info you’ll need in several resolvers.
As you can see, it’s easy to aggregate data from various databases. And the client doesn’t even need to know where the data is stored - it all happens in the resolvers.
The 1+N Queries Problem
Walking the query with resolver functions is smart, but it performs poorly. In the previous example, the Tweet.Author resolver is executed as many times as there are tweets in the result of the Query.Tweets resolver. So I will end up with one query for the tweets, and N queries for the tweet authors.
To solve this problem, I add another package called DataLoader, once again authored by Facebook.
npm install --save dataloaderDataLoader is a data caching and batching utility. Here is how it works: First, I create a function for fetching a list of items, returning a Promise. Then, I create a dataloader for a single item, passing the previous function as argument.
const DataLoader = require("dataloader");const getUsersById = (ids) => pgClient .query(`SELECT * from users WHERE id = ANY($1::int[])`, [ids]) .then((res) => res.rows);const dataloaders = () => ({ userById: new DataLoader(getUsersById),});The userById.load(id) function debounces multiple calls for a single item, accumulating the id argument passed to each call. It then calls getUsersById with the list of ids.
If you’re not familiar with PostgreSQL, WHERE id = ANY($1::int[]) is a fast way to write WHERE id IN ($1, $2, $3), regardless of the number of elements in the array.
I store the dataloader in the context:
app.use( "/graphql", graphqlHTTP((req) => ({ schema: schema, graphiql: true, context: { pgClient, mongoClient, dataloaders: dataloaders() }, })),);Now I just need to replace the Tweet.Author resolver:
const resolvers = { // ... Tweet: { Author: (tweet, _, context) => context.dataloaders.userById.load(tweet.author_id), }, // ...};And it works! A query like { Tweets { Author { username } } will now do at most 2 database queries: one for the tweets, and one for the tweet authors!
I want to draw your attention to one important gotcha: In the graphqlHTTP setup code, I passed a function as argument (graphqlHTTP(req => ({ ... }))) instead of passing an object (graphqlHTTP({ ... })). This is because DataLoader instances also cache results, so I only want to have one DataLoader instance per request.
And to be fair, the previous code doesn’t work, because pgClient doesn’t exist in the context of the getUsersById function. To pass database connections to dataloaders via the context, it’s a little more complicated. Here is the final code:
const DataLoader = require("dataloader");const getUsersById = (pgClient) => (ids) => pgClient .query(`SELECT * from users WHERE id = ANY($1::int[])`, [ids]) .then((res) => res.rows);const dataloaders = (pgClient) => ({ userById: new DataLoader(getUsersById(pgClient)),});// ...app.use( "/graphql", graphqlHTTP((req) => ({ schema: schema, graphiql: true, context: { pgClient, mongoClient, dataloaders: dataloaders(pgClient) }, })),);In practice, you’ll have to use a DataLoader for all the resolvers of non-Query types that hit a datastore. It’s a must use in production environment. Don’t miss it!
Managing Custom Scalar Types
You may have noticed that I haven’t fetched the tweet date so far. That’s because I have defined a custom scalar type for it in the schema:
type Tweet { # ... date: Date}
scalar DateBelieve it or not, the GraphQL specification doesn’t define a Date scalar type. It’s up to every developer to implement it. Suffice it to say, you’ll have to do it for every GraphQL server you write. But it’s a good occasion to illustrate the ability to create custom scalar types, which can support validation and conversion of values.
Just like other types, scalar types need a resolver. But a scalar type resolver must be able to convert a value from the resolvers to the response, and vice-versa. That’s why it uses a special GraphQLScalarType object:
const { GraphQLScalarType, GraphQLError } = require('graphql');const { Kind } = require('graphql/language');
const validateValue = value => { if (isNaN(Date.parse(value))) { throw new GraphQLError(`Query error: not a valid date`, [value]);};
const resolvers = { // previous resolvers // ... Date: new GraphQLScalarType({ name: 'Date', description: 'Date type', parseValue(value) { // value comes from the client, in variables validateValue(value); return new Date(value); // sent to resolvers }, parseLiteral(ast) { // value comes from the client, inlined in the query if (ast.kind !== Kind.STRING) { throw new GraphQLError(`Query error: Can only parse dates strings, got a: ${ast.kind}`, [ast]); } validateValue(ast.value); return new Date(ast.value); // sent to resolvers }, serialize(value) { // value comes from resolvers return value.toISOString(); // sent to the client }, }),};This Date type assumes the values coming out of the database use JavaScript Date objects (that’s the type of data returned by node-pg for dates). If you store dates as timestamps instead, check out this alternative Date type implementation.
In addition to the Date scalar, you will probably need a JSON scalar, too. Don’t implement it yourself, use the graphql-type-json package instead.
Error Handling
Thanks to the schema, any malformed query is caught by the server, which returns an error response in that case:
// query { Tweets { id body foo } }{ "errors": [ { "message": "Cannot query field \"foo\" on type \"Tweets\".", "locations": [ { "line": 1, "column": 19 } ] } ]}This makes debugging client queries a piece of cake. It’s also easy to detect errors in client code, and fall back to displaying an error message to the end user.
As for server code, it’s another story. By default, JavaScripts errors thrown by the resolvers appear in the GraphQL response, but they are not logged on the server side. To track problems in development and production, I add a logger property to the makeExecutableSchema options. It must be an object with a log method:
const schema = makeExecutableSchema({ typeDefs, resolvers, logger: { log: (e) => console.log(e) },});Alternately, if you prefer to hide error messages in the GraphQL response, use the graphql-errors package.
Server Logging
In addition to the data and error keys, the response from a GraphQL server can expose an extensions key where you can put whatever you want. It’s the perfect place to add logs and timing about the request processing.
To add an extension, provide an extension function in the graphqlHTTP configuration, returning a JSON-serializable object.
For instance, here is how I add a timing extension key to the response, in order to track the response timing:
app.use('/graphql', graphqlHTTP(req => { const startTime = Date.now(); return { // ... extensions: ({ document, variables, operationName, result }) => ({ timing: Date.now() - startTime, }) };})));Now all GraphQL response contain the request timing in milliseconds:
// query { Tweets { id body } }{ "data": [ ... ], "extensions": { "timing": 53, }}You can easily instrument your resolvers to feed a more fine-grained timing extension. In production, this becomes really useful once you address more than one backend. Also, check apollo-tracing-js for a full-featured timing extension:
{ "data": <>, "errors": <>, "extensions": { "tracing": { "version": 1, "startTime": <>, "endTime": <>, "duration": <>, "execution": { "resolvers": [ { "path": [<>, ...], "parentType": <>, "fieldName": <>, "returnType": <>, "startOffset": <>, "duration": <>, }, ... ] } } }}The Apollo company also offers a GraphQL monitoring service called Optics, worth checking out before reinventing your own solution.
Authentication & Middleware
The GraphQL specification explicitly excludes authentication and authorization from the scope of the language. That means that you have to handle authentication on your own, using the express middleware of your choice (hint: passport.js probably covers your needs).
However, some tutorials suggest using GraphQL mutations for sign in and sign up actions, and baking the authentication logic in the GraphQL resolvers. In my opinion, in most cases this is overkill. Consider this option only if you have advanced authorization requirements (role-based access system or ACLs).
Remember, GraphQL is an API Gateway, it shouldn’t contain too much logic.
Unit Testing Resolvers
Resolvers are pure functions, so unit tests are straightforward. For this tutorial, I’ll be using Jest, because it’s a drop-in, zero setup testing utility. Also by Facebook by the way.
> npm install jest --save-devLet’s start with the simplest resolver I’ve written so far, User.full_name. In order to test it, I must first extract the resolver to its own file:
// in src/user/resolvers.jsexports.User = { full_name: (author) => `${author.first_name} ${author.last_name}`,};
// in src/index.jsconst User = require("./resolvers/User");const resolvers = { // ... User,};const schema = makeExecutableSchema({ typeDefs, resolvers });// ...Now, here is the unit test:
// in src/user/resolvers.spec.jsconst { User } = require("./resolvers");
describe("User.full_name", () => { it("concatenates first and last name", () => { const user = { first_name: "John", last_name: "Doe" }; expect(User.full_name(user)).toEqual("John Doe"); });});I launch the tests with ./node_modules/.bin/jest, and enjoy the green terminal output.
Resolvers that depend on a datastore may look a bit trickier to write. But thanks to the context being passed as parameter, mocking the datastore is a breeze. For instance, here is how I extract and test the Query.Tweets resolver:
// in src/tweet/resolvers.jsexports.Query = { Tweets: (_, _, context) => context.pgClient .query('SELECT * from tweets') .then(res => res.rows),};
// in src/tweet/resolvers.spec.jsconst { Query } = require('./resolvers');describe('Query.Tweets', () => { it('returns all tweets', () => { const queryStub = q => { if (q == 'SELECT * from tweets') { return Promise.resolve({ rows: [ { id: 1, body: 'hello' }, { id: 2, body: 'world' }, ]}); } }; const context = { pgClient: { query: queryStub } }; return Query.Tweets(null, null, context).then(results => { expect(results).toEqual([ { id: 1, body: 'hello' } { id: 2, body: 'world' } ]); }); });})The only trick here is that the test must return a promise, and check assertions inside a then() clause, so that Jest knows the test is asynchronous. I’ve mocked the context by hand, but in the real world, you’ll probably want to use a specialized mocking library like Sinon.js.
So as you can see, testing resolvers is as easy as pie, because resolvers are pure functions. Another smart choice by the people who designed GraphQL!
Integration Testing of the Query Engine
But how about testing relationships, types, aggregations, etc? This is another kind of test, named integration test, operated on the query engine itself.
Does it imply launching an express app just for integration tests? Fortunately, no. You can get a query engine without a server, using the graphql utility.
Before testing the query engine, I must first extract it.
// in src/schema.jsconst fs = require("fs");const path = require("path");const { makeExecutableSchema } = require("graphql-tools");const resolvers = require("../resolvers"); // extracted from the express app
const schemaFile = path.join(__dirname, "./schema.graphql");const typeDefs = fs.readFileSync(schemaFile, "utf8");
module.exports = makeExecutableSchema({ typeDefs, resolvers });
// in src/index.jsconst express = require("express");const graphqlHTTP = require("express-graphql");const schema = require("./schema");
var app = express();app.use( "/graphql", graphqlHTTP({ schema, graphiql: true, }),);app.listen(4000);console.log("Running a GraphQL API server at localhost:4000/graphql");Now I can test this standalone schema:
// in src/schema.spec.jsconst { graphql } = require('graphql');const schema = require('./schema');
it('responds to the Tweets query', () => { // stubs const queryStub = q => { if (q == 'SELECT * from tweets') { return Promise.resolve({ rows: [ { id: 1, body: 'Lorem Ipsum', date: new Date(), author_id: 10 }, { id: 2, body: 'Sic dolor amet', date: new Date(), author_id: 11 } ]}); } }; const dataloaders = { userById: { load: id => { if (id == 10 ) { return Promise.resolve({ id: 10, username: 'johndoe', first_name: 'John', last_name: 'Doe', avatar_url: 'acme.com/avatars/10' }); } if (id == 11 ) { return Promise.resolve({ { id: 11, username: 'janedoe', first_name: 'Jane', last_name: 'Doe', avatar_url: 'acme.com/avatars/11' }); } } } }; const context = { pgClient: { query: queryStub }, dataloaders }; // now onto the test itself const query = '{ Tweets { id body Author { username } }}'; return graphql(schema, query, null, context).then(results => { expect(results).toEqual({ data: { Tweets: [ { id: '1', body: 'hello', Author: { username: 'johndoe' } }, { id: '2', body: 'world', Author: { username: 'janedoe' } }, ], }, }); });})The signature of this standalone graphql query engine is graphql(schema, query, rootValue, context) => Promise (see documentation). It’s a super convenient way to test the GraphQL logic without an actual web server. As a side note, it’s what graphqlHTTP uses internally.
Another testing practice encouraged by the Apollo team is the use of mockServer from graphql-tools. Based on a text schema, it creates an in memory datastore populated with fake data, and the resolvers to read from that datastore. Finally, using the same graphql utility I used above, it lets you send queries to this mock GraphQL server. It’s documented in detail in the Mocking a GraphQL Server tutorial. However, I wouldn’t recommend this approach for server tests - it doesn’t test your resolvers at all. It’s more a tool for frontend developers, who need a working GraphQL server to play with, based only on the schema provided by the backend team.
Splitting Resolvers
In order to test the resolvers and the query engine, I had to split the logic across several, single-purpose resolvers. That’s a good thing from a developer’s perspective - it improves modularity and maintainability. Let’s finish this refactoring and make all resolvers modular.
// in src/tweet/resolvers.jsexport const Query = { Tweets: (_, _, context) => context.pgClient .query('SELECT * from tweets') .then(res => res.rows), Tweet: (_, { id }, context) => context.pgClient .query('SELECT * from tweets WHERE id = $1', [id]) .then(res => res.rows),}export const Mutation = { createTweet: (_, { body }, context) => context.pgClient .query('INSERT INTO tweets (date, author_id, body) VALUES ($1, $2, $3) RETURNING *', [new Date(), currentUserId, body]) .then(res => res.rows[0]) },}export const Tweet = { Author: (tweet, _, context) => context.dataloaders.userById.load(tweet.author_id), Stats: (tweet, _, context) => context.dataloaders.statForTweet.load(tweet.id),},
// in src/user/resolvers.jsexport const Query = { User: (_, { id }, context) => context.pgClient .query('SELECT * from users WHERE id = $1', [id]) .then(res => res.rows),};export const User = { full_name: (author) => `${author.first_name} ${author.last_name}`,};And here is the final merge of all the resolvers:
// in src/resolversconst { Query: TweetQuery, Mutation: TweetMutation, Tweet,} = require("./tweet/resolvers");const { Query: UserQuery, User } = require("./user/resolvers");
module.exports = { Query: Object.assign({}, TweetQuery, UserQuery), Mutation: Object.assign({}, TweetMutation), Tweet, User,};There you go! Now, with a modular structure, the code is easier to reason with, and easy to test.
Composing Schemas
Resolvers are now neatly organized, but what about the schema? It’s not a good practice to keep it all in a single large file. Besides, on large projects, it’s impossible to maintain. Just like resolvers, I like to split my schema into several files. Here is the directory structure I use and recommend, organized by model:
src/ stat/ resolvers.js schema.js tweet/ resolvers.js schema.js user/ resolvers.js schema.js base.js resolvers.js schema.js
The base.js schema contains the base types, and the empty Query and Mutation types - the sub-schema will add fields to them:
// in src/base.jsconst Base = `type Query { dummy: Boolean}
type Mutation { dummy: Boolean}
type Meta { count: Int}
scalar Urlscalar Date`;
module.exports = () => [Base];I’m obliged to include a dummy query and mutation, because GraphQL doesn’t accept empty types. Instead of exporting a string (Base), this script exports a function returning an array of strings. You’ll see how it comes in handy in a minute.
Now, on to the User schema. How does a sub-schema adds fields to an existing Query type? By using the graphql keyword extend:
// in src/user/schema.jsconst Base = require("../base");
const User = `extend type Query { User: User}type User { id: ID! username: String first_name: String last_name: String full_name: String name: String @deprecated avatar_url: Url}`;
module.exports = () => [User, Base];As you can see, the scripts does not only export the piece of schema I created (User), but also its dependencies (Base). That’s how I make sure that makeExecutableSchema will get all the types. That’s also why I always export an array.
The Stat type reserves no surprise:
// in src/stat/schema.jsconst Stat = `type Stat { views: Int likes: Int retweets: Int responses: Int}`;
module.exports = () => [Stat];The Tweet type depends on several other types, so I import them, just to reexport them at the end:
// in src/tweet/schema.jsconst User = require("../user/schema");const Stat = require("../stat/schema");const Base = require("../base");
const Tweet = `extend type Query { Tweet(id: ID!): Tweet Tweets(limit: Int, sortField: String, sortOrder: String): [Tweet] TweetsMeta: Meta}extend type Mutation { createTweet (body: String): Tweet deleteTweet(id: ID!): Tweet markTweetRead(id: ID!): Boolean}type Tweet { id: ID! # The tweet text. No more than 140 characters! body: String # When the tweet was published date: Date # Who published the tweet Author: User # Views, retweets, likes, etc Stats: Stat}`;
module.exports = () => [Tweet, User, Stat, Base];Now, the final part: to assemble those types in the main schema.js, I simply pass an array of types as typeDefs:
// in schema.jsconst Base = require("./base.graphql");const Tweet = require("./tweet/schema");const User = require("../user/schema");const Stat = require("../stat/schema");const resolvers = require("./resolvers");
module.exports = makeExecutableSchema({ typeDefs: [...Base, ...Tweet, ...User, ...Stat], resolvers,});Don’t worry about deduplicating types here: makeExecutableSchema only includes each type definition once, even if it is imported multiple times by different types.
The sub-schemas export a function instead of an array, because it’s required to solve circular dependencies. makeExecutableSchema understands both arrays and functions. Even if using a function is not required here (there is no circular dependency), I always use this syntax to avoid burdening my mind.

Conclusion
The server is now fast and unit tested. It’s time to rest! You can find the final code for this tutorial on GitHub: marmelab/GraphQL-example. Feel free to use it as a starting point for your own projects.
There are a few things about server-side GraphQL development that I didn’t mention, because they deserve an entire post:
- Security: Since clients can easily craft complex queries, it’s very easy to take a GraphQL server down using a DoS attack. You must take that risk into account and build mitigation measures, as described in this post: HowToGraphQL: GraphQL Security
- Subscriptions (and real-time scenarios): Most tutorials use WebSocket, and the tooling is almost ready. Read HowToGraphQL: Subscriptions, or Apollo: Server-Side Subscriptions for more details.
- Input Types: GraphQL only accepts a subset of types as input for mutations. See more details in Apollo: GraphQL Input Types And Client Caching.
- Persisted Queries. This subject will be covered in the last post in this series.
Note: Most of the JS libraries I’ve mentioned in this post are authored either by Facebook, or by Apollo. But who’s that Apollo guy? It’s not only the son of Zeus, it’s also a project by the excellent Meteor team. These guys are super active and contribute high quality code and documentation for GraphQL, all open-source. Kudos to them! But they also earn money by selling GraphQL-related services, so make sure you take a second opinion before following their tutorials blindly.
Developing a GraphQL server demands more work than for a simple REST server. But you get much more in return, too. If you feel overwhelmed after reading this tutorial, try to remember how you were the first time you had to learn about RESTful conventions (URIs, HTTP return codes, JSON Schema, HATEOAS). Today, you’re a fluent REST developer. I think that it only takes a day or two to fully grasp the server-side GraphQL complexity. And it’s totally worth the investment. Once you know your way around it, GraphQL is a pleasure to develop with.
One caveat: As it’s still young, there is still no agreement on the server-side GraphQL best practices yet. What I’ve explained in this tutorial is a synthesis of what I read, and what worked for marmelab. In my exploration phase, I found quite a lot of contradictory or outdated tutorials, because the technology is still moving. I hope this tutorial won’t be outdated too soon!
Enough with the server-side, let’s build a mobile client with React.js! Read the next post in this series to see how clients consume GraphQL queries.
If you want to read more on the subject by other authors, I recommend:
- Apollo: How GraphQL turns a query into a response, by the Apollo Team
- Apollo: Set up a simple GraphQL server in 5 steps, also by the Apollo Team
- HowToGraphQL: Graphql.js on the server side, by the GraphCool team
Authors
Marmelab founder and CEO, passionate about web technologies, agile, sustainability, leadership, and open-source. Lead developer of react-admin, founder of GreenFrame.io, and regular speaker at tech conferences.