
Using AI To Autofill Forms With Wikipedia


How can we leverage the capabilities of LLMs to enhance user experience in existing web applications? One common pain point for users is entering data in forms based on external input. What if we could utilize AI to automatically populate form fields with data from a web source? In this blog post, we will demonstrate how to implement this concept in a TV series creation form using Wikipedia, OpenAI, and react-admin.
Here is the final result:
Getting Data From Wikipedia
To help users fill out the form, we’ll use Wikipedia in two steps:
- Search corresponding articles: The user enters the title of the TV series they want to create, and the app asks the Wikipedia API for a list of corresponding articles. For instance, if the user enters “Sherlock”:
curl --get 'https://en.wikipedia.org/w/api.php?' \-d action=opensearch \-d format=json \-d limit=10 \-d list=search \-d origin=* \-d search=SherlockThe user needs to select the series they want to use as a data source.
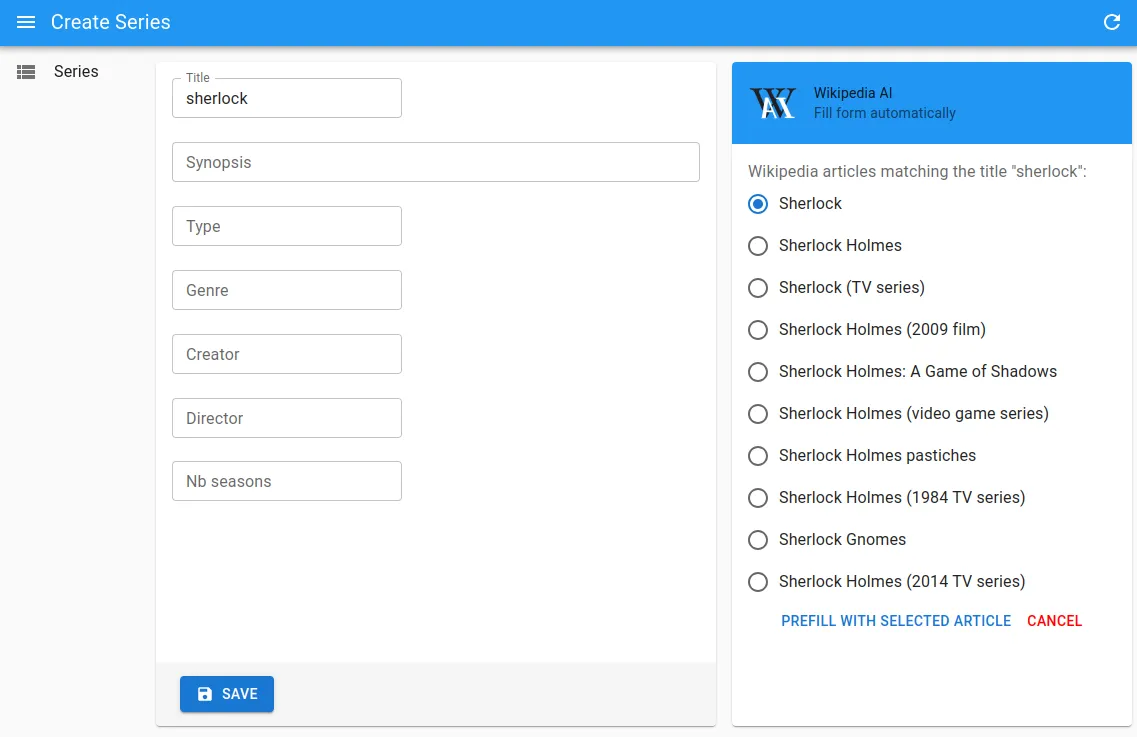
- Extract content from the selected article: Once the user selects an article, we use the exact page title to fetch the corresponding Wikipedia article:
curl --get 'https://en.wikipedia.org/w/api.php?' \-d action=query \-d explaintext=true \-d format=json \-d prop=extracts \-d redirects=true \-d origin=* \-d titles=Sherlock_%28TV_series%29Using the query parameters explaintext=true and prop=extracts, we retrieve a plain text version of the content from the Wikipedia page. This excerpt is already relatively optimized, it doesn’t have navigation, images…
Tip: To avoid CORS issues and enable cross-origin requests, Wikipedia recommends adding the query parameter origin=*. This request will be processed as if logged out (i.e as an anonymous user).
Abstracting The Wikipedia API
React-admin applications call APIs through their Data Provider, so we’ll add two custom functions to the Data Provider to retrieve information from Wikipedia. Nothing special here, it’s just a matter of calling the Wikipedia API with the right parameters and parsing the response. We’ll use the fetchJson function provided by react-admin to make the requests.
export const wikipediaDataProvider = { getWikipediaList: async (parameters = { search: "" }) => { const queryParams = new URLSearchParams({ action: "opensearch", limit: "10", list: "search", search: parameters.search, origin: "*", format: "json", }); const url = `https://en.wikipedia.org/w/api.php?${queryParams.toString()}`; const requestOptions = { method: "GET", headers: new Headers({ "Content-Type": "application/json" }), }; const { json } = await fetchUtils.fetchJson(url, requestOptions);
const data = json[1].map((title, index) => { return { title, url: json[3][index] }; });
return { data }; }, getWikipediaContent: async (parameters = { title: "" }) => { // ... },};These custom methods return only the necessary information for the application, such as the title and URL of the articles, without including the content.
Using An LLM To Extract Structured Information
We’ll craft a prompt that asks OpenAI to extract the fields we need from the Wikipedia excerpt. We’ll follow the best practices for prompt engineering by OpenAI to ensure the best results. Here is the prompt template we’ll use:
SYSTEM: You will be provided with a document delimited by triple quotes. Your task is to extract structured information from this document. Provide output in JSON format as follows: {"title":"...",...} The fields to extract are: [FIELD LIST] The value for each field should be a string or a number (no object as field value). Use \'null\' as value if the document does not contain the field. Do not add extra fields.USER: """[DOCUMENT]"""ASSISTANT:We’ll use GPT 3.5 Turbo to process the prompt as it’s the fastest and cheapest OpenAI model for this task.
When tested on on the OpenAI Playground with the “Sherlock (TV Series)” Wikipedia article, this prompt seems to work well:
{ "title": "Sherlock", "synopsis": "British mystery crime drama television series based on Sir Arthur Conan Doyle's Sherlock Holmes detective stories. Produced by BBC, Hartswood Films. Stars Benedict Cumberbatch as Sherlock Holmes and Martin Freeman as Dr. John Watson.", "type": null, "genre": "Crime, Drama, Mystery", "creator": "Steven Moffat, Mark Gatiss", "director": null, "nbSeasons": 4}But this approach quickly encounters limitations.
Hitting The Token Limit
In many cases, the OpenAI API returns an error because the prompt exceeds the input token limit.
What Are Tokens?
Tokens can be thought of as pieces of words. Before the API processes the request, the input is broken down into tokens. These tokens are not cut up exactly where the words start or end - tokens can include trailing spaces and even sub-words. Here are some helpful rules of thumb for understanding tokens in terms of lengths:
- 1 token ~= 4 chars in English
- 1 token ~= ¾ words
- 100 tokens ~= 75 words
Extracted from What are tokens and how to count them?
Large Language Models process text using tokens. The token limit depends on the model used. Here, we use the gpt-3.5-turbo-0125 model, which has a limit of 16,385 tokens. You can find more information about each model in the OpenAI Models List.
For example, for the Sherlock TV series Wikipedia article, the extracted text weights 41KB. The tokenized version counts about 9,000 tokens, which is under the limit.
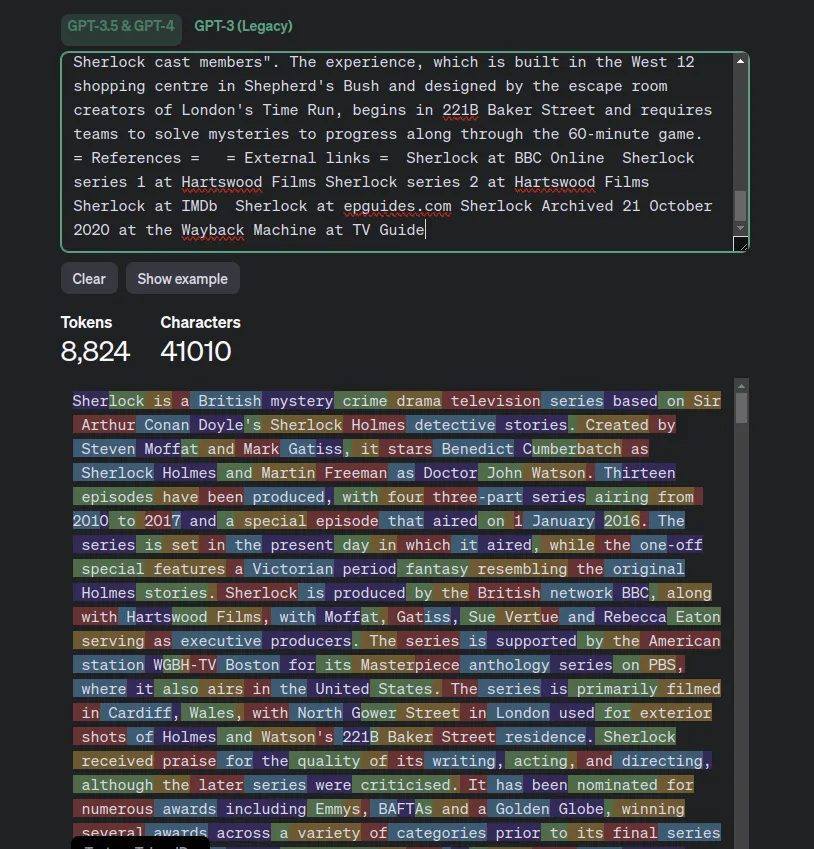
Tip: To count the number of tokens in a string, you can use the OpenAI Tokenizer page. They also provide an API for that.
But larger articles often exceed the token limit, and the OpenAI API refuses to process the request. And also, LLMs in general struggle to extract information from very large context. This is called “attention dilution”. As a consequence, the data extraction performs poorly on large articles.
Splitting The Document
A good rule of thumb for AI agents is that if they can’t execute a complex task in one go, they should break it down into smaller, more manageable tasks. For the data extraction task, we need to split the document into smaller parts and ask the LLM to fill in the fields for each part.
However, we encounter an additional challenge: there is no persistence of context between different requests to the OpenAI API. To address this issue, we decide to include the same list of fields we want to retrieve in each request, without sending the previous response. If the LLM finds a value for a field in a request, we use it. Otherwise, we keep the previous value. This simple approach allows us to aggregate the results from multiple requests in a fast way.
An alternative approach would be call the OpenAI API once more, after all the document fragments have been processed, to choose the best value for each field when several are available. But this would delay the response time and increase the cost of the request. We choose to keep the solution simple and efficient.
Therefore, we send each token group to the OpenAI API to retrieve relevant field values (such as title, type, number of seasons, etc.) in JSON format. As for other API calls, we implement this in the application Data Provider:
export const openAIDataProvider = { getOpenAIValuesFromContent: async (content: string, keys: [string]) => { const messageWithoutContent = `fields ${keys.join(',')}.text:`; const groups = tokenizeContent(content, messageWithoutContent); let result = {}; for (const group of groups) { const message = `${messageWithoutContent}${group}`; const data = await fetchOpenAI(message); const sanitizedData = removeNullUndefined(data); result = { ...sanitizedData, ...result }; } return { data: result }; }, // ...};Filling The Form
We use the setValue method of React-Hook-Form to update the form data with the retrieved values.
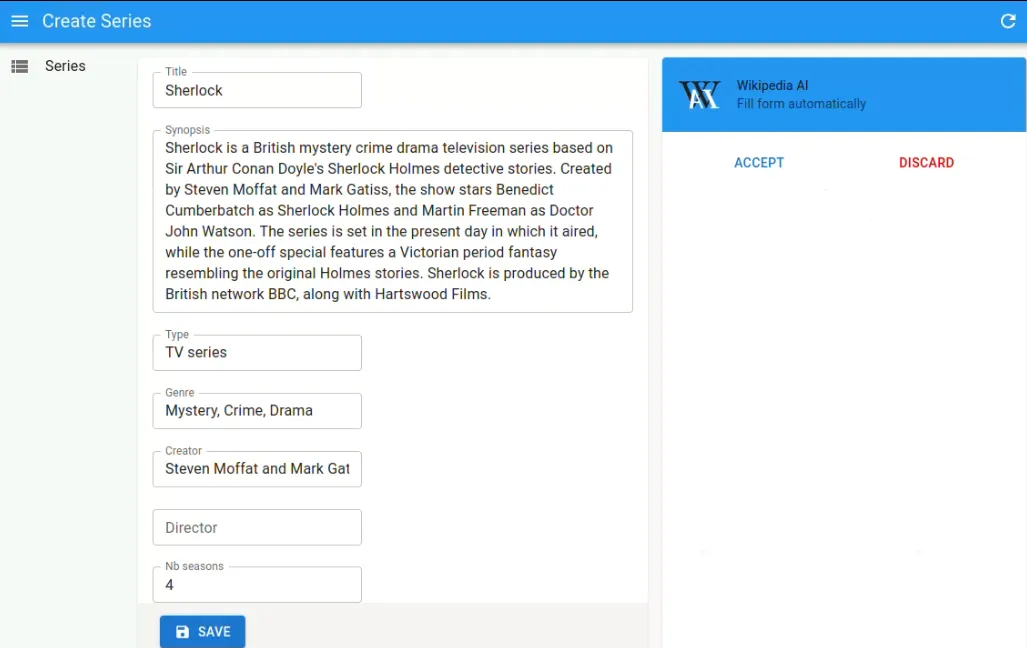
Since the AI agent may return bad data, we offer a way to discard the suggested values. This implies saving the current form values before using the AI agent and restoring them if the user decides to discard the suggestions.
Conclusion
This exploration has provided us with a better understanding of the challenges and opportunities associated with using AI to automatically fill out forms with data extracted from external sources such as Wikipedia. Although this approach is promising, we have encountered obstacles such as the high cost of requests to the OpenAI API and the variability of responses for the same queries.
We’ll explore more uses of OpenAI in forms during our next hack day. We’ll experiment with providing multiple suggestions for the same requirement. This experiment will lead to questions about assessing the LLM’s output quality, improving requests, and providing a user-friendly experience.

Authors
Before choosing full-stack development, Cindy was a dentist. No kidding. You can imagine that she's a fast learner.
Full-stack web developer at marmelab, Julien follows a customer-centric approach and likes to dig deep into hard problems. He also plugs Legos to computers. He doesn't know who is Irene...