
Comment j'ai remplacé mon patron par une IA

Différentes vidéos sur youtube traitant des IA et des deepfakes m’ont récemment amené à me poser quelques questions :
- Quel est le niveau de complexité de la création de ce type de données ?
- Comment les outils de génération disponibles fonctionnent-ils et dans quelle mesure s’intègrent-ils bien ?
- Et surtout : Est-ce que c’est à ma portée ?
Bon, c’est parti, je vais essayer de cloner François. Oui, François Zaninotto, mon patron !
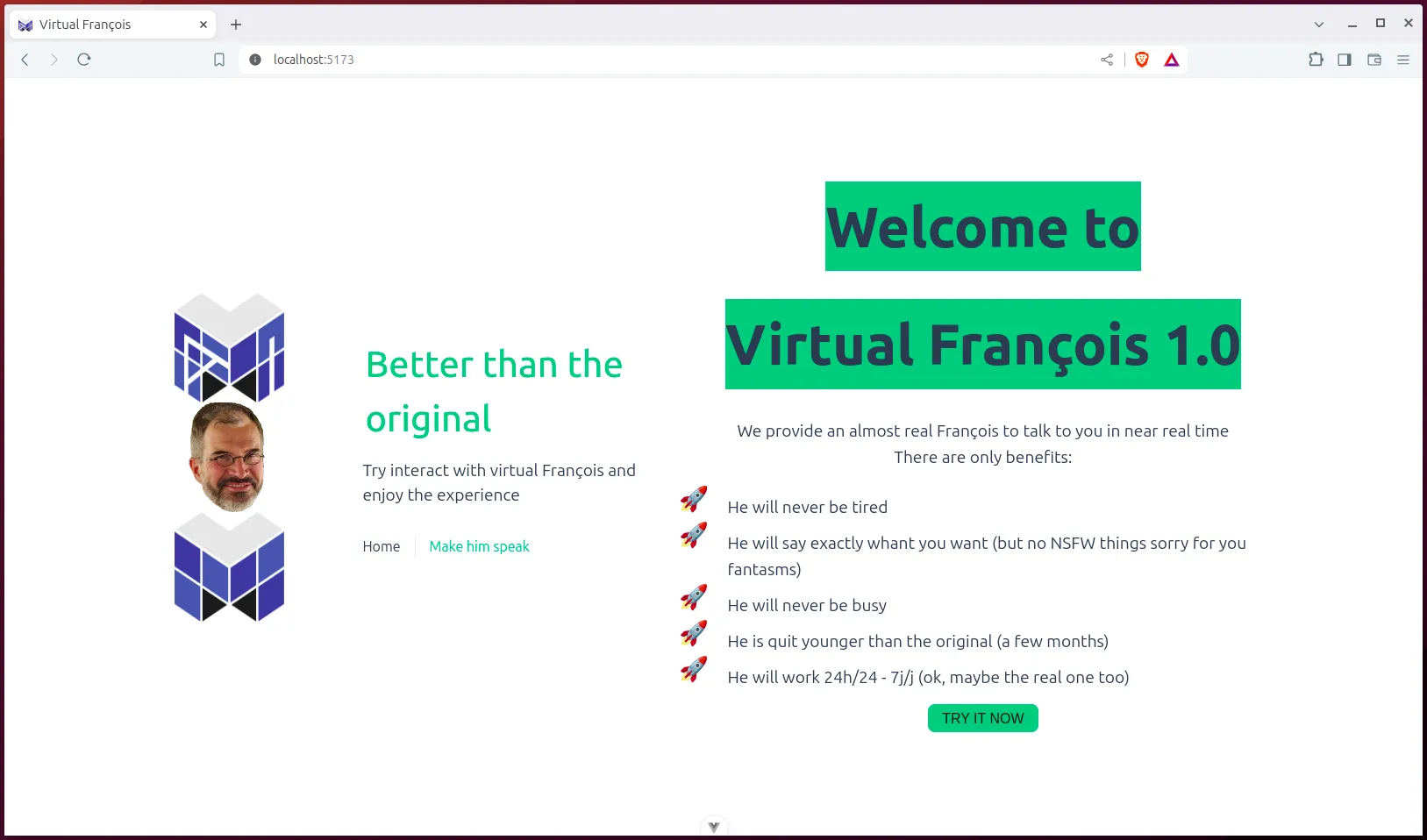
Spoiler alert : Oui, c’est définitivement beaucoup trop à ma portée !
Il n’est vraiment pas nécéssaire d’être une grosse célébrité pour risquer d’être la victime de deepfakes, une petite présence dans quelques médias sur la toile suffisent. Et nul besoin non plus d’être un ingénieur expert du domaine pour mettre en oeuvre le clone virtuel, les outils disponibles aujourd’hui rendent la tâche très accessible avec un minimum de technique.
Nous allons voir ça ici, du point de vue d’un dévelopeur web, garanti humain (je réussi les captchas haut la main).
Première étape : Cloner la voix
Eleven labs est là pour ça. Cette plateforme propose diverses fonctions de text-to-speech et speech-to-text. Par ailleurs, 10 minutes d’enregistrement suffisent au moteur pour générer un modèle assez bluffant de votre voix.
Attention, ces modèles personnalisés nécessitent un compte payant. Un euro par mois pour démarrer : qu’à cela ne tienne, le gag en vaut largement la chandelle.
Comme matière, je dispose de plusieurs heures de conférences données par François disponibles sur YouTube. Je vous conseille d’ailleurs, si le sujet vous interesse, l’excellente conférence Frameworks: A History of Violence qui m’a servi pour l’entrainement du modèle final.
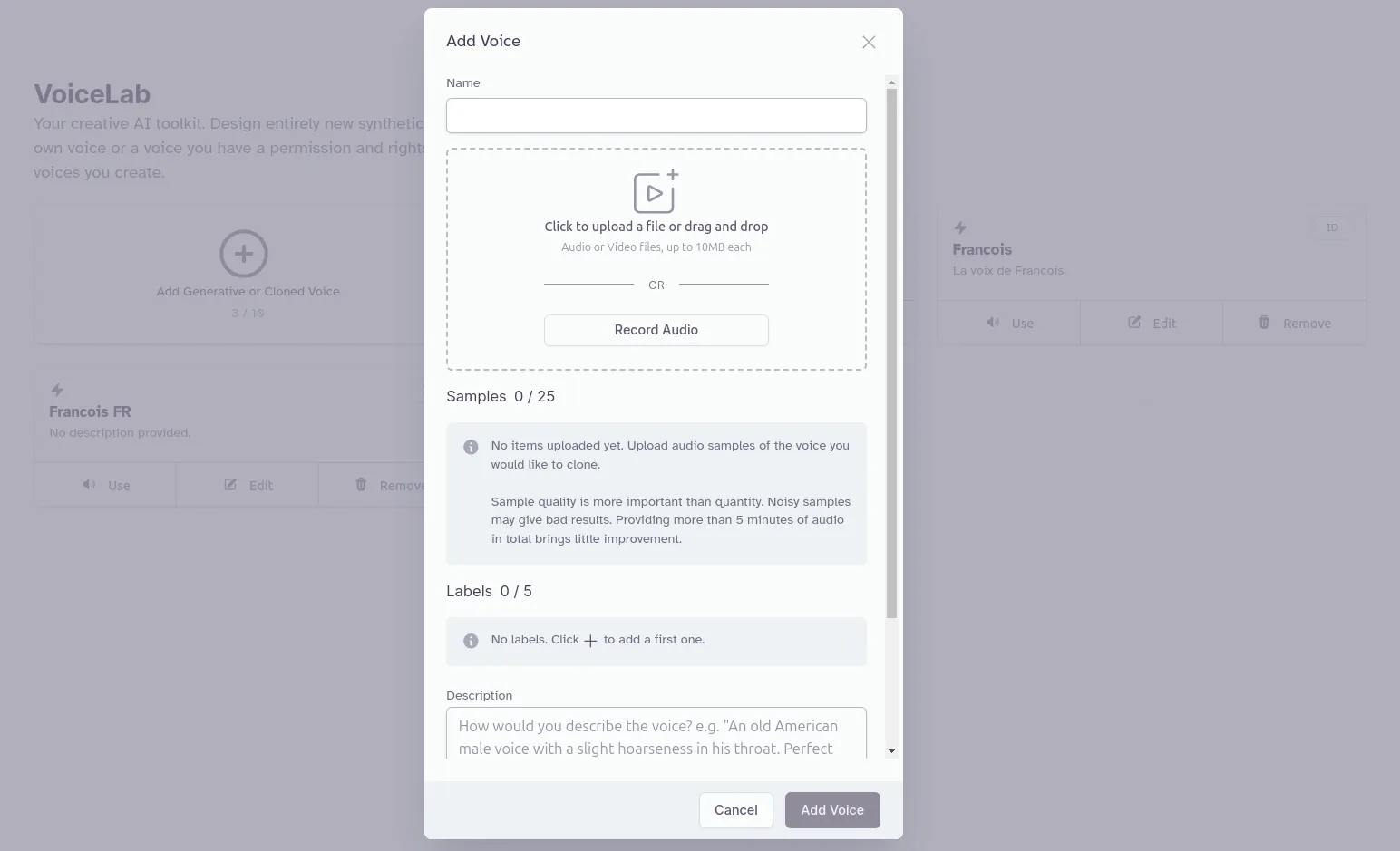
Au passage, j’ai pu constater que la langue d’origine d’entrainement joue un rôle non négligeable. La première source que j’avais choisie était la chaine youtube de react admin et les différents tutoriels de François en anglais sur ce sujet.
Le résultat obtenu était assez décevant lorsque je demandais au modèle de s’exprimer en français.
En changeant les données sources pour une vidéo en français, le test avec un ou deux collègues dans la confidence fut sans appel : bluffant.
Deuxième étape : Cloner l’image
Il me faut maintenant ajouter les gestes à la parole. Le processus à mettre en oeuvre est relativement simple : je vais utiliser un service de synchronisation labiale (Lipsync) qui permet, à partir d’une vidéo pré-existante, de modifier les mouvements de la bouche pour coller avec la parole désirée.
Je regarde rapidement Pika qui ne me convainc pas, puis je tombe sur Gooey.ai. Ce deuxième service dispose d’une interface assez pratique qui m’a permis de réaliser tous les tests de rendu manuellement. Et ensuite de mettre en oeuvre l’automatisation via leur API, facile d’accès et bien documentée.
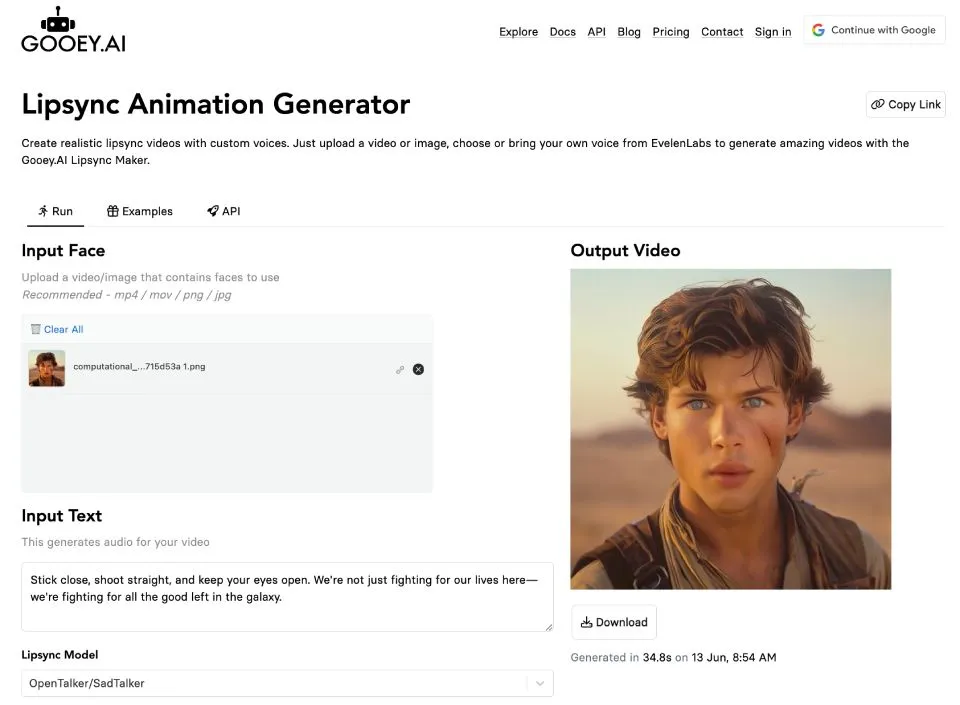
Le site possède aussi l’avantage de permettre de connecter directement son compte ElevenLabs pour utiliser un modèle de voix personnalisé à la volée.
Par contre ici, la tarification est plus subtile. L’inscription gratuite offre 1000 token utilisables (qui décrémentent à chaque appel, d’environ 5 à 10 token, variable). Mais l’utilisation de mon modèle personnalisé FrancoisFR sur ElevenLabs intégré necessite lui un compte payant (compter 100 token par minute).
A noter que Gooey est auto-modéré pour éviter un usage abusif, et qu’il bannit les termes litigieux dans les phrases en input, ce qui n’était pas le cas sur le synthétiseur d’ElevenLabs (ou moins restrictif en tout cas).
Gooey propose une API simple à utiliser. Voici un exemple de code pour appeler leur service :
export async function callGooeyAPI(text: string) { const payload = { tts_provider: 'GOOGLE_TTS', selected_model: 'Wav2Lip', elevenlabs_voice_id: 'aRbnx8H4l6WrxHI6iBBS', elevenlabs_api_key: process.env['ELEVEN_LABS_API_KEY'], elevenlabs_model: 'eleven_multilingual_v2', input_face: 'https://storage.googleapis.com/dara-c1b52.appspot.com/daras_ai/media/e3d155ea-0a4b-11ef-aee5-02420a00012b/LongMuteClip.mp4', text_prompt: text, };
const response = await fetch('https://api.gooey.ai/v2/LipsyncTTS/', { method: 'POST', headers: { Authorization: 'Bearer ' + process.env['GOOEY_API_KEY'], 'Content-Type': 'application/json', }, body: JSON.stringify(payload), });
return response; }Je trouve une vidéo de François contenant une séquence de discours face caméra d’une dizaine de secondes, parfait pour y appliquer la synchro labiale. Un petit peu d’édition vidéo pour extraire la bonne séquence en mp4, et à nouveau, je le teste avec un ou deux collègues : éclats de rire ; c’est un succès.
Troisième et dernière étape : L’appli web
Une fois les différentes données prêtes et calibrées, plus qu’a réaliser une interface pour les exploiter.
D’abord un front-end en Vue3 pour saisir le texte à lire et afficher automatiquement la vidéo fake comme si de rien n’était. Rien d’exceptionnel ici. J’aurait obtenu le même résultat aussi vite avec un framework React, mais ça a l’avantage de me changer du quotidien.
La CLI de Vue permet d’obtenir une application fonctionnelle très rapidement :
npm create vue@latestIl n’y a plus qu’a l’adapter à mes besoins :
<script setup lang="ts"> import { ref } from "vue"; import LoaderVideo from "../components/LoaderVideo.vue";
const defaultStatus = "STATUS READY"; const defaultText = "Salut, c'est François. ça getts mol ?"; const defaultVideo = "https://storage.googleapis.com/dara-c1b52.appspot.com/daras_ai/media/fab37ec6-0a4d-11ef-b722-02420a000123/gooey.ai%20lipsync.mp4";
const text = ref(defaultText); const status = ref(defaultStatus); const video = ref(defaultVideo); const loading = ref(false);
function sendText() { loading.value = true; status.value = "COMPUTING"; // Petite portion de code pour éviter de relancer un appel aux API à chaque chargement de la page avec le texte par défaut if (text.value === defaultText) { video.value = defaultVideo; loading.value = false; status.value = defaultStatus; return; }
fetch("http://localhost:3111/speak", { method: "POST", headers: { "Content-Type": "application/json", }, body: JSON.stringify({ text: text.value }), }) .then((response) => response.json()) .then((data) => { status.value = data.error || "STATUS OK"; video.value = data.video?.output?.output_video; loading.value = false; }) .catch((error) => { status.value = "GLOBAL ERROR"; console.error("Error:", error); loading.value = false; }); }</script><template> <div class="speak"> <LoaderVideo class="loader" v-if="loading" /> <video autoplay controls :src="video" type="video/mp4" :class="{ loading: loading }" /> <textarea autofocus rows="10" v-model="text"></textarea> <h5>{{ status }}</h5> <button @click="sendText" :disabled="loading">Ask Francois to speak</button> </div></template>Je choisis un ton léger pour l’interface plutôt que simuler un véritable chat de type google meet ou microsoft teams. Le but n’est pas de tromper quelqu’un mais seulement d’explorer ces outils sur un thème qui m’amuse. À cause de la facilité de mise en oeuvre, je veux éviter de faire de l’incitation à produire des deepfakes malveillants.
Sur ce genre de projet/POC rapide, j’ai pris l’habitude de m’affranchir totalement du back-end et des API pour tout intégrer dans le front-end servi au navigateur. Mais c’est inconcevable ici. En effet, bien que le rôle de l’API soit minimal (elle sert de passerelle entre le front et les services distants), j’ai besoin que mes clés d’API de ElevenLabs et Gooey soient cachées aux utilisateurs finaux, sans quoi le peu de crédit que j’ai acheté pour réaliser ce projet va disparaître en quelques minutes.
Je crée donc une API minimaliste avec express. Une simple route chargée d’appeler le service distant.
app.post('/speak', async (request: Request, response: Response) => { const { text } = request.body; const result = await gooeyAPI(text || 'Rien a dire');
if (result.error) { response.status(500).send(result); } else { response.status(200).send(result); }});Je sécurise tout ça avec un middleware de cors pour qu’un client lambda ne puisse pas exploiter l’API directement, et le tour est joué.
app.use(cors());Travail terminé
Résultat des courses : en plus ou moins deux jours passés à chercher des outils, les tester et les intégrer dans un système utilisable, j’ai pu, sans connaissance approfondie du sujet, mener à bien mon projet.
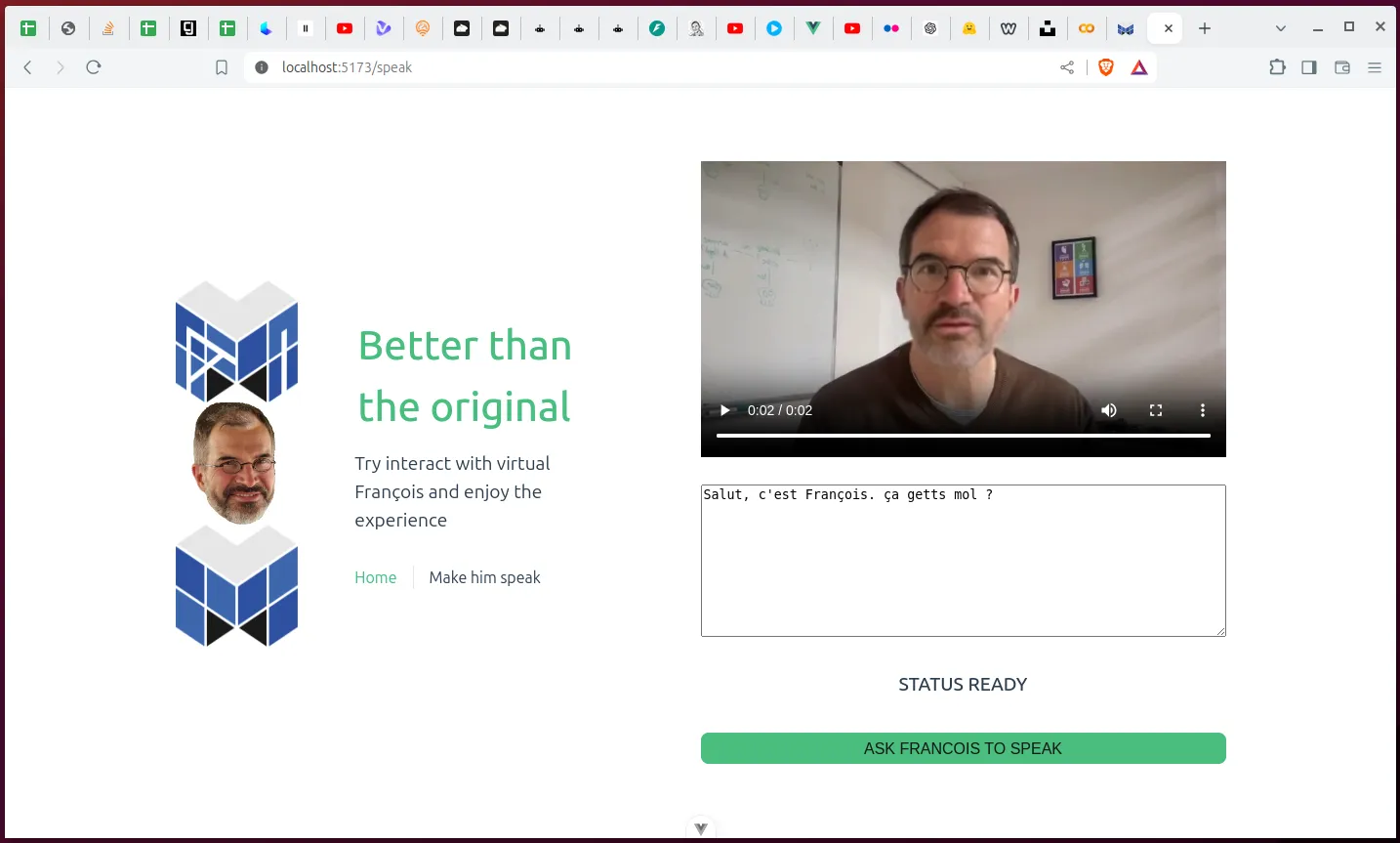
J’ai désormais un patron virtuel qui acquiesce à mes moindres requêtes sans broncher.
Prochain objectif : Le connecter au système de paye de Marmelab. Ça risque d’être plus compliqué, d’autant que François, le vrai cette fois, risque de ne pas se laisser faire si facilement :D
Quid de la vie privée ?
Le moins qu’on puisse dire, c’est que la technologie et la facilité de mise en oeuvre, à la fois fascinent, et font froid dans le dos. Alors qu’est-ce qui nous protège contre les utilisations malveillantes ?
En réalité, pas grand chose mais tout de même deux ou trois détails :
-
La plupart des plateformes telles que celles que j’ai utilisées signent leurs médias générés afin qu’ils puissent être identifiés comme fake au besoin.
-
Je pense également que le coût, bien qu’accessible pour des tests rigolos, reste assez dissuadant pour une arnaque à grande échelle.
-
Et enfin, en dernier recours, le droit est de notre coté. Car bien que j’ai utilisé pour mon projet, uniquement des vidéos publiques, toute utilisation de l’image et de n’importe quel attribut de la personnalité de quelqu’un, comme sa voix, sans son consentement explicite, reste totalement illégal et puni pénalement.
Bilan
Force est de constater à quel point les différentes technologies liées à l’IA sont devenues accessibles en peu de temps à travers de multiples outils de plus en plus performants. C’est assez satisfaisant pour un développeur web comme moi de voir que ce sujet n’est pas hors de portée, mais bien au contraire, parfaitement intégré à mon domaine. Les outils sont désormais techniquement aboutis, disposent d’API bien documentées et de communautés actives.
À mon niveau, le travail consiste donc à calibrer correctement les modèles, à concevoir l’application web et à interfacer les API entres elles.
La porte est finalement grande ouverte aux développeurs pour inventer et mettre en oeuvre les nouveaux services de demain que les LLM, synthèses vocales et autres modèles de diffusion, peuvent nous laisser entrevoir.
Ah, on m’alerte que le véritable François Zaninotto a eu vent de ma tentative de putch. Je ne sais pas si je vais pouvoir continuer… argh !
Message officiel de François Zaninotto
Je tiens à préciser que Julien va bien et qu’il est simplement parti en vacances. Il sera bientôt de retour, mais en visioconférence uniquement. Ne vous inquiétez pas si vous constatez un petit délai entre vos demandes et ses réponses, notre réseau se montre parfois capricieux.
Merci de votre compréhension.
Références
Les sources du projet sont ici :
Ainsi que les différents outils utilisés :
- ElevenLabs pour la synthèse vocale
- Gooey pour la synchronisation labiale
- AVI Demux pour l’édition de vidéo
Et voici également quelques vidéos intéressantes sur le sujet des deepfakes qui m’ont inspiré ce petit projet :
Authors
Full-stack web developer at marmelab, Julien follows a customer-centric approach and likes to dig deep into hard problems. He also plugs Legos to computers. He doesn't know who is Irene...