
Using NVIDIA GPU within Docker Containers

Diving into machine learning requires some computation power, mainly brought by GPUs. But I’m reluctant to install new software stacks on my laptop - I prefer installing them in Docker containers, to avoid polluting other programs, and to be able to share the results with my coworkers. That means I have to configure Docker to use my GPU. This is the story of how I managed to do it, in about half a day.
Introduction to NVIDIA Docker
I’m used to using Docker for all my projects at marmelab. It allows to setup easily even the most complex infrastructures, without polluting the local system. However, as image processing generally requires a GPU for better performances, the first question is: can Docker handle GPUs?
Looking for an answer to this question leads me to the nvidia-docker repository, described in a concise and effective way as:
Build and run Docker containers leveraging NVIDIA GPUs
Fortunately, I have an NVIDIA graphic card on my laptop. NVIDIA engineers found a way to share GPU drivers from host to containers, without having them installed on each container individually.
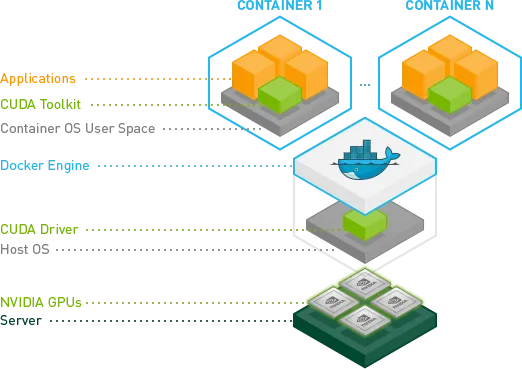
GPUs on container would be the host container ones. Looks promising. Let’s give it a try!
Installing CUDA on Host
CUDA is a parallel computing platform allowing to use GPU for general purpose processing. It is strongly recommended when dealing with machine learning, an important resource consuming task.
Does our Graphical Card supports CUDA?
The first step is to identify precisely the model of my graphical card. This is done easily on Linux using the lspci util:
lspci | grep VGA
00:02.0 VGA compatible controller: Intel Corporation [...] (rev 09)01:00.0 VGA compatible controller: NVIDIA [...] [GeForce GT 650M] (rev a1)So, I have a GT650M. Checking on NVIDIA commercial website, this card has CUDA support. Great so far!
Installing CUDA for NVIDIA Graphical Cards
Let’s follow the NVIDIA graphical card installation guide to install the latest version of CUDA. I am using Linux Mint 18.2, based on Ubuntu Xenial (16.04).
# Install NVIDIA repo metadatawget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.1.85-1_amd64.debsudo dpkg --install cuda-repo-ubuntu1604_9.1.85-1_amd64.deb
# Install CUDA GPG keysudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pubThis last step caused an issue because of the https protocol:
gpgkeys: protocol `https’ not supported
Fixing it is as easy as installing the missing package:
sudo apt install gnupg-curlNow I can install the cuda package the standard way:
sudo apt-get updatesudo apt install cudaAfter downloading and installing almost 3GB of data, I still need to perform some post-installation tasks.
Updating environment variables
First, I need to update some environment variables. I edit my ~/.bashrc file, and add the following lines:
# CUDAexport PATH="/usr/local/cuda-9.1/bin:$PATH"export LD_LIBRARY_PATH="/usr/local/cuda-9.1/lib64:$LD_LIBRARY_PATH"I then reload the environment variables using:
source ~/.bashrcNVIDIA Persistence Daemon
Then, I need to start the NVIDIA Persistence Daemon as the first NVIDIA software during boot process. The persistence daemon aims to keep GPU initialized even when no client is connected to it, and to keep its state across CUDA jobs. No precise idea why, but it is required.
I create a new /usr/lib/systemd/system/nvidia-persistenced.service with the following content:
[Unit]Description=NVIDIA Persistence DaemonWants=syslog.target
[Service]Type=forkingPIDFile=/var/run/nvidia-persistenced/nvidia-persistenced.pidRestart=alwaysExecStart=/usr/bin/nvidia-persistenced --verboseExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced
[Install]WantedBy=multi-user.targetThen, I enable this newly created service:
sudo systemctl enable nvidia-persistencedDisable some UDEV Rule
A udev rule (an interface between physical devices and the system) prevents NVIDIA driver from working properly. Hence, I need to edit the /lib/udev/rules.d/40-vm-hotadd.rules file, and comment the memory subsystem rule:
# SUBSYSTEM=="memory", ACTION=="add", DEVPATH=="/devices/system/memory/memory[0-9]*", TEST=="state", ATTR{state}="online"After a machine reboot, it is time to test my CUDA installation by compiling some of the provided examples:
cuda-install-samples-9.1.sh ~cd ~/NVIDIA_CUDA-9.1_Samplesmake
# take a book, go for a walk, or any other activity that takes time...
./bin/x86_64/linux/release/deviceQuery | tail -n 1Having Result = PASS shows that my CUDA installation is fully operational!
Installing NVIDIA Docker
Installing nvidia-docker is far easier than installing CUDA. First, I need to add the nvidia-docker dependencies:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \ sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get updateBefore installing nvidia-docker2 utility, I need to ensure that I use docker-ce, the latest official Docker release. Based on official documentation, here is the process to follow:
# remove all previous Docker versionssudo apt-get remove docker docker-engine docker.io
# add Docker official GPG keycurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# Add Docker repository (for Ubuntu Xenial)sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable"
sudo apt-get updatesudo apt install docker-ceNow that I have the last version of Docker, I can install nvidia-docker:
# Install nvidia-docker2 and reload the Docker daemon configurationsudo apt-get install -y nvidia-docker2sudo pkill -SIGHUP dockerdI now have access to a Docker nvidia runtime, which embeds my GPU in a container. I can use it with any Docker container.
Let’s ensure everything work as expected, using a Docker image called nvidia-smi, which is a NVidia utility allowing to monitor (and manage) GPUs:
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smiLaunching the previous command should return the following output:
+-----------------------------------------------------------------------------+| NVIDIA-SMI 390.12 Driver Version: 390.12 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. ||===============================+======================+======================|| 0 GeForce GT 650M Off | 00000000:01:00.0 N/A | N/A || N/A 72C P0 N/A / N/A | 554MiB / 4037MiB | N/A Default |+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+| Processes: GPU Memory || GPU PID Type Process name Usage ||=============================================================================|| 0 Not Supported |+-----------------------------------------------------------------------------+I now have access to the GPU from my Docker containers! \o/
Benchmarking Between GPU and CPU
It is time to benchmark the difference between GPU and CPU processing. I decided to look for a TensorFlow sample, as it can run either on GPU, or CPU. After some googling, I found a benchmark script on learningtensorflow.com:
import sysimport numpy as npimport tensorflow as tffrom datetime import datetime
device_name = sys.argv[1] # Choose device from cmd line. Options: gpu or cpushape = (int(sys.argv[2]), int(sys.argv[2]))if device_name == "gpu": device_name = "/gpu:0"else: device_name = "/cpu:0"
with tf.device(device_name): random_matrix = tf.random_uniform(shape=shape, minval=0, maxval=1) dot_operation = tf.matmul(random_matrix, tf.transpose(random_matrix)) sum_operation = tf.reduce_sum(dot_operation)
startTime = datetime.now()with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as session: result = session.run(sum_operation) print(result)
# It can be hard to see the results on the terminal with lots of output -- add some newlines to improve readability.print("\n" * 5)print("Shape:", shape, "Device:", device_name)print("Time taken:", str(datetime.now() - startTime))This script takes two arguments: cpu or gpu, and a matrix size. It performs some matrix operations, and returns the time spent on the task.
I now want to call this script using Docker and the nvidia runtime. I settled on the tensorflow/tensorflow:latest-gpu Docker image, which provides a fully working TensorFlow environment:
docker run \ --runtime=nvidia \ --rm \ -ti \ -v "${PWD}:/app" \ gcr.io/tensorflow/tensorflow:latest-gpu \ python /app/benchmark.py cpu 10000Executing this command twice gave me the following results:
- With GPU: 8.36 seconds
- With CPU: 25.83 seconds
That means using the GPU across Docker is approximatively 68% faster than using the CPU across Docker. Whew! Impressive numbers for such a simple script. It is very likely that this difference will be multiplied when used on concrete cases, such as image recognition. But we’ll see that in another post. Stay tuned!
Conclusion
Linking GPU to my Docker container has been a long (about a half day) and somewhat stressful process. Official documentation is straightforward. Yet, it doesn’t explain the purpose of each command. For instance, I had no idea of what was the NVidia Persistence Daemon when I installed it. I had to dig deeper in other parts of the documentation to get more information. And even now, I don’t have the full understanding of its purpose.
The most stressful moment was probably the required reboot, just after tweaking some /lib/* and /usr/* system files with some unfamiliar lines of text. I modified my host system after all, not a throwable Docker container. But everything worked well without any hassle.
As a final word, I highly recommend enabling the --runtime="nvidia" option. The performance boost is indubitable, even for a simple script. And I’m sure it will feel like a must-have once I’ll start to play with image classification.
Authors
Full-stack web developer at marmelab - Node.js, React, Angular, Symfony, Go, Arduino, Docker. Can fit a huge number of puns into a single sentence.