
The Secret to Reliable AI Agents: Mastering Eval

An often-neglected aspect of AI agent development is the evaluation phase. While it’s relatively easy to build a proof of concept, it takes considerable time to find the best configuration to optimize cost, speed, relevancy, and other factors. Eval tools and frameworks are the key ingredients for this optimization phase.
AI Agents: 90% of the Work Is Optimization
The initial steps to build an LLM-powered agent (e.g., a legal agent that writes contracts or a banking agent that approves or denies credit requests) are surprisingly fast. Using simple prompts, few-shot learning, Retrieval-Augmented Generation (RAG), and structured outputs, many developers can build a proof of concept in just a few days. Tools like v0.dev and bolt.new can even reduce this phase to a few hours.
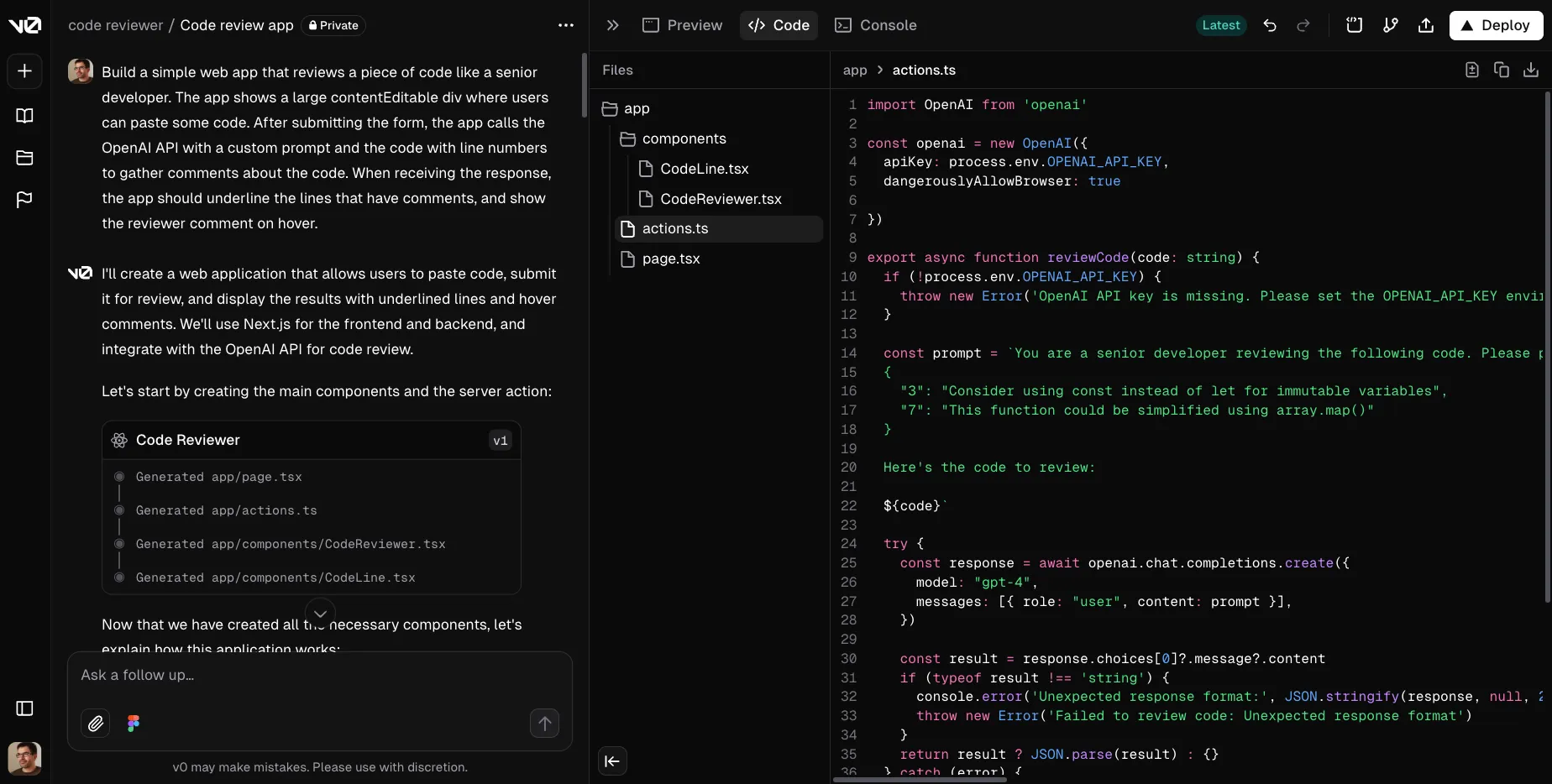
However, having an agent that works in a few specific test cases is far from enough. Moving from this first draft to a production-ready agent requires significant effort. Developers must make countless tweaks to achieve fast, consistent, reliable, and cost-effective results. This is one of the peculiarities of AI agent programming.
By “tweaks,” I mean adjusting the many levers that control the agent’s behavior. In a typical GenAI agent, there are numerous settings, each with a large number of possible values:
- Model architecture:
- For monolithic agents, the LLM size.
- For swarms of specialized agents, the responsibility of each agent, the number of agents, their size, etc.
- Model vendor: Anthropic, Google, Meta, Mistral, OpenAI, etc., and their versions.
- Model parameters: temperature, top-k, top-p, etc.
- Prompt instructions.
- Examples for few-shot learning.
- When using RAG:
- The indexing process and chunking strategy for documents.
- The embedding model.
- The vector database (pgvector, Pinecone, Faiss, etc.).
- The similarity metric (cosine similarity, approximate nearest-neighbor, etc.).
- The number of chunks retrieved.
- The reranking logic.
- Guardrailing: Smaller models to check for harmful or irrelevant outputs.
- Model infrastructure: caching, quantization, timeouts, etc.
- Post-processing logic.
The number of possible combinations for these parameters is enormous. In my experience, finding the best configuration can take weeks. I’d estimate that 90% of the time spent on developing an agent is spent in this optimization phase.
Eval: What Is a Good Agent?
To find the best configuration, you need to evaluate the performance of each setup. This is where things get tricky: What makes a good agent?
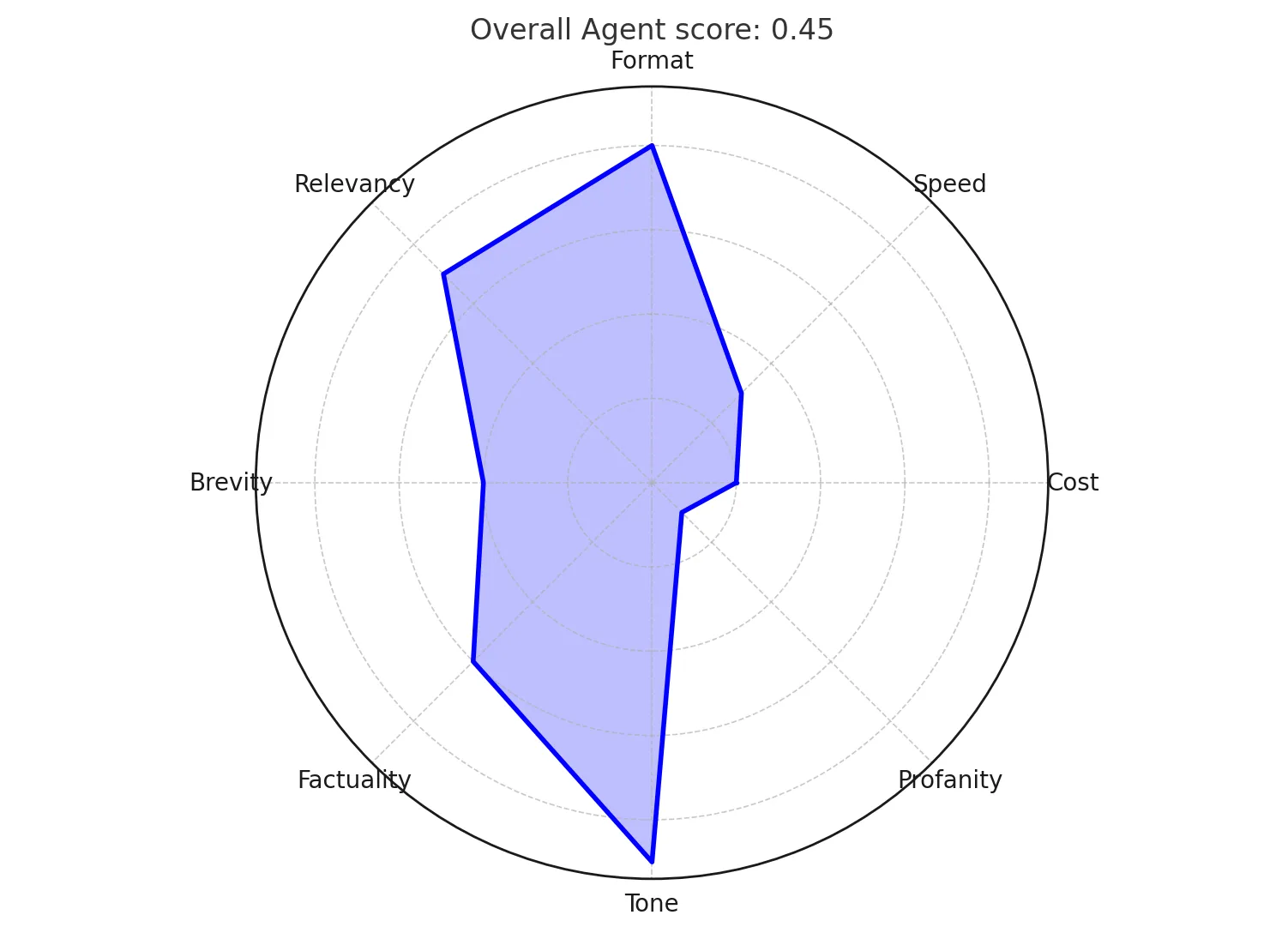
An agent must typically satisfy several requirements:
- The service it provides must be useful.
- It must avoid hallucinations or providing wrong answers.
- The output format must be consistent.
- It should handle a wide range of inputs, including edge cases.
- It must avoid harmful content (e.g., bias, misinformation).
- It must provide responses in a reasonable time.
- It must be cost-effective.
Ideally, all these requirements should be met simultaneously, but in practice, they often conflict. For example, reducing the model size to lower costs might degrade output quality. The goal of optimization is to strike the best compromise among these requirements.
Software engineers traditionally use unit tests, integration tests, and end-to-end tests to ensure that their code works as expected. But LLMs are random and non-deterministic, so these techniques don’t apply. Instead, we need a different approach.
A specialized field in AI focuses on measuring the performance of AI agents: Model Evaluation, often shortened to eval. The idea is to grade a model by grading its outputs. However, it remains challenging, as most experts agree that evaluating LLMs is inherently difficult.
Among eval tools, general benchmarks like HELM, MMLU, or Chatbot Arena are useful for evaluating foundation models but fall short for custom agents. Task-specific agents require tools designed to measure performance on tailored, real-world scenarios, and fortunately, many such tools are available.
Eval Tools and Frameworks
The evaluation process for AI agents relies on specialized tools and frameworks that streamline and automate the testing process. Some of the most widely used options include:
- Libraries: DeepEval, Ragas, Promptfoo, HuggingFace Evaluate, Prometheus Eval, OpenAI evals
- Platforms: LangSmith, Weights & Biases, OpenAI Eval API, Anthropic Evaluation, Laminar evaluations
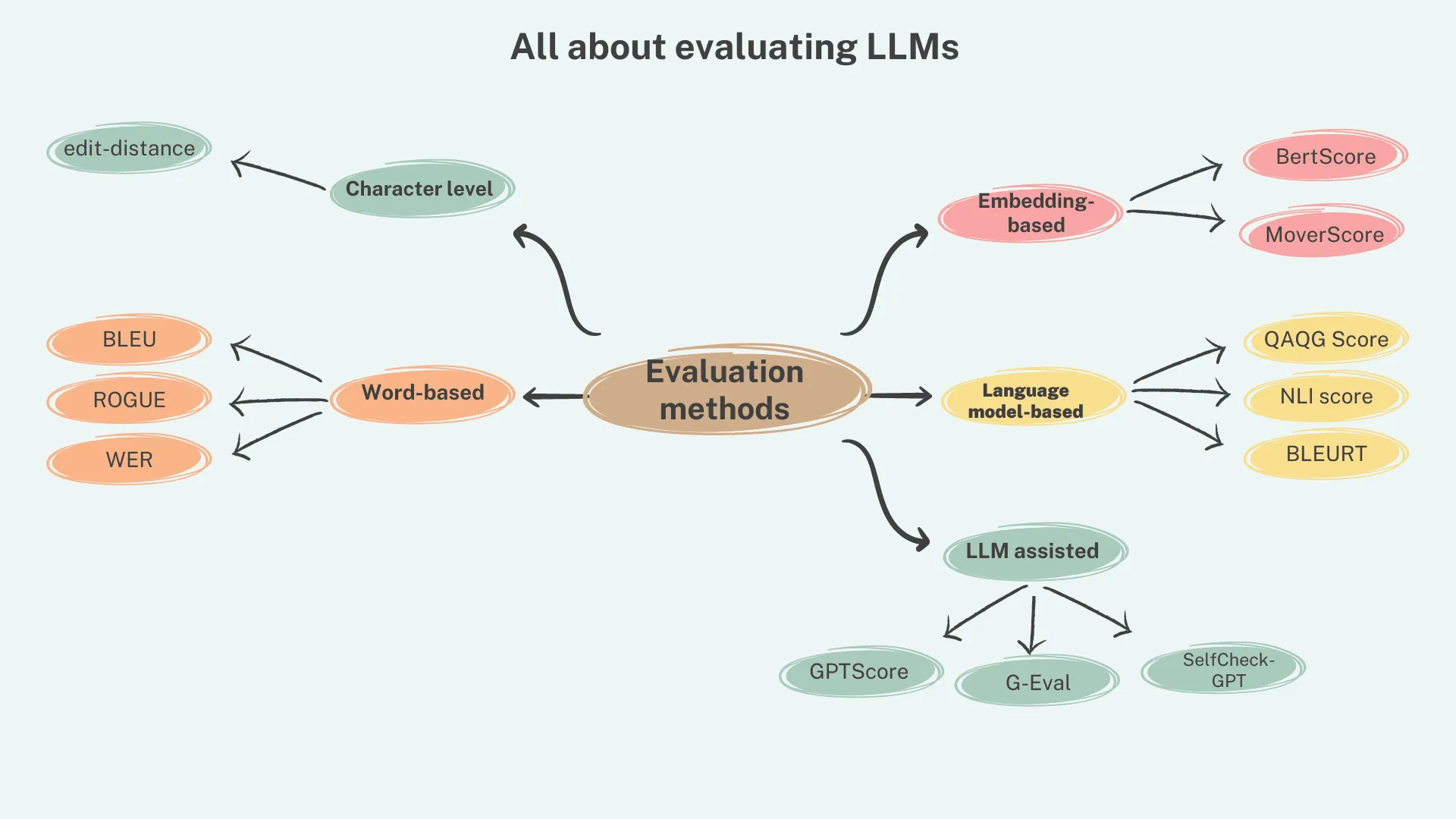
These tools rely on a wide range of metrics to assess how well an agent performs across key dimensions, including:
- Deterministic metrics:
- Cost
- Response time
- String presence
- Perplexity
- F-Score
- BLEU/ROUGE
- Probabilistic (model-based) metrics:
- Factual correctness
- Relevance
- Toxicity
For a comprehensive list, check out the Ragas guide on metrics.
Choosing the right metrics is crucial, but not enough. In addition to these automated metrics, agent developers often spend a lot of time doing human evaluation, mostly by inspecting samples of the agent’s output.
Some advanced tools, known as LLM-as-judge, grade agent outputs against a reference response, which can be written by a human or generated by a powerful LLM like Claude. You can even train smaller models to act as evaluators.
The Eval Process in Practice
Here is a step-by-step guide to evaluating an AI agent:
1. Build a Test Dataset
Gather or generate input data for the agent. Include diverse inputs, edge cases, and challenging scenarios that should reflect the agent’s use cases.
For instance, when building a summarization agent, the test dataset should include documents of varying lengths, topics, and writing styles. It could also contain documents that are difficult to summarize, or that contain misinformation.
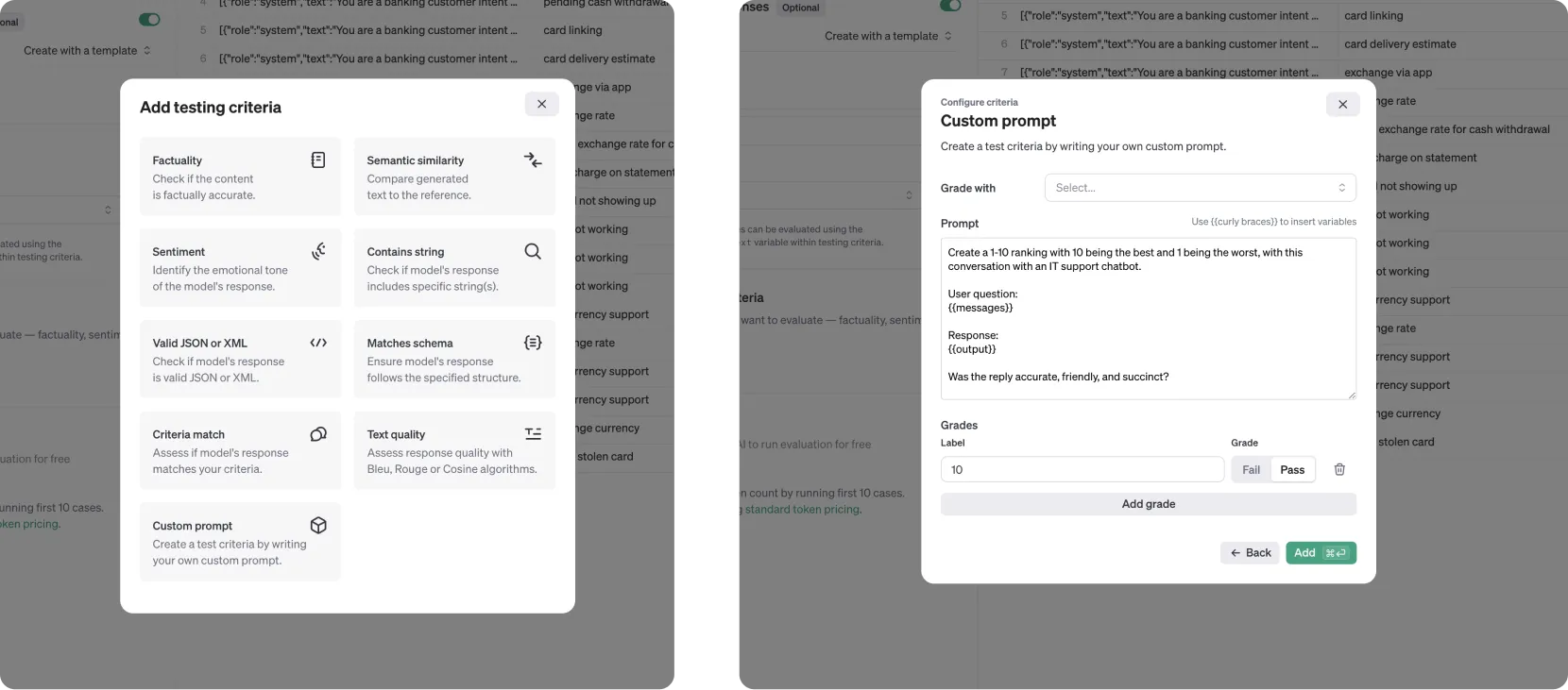
2. Select Metrics and Tools
Choose metrics that align with the agent’s requirements. For example, a summarization agent might be evaluated on metrics like ROUGE score, accuracy, completeness, summary size, response time, and cost per request.
You should also design a formula for the model grade, combining all metrics. This can be as simple as a weighted sum of the normalized metrics, like this:
model_score = a * factual_correctness - b * response_time - c * cost - d * sizeBuild the eval platform, which can range from a simple notebook to a fully automated workflow that runs thousands of evaluations in parallel.
3. Run the Agent on the Test Dataset
This will produce an output for every entry in the test dataset.
4. Compute Grade for the Run
For each output, calculate the metrics from step 2 using the eval platform. Then, calculate aggregate scores for each metric on the entire dataset using statistical measures such as mean, median, and percentiles. And finally, compute the model grade based on these metrics.
5. Update the Agent
Change the agent configuration one parameter at a time, so you can isolate the impact of each change.
Then, go back to step 3 and iterate until you find the best configuration.
Tips for Effective Eval
We’ve been doing eval for a while now, and we’ve learned a few things along the way. Here are some tips to make your eval process more effective:
Preparation
- Build for flexibility: Design your agent to allow quick testing of strategies with simple configuration changes. This approach will save hours of manual adjustments.
- Invest in the test dataset: Spend time building a diverse and robust test dataset. It should cover edge cases, tricky inputs, and all critical requirements. If you spend 25% of your time here, consider it time well spent.
- Set clear goals upfront: Decide on the target score and priorities before you start optimizing. Without a clear goal, you may find yourself endlessly fine-tuning the agent.
Metrics and Evaluation
- Focus on essential metrics: Avoid tracking too many metrics at once—it will slow down your benchmarks. Since you may need to run evaluations thousands of times, pick the most relevant metrics.
- Test metrics first: Use a small dataset to validate model-based metrics early. You don’t want to waste time on metrics that don’t correlate with user satisfaction.
- Store results: Keep a record of all test runs, including the agent configuration, test dataset, and results, in a searchable index. This data will prove invaluable when debugging or optimizing the agent.
- Hunt for outliers: After each test run, examine edge cases and outliers. These often highlight critical issues or opportunities for improvement.
- Look beyond averages: Focus on distribution and percentiles rather than average scores. A good agent should perform well consistently, not just on average cases.
- Watch the variability: Pay attention to the standard deviation of metrics and scores. Ignore changes that aren’t statistically significant—they can mislead your optimization efforts.
Optimization and Monitoring
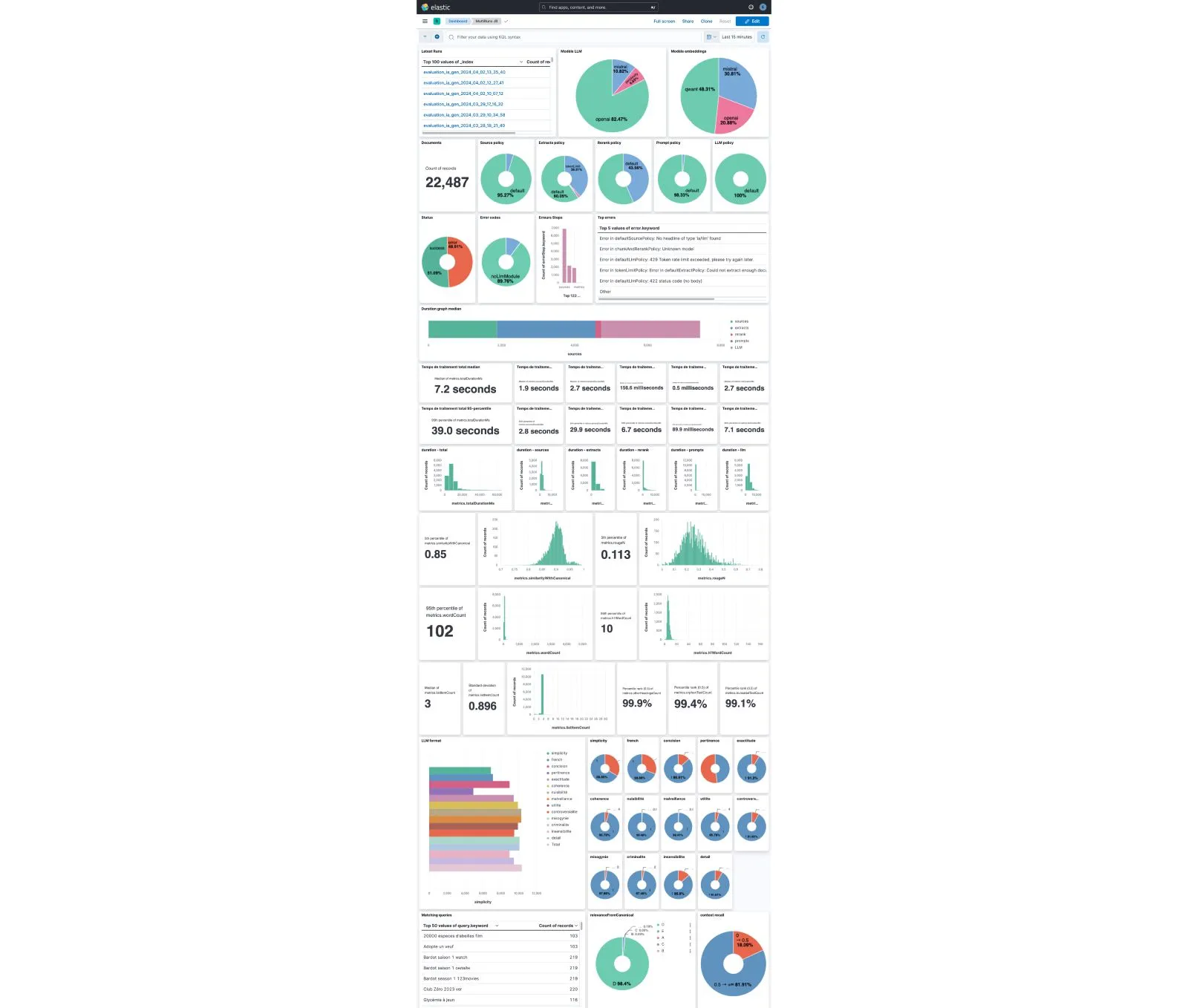
- Track and visualize progress: Use charts or dashboards to monitor your agent’s performance across runs. Clear visuals make it easier to spot trends and areas for improvement.
- Avoid over-relying on model grade: Aggregate scores are useful, but don’t tell the whole story. Set thresholds for key metrics and ensure the agent meets these requirements consistently.
- Explore the whole configuration space: Create a matrix of all possible configurations and test them systematically.
- Start strong, then optimize: Begin with the largest models to establish a quality baseline. Then, scale down the model size to cut costs and improve response time—but only if quality remains acceptable.
- Include production data: Once deployed, the agent will reveal new edge cases and challenges. Monitor its performance in production and feed this data back into your eval process.
Conclusion
The evaluation phase is crucial for building successful AI agents. Users can lose trust after a single failure, so finding the best configuration to optimize cost, speed, relevancy, and other factors is essential.
This process requires specific skills and tools that developers may not yet possess. Invest time in creating a robust test dataset, selecting the right metrics, and using the best evaluation tools. Although it’s a long journey, the effort is well worth it.
If you need assistance, don’t hesitate to reach out to us. We’ve already been through this process (e.g., for French Search Engine Qwant) and can help you optimize or debug your AI agent.
Authors
Marmelab founder and CEO, passionate about web technologies, agile, sustainability, leadership, and open-source. Lead developer of react-admin, founder of GreenFrame.io, and regular speaker at tech conferences.