Optimizing AI for Qwant: From Prototype to Production

Qwant is a French search engine focused on privacy, with 8 million daily users. They wanted to add AI-generated responses to their Search Engine Response Page (SERP). Testing and industrializing a large language model (LLM) based AI agent is challenging. They asked us to help them deploy it.
Process
Qwant engineers created a proof-of-concept AI agent for the SERP with multiple possible configurations (LLM vendors, models, prompting techniques, chunking strategy, etc.). They needed to identify the best configuration based on relevancy, speed, cost, and more.
We received access to their prototype and a sample of 10,000 queries. We split the core functionality into “policies” for independent evaluation. We built a testing framework to evaluate these policies, and a visual interface to let Qwant engineers compare results and find the best configuration.
Identified Problems
LLM responses are not deterministic, making “unit testing” impractical. Human evaluation is the best but is costly and slow, and automatic checks face issues like false positives and biases. Evaluating the relevancy of AI-generated responses is particularly challenging due to its subjective nature.
Configuration changes affect results in multiple, often opposing ways. Larger LLMs improve relevancy but increase cost and response time. Reranking reduces cost and improves relevancy but slows responses. There’s no single “best” setup; finding the best compromise is key.
Some configurations work well for certain queries but not others. For example, questions get good results, but simple keyword queries often need reformulation. Thus, large-scale evaluation is essential to identify where configurations fail.
Solution
We used Node.js to build a benchmarking engine that Qwant engineers could use to run tests on 10,000 requests quickly. A scheduler explored all possible configurations to find the best compromise. Metrics included heuristic-based and model-graded evaluations, leveraging state-of-the art tools like promptfoo, Ragas, and OpenAI Evals.
For relevancy, we tested various LLMs, including OpenAI’s GPT, Mistral, Meta’s models, and specialized ones from Hugging Face. A human assessment was conducted on AI-based evals to select the best models and prompts.
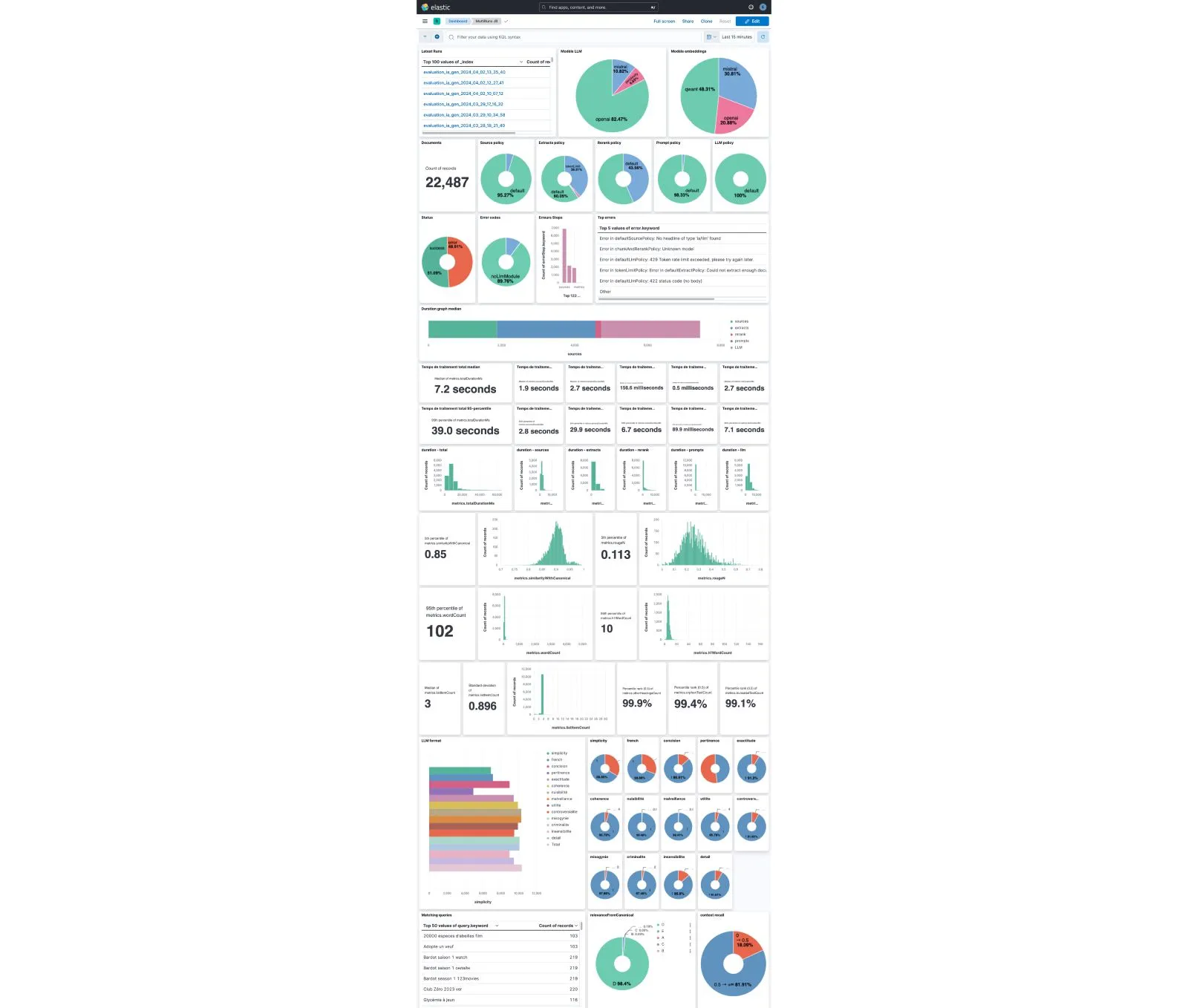
We used the ELK stack to store and visualize benchmark results. An interactive Kibana dashboard allowed Qwant engineers to view scores, identify outliers, and understand policy impacts.
Outcome and Benefits
We built the benchmarking engine in 2 weeks and ran it on all configurations over the next 2 weeks. In about a month, Qwant managed to identify the best configuration, deploy their AI agent to production, and collect usage signals.
Early satisfaction metrics show that the AI agent is well-received, with response relevancy matching top search engines. Costs are controlled, and response times are acceptable. The AI feature boosts usage metrics and user loyalty, making Qwant a preferred search engine for both general and specialized questions.
Qwant can now iterate and improve their AI agent over time using our benchmarking tool.
Conclusion
Programming a basic AI agent may take only a few days, but preparing it for production safely and efficiently is far more complex and costly. AI agent evaluation is a developing field with many challenges.
Speed and expertise were essential for this project. Our agile approach got the project off the ground in days, allowing us to pivot quickly when necessary. Leveraging our background in AI evaluation, we identified the best metrics and tools promptly. Our proficiency in Node.js and the ELK stack enabled us to create a powerful and efficient benchmarking engine in a short timeframe.
Have an innovative project? Let’s tackle it together!
Authors
Marmelab founder and CEO, passionate about web technologies, agile, sustainability, leadership, and open-source. Lead developer of react-admin, founder of GreenFrame.io, and regular speaker at tech conferences.