
GreenFrame: Calculating The Impact of Cache on MediaWiki Carbon Emissions

My mission at Marmelab is to help proof-test the GreenFrame project in order to improve its reliability. To accomplish this mission, my first quest was to use GreenFrame on a local Wikipedia instance. My work builds upon the first experiments carried out and explained in previous articles.
I have compared several configurations of a MediaWiki server, respectively with and without caches, and we found that caches play a major role in energy footprint - reducing energy consumption by up to 43%.
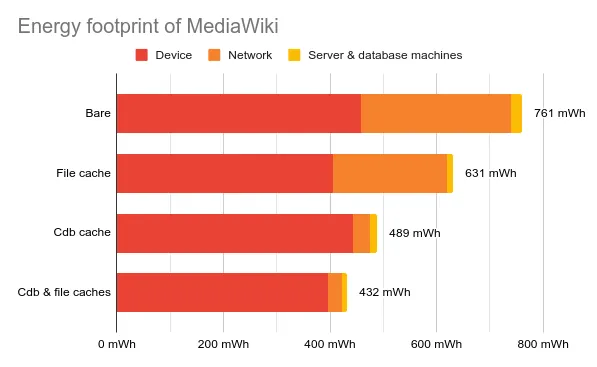
TL;DR Caches Downscale Network Emissions
For one visit to a typical Wikipedia article, GreenFrame shows that the energy consumption is roughly divided into two parts:
- 2/3 come from the user device
- 1/3 comes from the server and the network traffic
Adding a cache greatly reduces the network footprint and makes it almost negligible.
The figure below shows a summary of our experiments on Wikipedia, with and without cache. This result confirms our previous findings on the predominance of the user device on the energy footprint.
Here are the caching strategies we tested in this experiment :
- File cache: caching scheme storing rendered HTML pages for anonymous users. This optimizes page load time and HTML/CSS processing. This reduces load time, and therefore screen usage.
- Cdb cache: constant on-disk database storing translation of system messages. This optimizes data transfer between the server and the database. Translations are fetched from the database for every message by default if not cached.
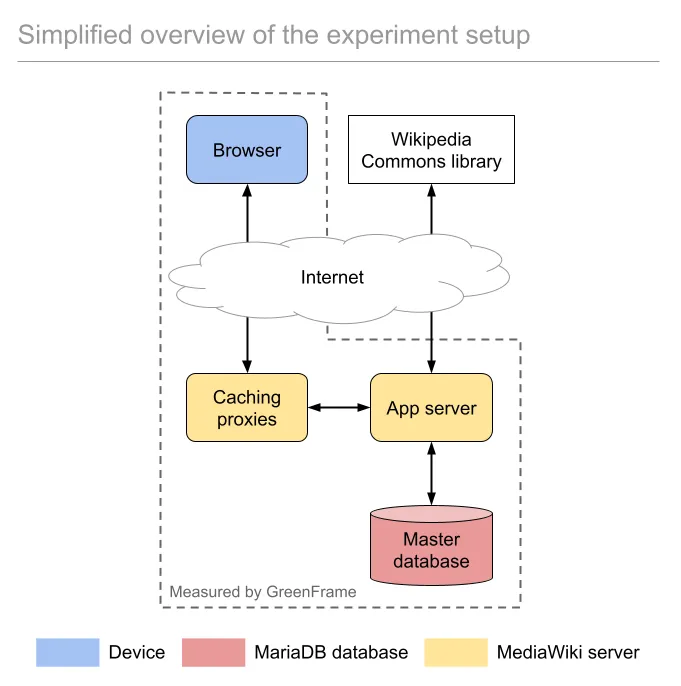
Establishing the Baseline
In order to build a point of comparison for the measurements of my experiment, I simply ran the numbers on the MediaWiki instance without any optimization.
Below is an overview of what that setup looks like.
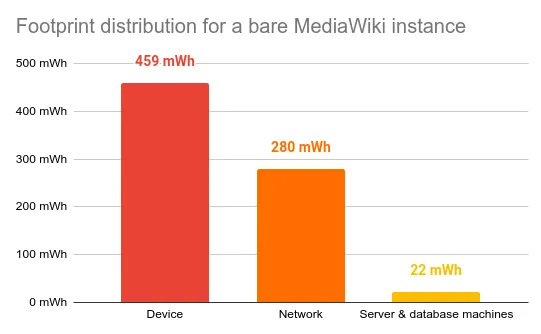
One visit to a typical Wikipedia article generates a footprint of 761 mWh, divided as follows:
- 60.3% comes from the user device
- 36.8% comes from the network
- 2.9% comes from the server and database machines
In our previous experiment, the network footprint was under 29% of the total. For a bare configuration, the network represents a bigger part of the energy consumption than before.
It’s important to note that this doesn’t represent the actual cost of a Wikipedia page. Our setup doesn’t reflect the production infrastructure and the various tweaks the Wikipedia ops achieved to optimize it.
Based on a 2GWh/year consumption and 295MRD page views over the last year, we can estimate that a Wikipedia article generates about 6.8 Wh/view.
Why does it deviate so much from our experiment? This can be explained by several factors:
- The yearly consumption of Wikimedia’s servers date from 2016, newer equipment get more energy-efficient as efforts intensify.
- Our model doesn’t account for server underutilization and only measures metrics for the duration of the scenario.
- Our model tends to underestimate real emissions. For example, estimated CPU consumption has the same order of magnitude as PowerAPI with a 20% gap.
This comparison is critical to challenge our understandings and fine-tune our model to provide the best tool possible.
Reducing Server-Database Transfers
Looking closely at the network part, I saw something unexpected: the exchanges between the server and the database consumed way more energy than the exchanges between the client and the server - even though our model uses a lower energy per GB ratio for server-side traffic.
Through experimentation, I found that the server communication with the database can vary from 3 to 20 times more than with the browser.
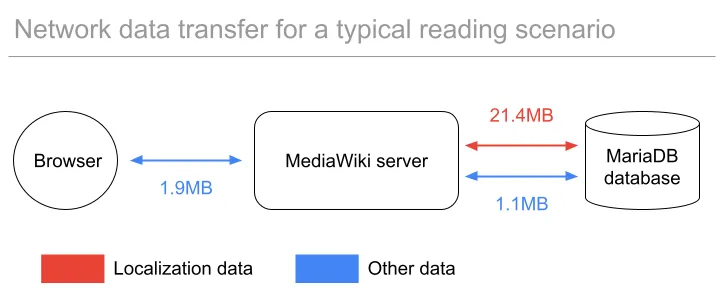
I looked closely at the database query logs, and found that the majority of requests comes from fetching messages from the localization cache. For example, visiting the Mathematics article generates over 1400 queries with more than half being pure localization queries.
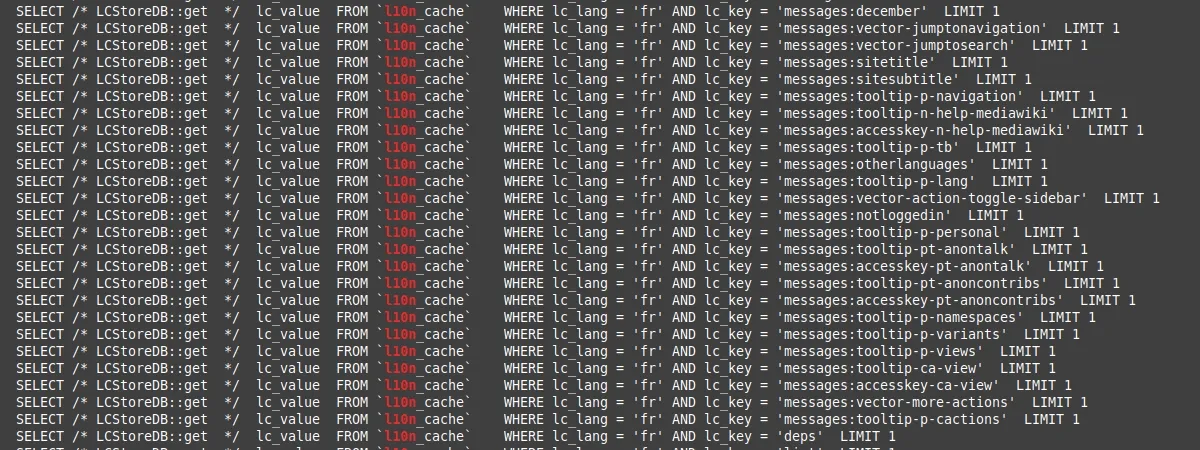
Localization data takes up to 88% of transferred data for a typical scenario. Since it changes very little over time, it makes sense for a cache to be set up and the impact on the energy footprint should be substantial.
So I added a CDB cache layer, as documented in the MediaWiki documentation. CDB stands for Constant on-disk database, it uses a file for storing key-value pairs in a fast and reliable way.
The gain was substantial: a cut by 90.3% of the network footprint.
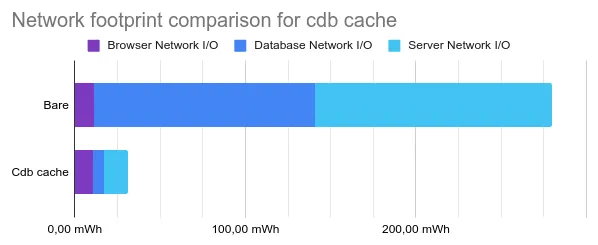
A server-side CDB cache completely removes these wasteful queries and greatly improves the network footprint as shown on the figure above.
Improving Device Footprint
I then added another cache layer: a file cache. This cache stores the articles as HTML files on the server side. That way, an article that has already been visited can be served directly.
The result is small but significant: a reduction by 11.7% of the device footprint.
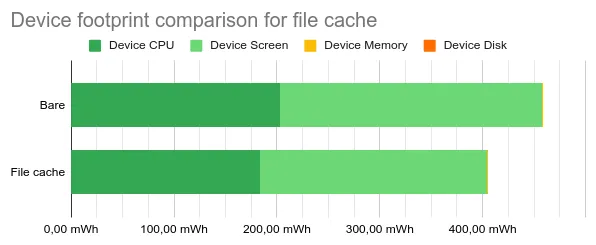
At first I thought that storing rendered HTML would help the browser not waste resources on rendering. It turns out CPU time is approximately proportional to the scenario’s duration.
But it does confirm something: the longer the user has to wait, the longer their device wastes energy.
Does Adding a Cache Increase the CPU Footprint?
Adding cache layers delegates network communication to cache calls. But this tradeoff raises the question: does it increase the CPU footprint?
The answer is: it doesn’t, and it even reduces it!
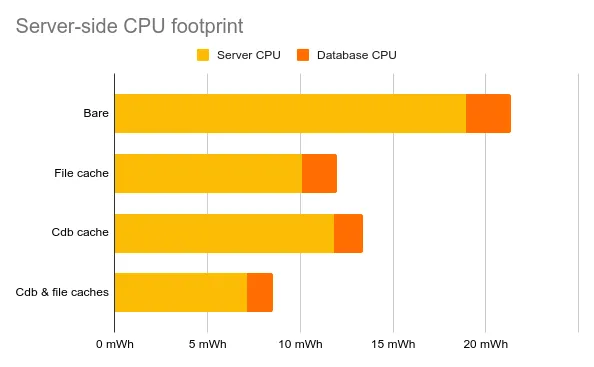
These optimizations are explained by the fact that the CDB cache greatly reduces the number of queries made to the database. The file cache does that as well but also prevents from repeating image fetches to the Wikimedia Commons library.
Since disk usage is far less energy intensive than querying the database, implementing such caches is an affordable way of improving the system’s energy consumption.
Editing An Article: A Burden On Server CPU
So far we’ve only tested a typical article reading scenario. Wikipedia being a collaborative platform, it is right to wonder how such a scenario compares to an article editing scenario. The figure below shows its impact on the server’s CPU.
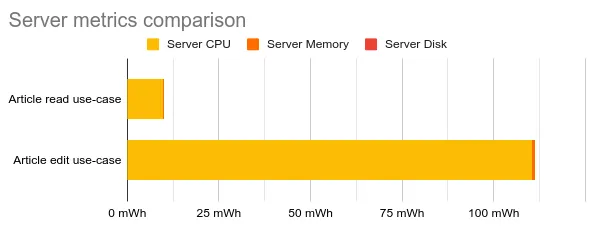
As the server and the database process the new content of the article, CPU time spikes up multiplying the resulting footprint by more than 10.
The same happens to the database CPU, but its consumption of 2 mWh is negligible. The amount of data on the network grows by the same amount as the size of the updated article, which is roughly 5MB at most.
Experimental Setup
Wikipedia Under the Hood: What Does It Look Like?
According to itself, Wikipedia is a free multilingual open-collaborative online encyclopedia that’s been with us since 2001. Today, it is available in more than 300 languages accounting for about 56 millions articles.
Being the gigantic community-driven knowledge base that it is, it is right to wonder how much energy such an infrastructure can consume for being able to keep up with the ~500 million daily page views.
Wikipedia is based upon the MediaWiki technology, which is an open-source wiki software platform based on the LAMP (Linux, Apache, MySQL/MariaDB, PHP) web stack. This base has been expanded to accommodate for heavy traffic and large volumes of data.
Setting Up A Dockerized MediaWiki Instance
At its heart, the stack is composed of two main parts: a MediaWiki server doing the bulk of the work, and a MariaDB database. This is what I’m going to implement.
I set up a docker-compose file to instantiate the server and database services, based respectively on the mediawiki and mariadb docker images.
version: "3"
services: mediawiki: image: mediawiki restart: always ports: - 80:80 links: - database volumes: - $HOME/volumes/mediawiki/images:/var/www/html/images database: image: mariadb restart: always ports: - 3306:3306 environment: MYSQL_RANDOM_ROOT_PASSWORD: 1 MYSQL_DATABASE: my_wiki MYSQL_USER: wikiuser MYSQL_PASSWORD: <censored> volumes: - $HOME/volumes/mysql/data:/var/lib/mysqlOnce the server is successfully launched, set the LocalSettings.php and the extensions folder as volumes of the mediawiki service in order to persist your server settings and to import extensions more easily. Since I’ve tempered with database settings, I found it useful to set the mariadb.cnf file as a volume as well.
For file transfer between the host and Docker, I found these commands incredibly useful :
docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATHdocker cp [OPTIONS] SRC_PATH CONTAINER:DEST_PATHOnce the server is launched with docker-compose, going to localhost redirects to the initialization menu that will generate the LocalSettings.php file for me.
To Infinite Knowledge And Beyond: Importing Articles From Wikipedia
On my way to copy the Wikipedia behaviour as closely as possible, I wanted to import existing Wikipedia articles in the locally hosted wiki server. Luckily for me, official Wikipedia content dumps are regularly made available to the public for free use.

Importing content dumps
I could find all the dumps needed in multistream format (as recommended by the documentation). The compressed dump of all articles is about 18GB. Considering my poor connection and the speed of the import script of about 4 pages per second, using a 230MB extract of about 27 000 pages is plenty enough for my experiment.
docker-compose -f path/to/docker-compose.yml exec mediawiki bash- Make the dump available to the container through a volume or with a
docker cpcommand cd maintenancephp importDump.php --conf ../LocalSettings.php path/to/dump.xml.gzphp rebuildrecentchanges.php
The import can take a while. Time for a tea break. 🍵
Importing Templates
Now a handful of articles are imported, but something doesn’t look quite right. A huge part of the look of articles is the use of Templates, a custom processing format to make the pages beautiful.
There are a lot of them and I haven’t found a way to import all of them at once. But I did iteratively import the ones I needed by checking which ones were missing, exporting them, and importing them locally the same way I did the content dumps. Remaining errors can be due to the lack of a wikibase set up.
If things didn’t look quite perfectly wiki-esque yet, I made sure the preparation requirements were fulfilled before carrying on.
Enabling Images
One last thing is missing to make an encyclopedia complete : images! That’s right, you wouldn’t want to read an encyclopedia full of text walls. As MediaWiki fetches images from the Wikipedia Commons library, activating images requires changing the $wgUseInstantCommons variable to true in the LocalSettings.php file. That’s it!
Setting Up Caches
To complete this setup with the caches presented in the article, I just needed to change the value of a few variables in the settings file :
- For the CDB cache :
$wgCacheDirectory="$IP/cache" - For the file cache :
$wgUseFileCache=trueand$wgFileCacheDirectory="$IP/cache"
I made sure the MediaWiki server had write permissions on the cache directory and it’s all good.
The Struggle Of Page Load Time Optimization
As I enabled images, page loading performance seemed to skyrocket up to 1 minute for certain articles. This behaviour is odd, so let’s attempt to fix it as it doesn’t represent a typical user scenario. You don’t usually wait a whole minute for your favorite celebrity’s page to show up.

It turns out MySQL is known for having performance issues when dockerized. While some solutions recommend disabling write barriers on the file system, I chose not to do it, as it can cause severe file system corruption and data loss in case of power failure. The SQL command OPTIMIZE TABLE is also sometimes used but didn’t help in my case.
I thought the issue might be caused by the laptop I use. Switching to a more powerful computer didn’t improve the situation but both machines run on the same Linux version. Benchmarks have shown that database systems perform differently based on the kernel’s I/O scheduler used. MariaDB is no exception and in fact performs best when using no scheduler. I made the change with the command sudo bash -c "echo none > /sys/block/sda/queue/scheduler", but still no improvement.
As I went through the MediaWiki documentation, I found out that the use of Instant Commons imposes quite a workload on the server as each image fetch needs to finish before the first byte is sent out, which might explain the minute-long page load.
In the end, the use of CDB and file caches reduced that load time to under 10 seconds - I didn’t manage to optimize it further.
Conclusion
In this article, I’ve shown the measurement carried out by GreenFrame on a fully dockerized MediaWiki environment. This confirmed some of the first results obtained on four different implementations of the same app but also pointed out the significance of network transfers on the energy consumption of a more complex architecture. The latter can quickly become dangerous if neglected and caches are a powerful tool to optimize the flow of data and its footprint.
Optimizing such a complex infrastructure is essential to achieve sustainability. It is part of the Wikimedia Foundation’s mission who has long been focused on reducing their own footprint.
The Wikipedia Commons being an online library, our solution was not able to gauge any metrics for that component although it is responsible for hosting and distributing files.
It is still a very promising milestone for GreenFrame, as it paves the way to a better understanding of more sophisticated systems and the ability to compare different scenarios.
Use GreenFrame.io now to estimate the carbon footprint of your website. It’s completely free! You can contact us if you want to use the core GreenFrame technology on your projects.
Authors
Full-stack web developer at marmelab, Antoine can detect a one pixel shift in a web page. He is also passionate about basketball.