
Convertir un projet Docker Compose en Kubernetes, partie 2

Introduction
Cet article prolonge notre découverte de Kubernetes, initiée dans la partie 1.
Nous y avions mis en place un cluster K8s local et configuré une application pour qu’elle puisse s’exécuter dedans. Nous allons réutiliser ce travail pour explorer plus en profondeur K8s.
Nous détaillerons ensuite les étapes requises et développerons quelques réflexions pour une utilisation de cet outil en production.
Réplication des pods
Kubernetes permet la création de plusieurs instances d’une même application, en les faisant fonctionner sur des machines (physiques ou virtuelles) différentes pour en améliorer la disponibilité.
Essayons de bénéficier de ce mécanisme. Pour cela on peut soit définir un replicaSet via un nouveau fichier, ou bien (et c’est la façon recommandée) directement configurer la réplication via le deployment.
Augmentons le nombre de pods (instances) que nous souhaitons voir coexister en modifiant le fichier nestjs-deployment.yaml :
spec: replicas: 1 replicas: 3 selector: matchLabels: io.kompose.service: nestjsUne fois n’est pas coutume, nous devons appliquer cette modification à la ressource présente dans notre cluster :
$ kubectl apply -f nestjs-deployment.yamlVérifions l’état de nos pods :
$ kubectl get podsNAME READY STATUS RESTARTS AGEnestjs-b7b95dc65-7tk4t 1/1 Running 0 6snestjs-b7b95dc65-dndbw 1/1 Running 0 40mnestjs-b7b95dc65-gpf9f 1/1 Running 0 6snginx-7cdb594897-9wjrc 1/1 Running 0 40mpostgres-84557f4db5-x8sc5 1/1 Running 0 40mOn voit bien que 2 nouveaux pods NestJS viennent d’être créés.
Dans le cas présent nous avons défini un nombre fixe d’instances souhaitées, le cluster va essayer de maintenir cette valeur au cours du temps.
Il est aussi possible d’adapter dynamiquement le nombre de pods déployés, et ce en fonction de métriques comme l’usage du cpu ou de la mémoire.
Cette adpatation dynamique peut même être étendue en créant nos propres métriques pour faire face par exemple à une hausse ou baisse subite de la demande. On doit alors utiliser un horizontal pod autoscaler. Pour en apprendre plus, vous pouvez lire la documentation.
État actuel vs état souhaité
La prise en compte de la modification de notre fichier nestjs-deployment.yaml (via la commande apply) a changé l’état souhaité du cluster.
Une boucle de contrôle scrute en permanence l’état actuel du cluster pour voir s’il correspond avec l’état attendu. Si ce n’est pas le cas, alors c’est à la charge de Kubernetes de réconcilier ces 2 états.
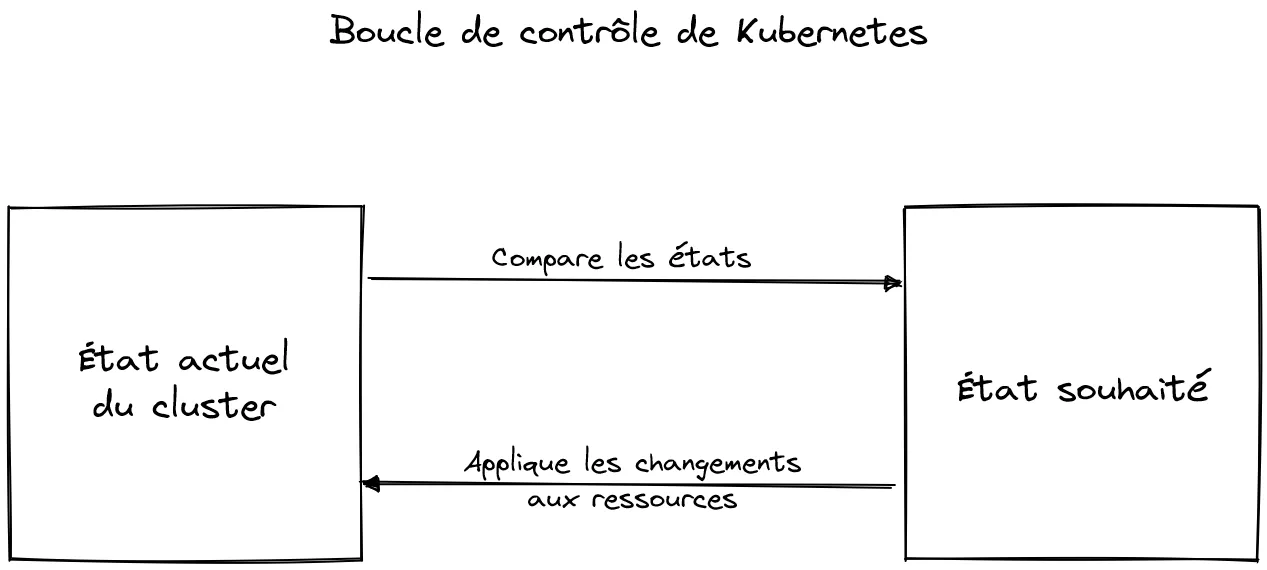
Forçons l’arrêt d’un pod pour bien mettre en exergue ce mécanisme automatique :
$ kubectl delete pod nestjs-b7b95dc65-7tk4tEn récupérant la liste des pods on voit bien qu’un nouveau pod a été créé pour remplacer le pod supprimé, et ça sans intervention supplémentaire de notre part.
$ kubectl get podsnestjs-b7b95dc65-7q8hg 1/1 Running 0 4snestjs-b7b95dc65-dndbw 1/1 Running 0 45mnestjs-b7b95dc65-gpf9f 1/1 Running 0 5m6snginx-7cdb594897-9wjrc 1/1 Running 0 45mpostgres-84557f4db5-x8sc5 1/1 Running 0 45mMise à jour de l’application
En plus de permettre de changer le nombre d’instances d’une application, K8s nous donne des outils pour gérer sa mise à jour, et même de faire fonctionner plusieurs versions simultanément.
Il existe 2 stratégies de mise à jour dans Kubernetes :
- rollingUpdate (mode par défaut) : les nouveaux pods sont créés puis les anciens sont supprimés, de sorte à garantir la continuité de notre service
- recreate : l’ensemble des pods sont supprimés puis les nouveaux sont créés
On va tenter d’appliquer la première stratégie. Pour mettre en exergue ce mécanisme, nous allons devoir augmenter le nombre de replicas et définir une valeur basse pour le paramètre maxUnavailable. Ce paramètre renseigne le nombre maximum de pods indisponibles durant une mise à jour rolling update.
Effectuons ces changement :
spec: replicas: 3 replicas: 10 selector: matchLabels: io.kompose.service: nestjs strategy: {} strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 0On peut vérifier que notre fichier est valide en utilisant l’option --dry-run, puis appliquer les modifications si tout est ok :
$ kubectl apply --dry-run=client -f nestjs-deployment.yamldeployment.apps/nestjs configured (dry run)$ kubectl apply -f nestjs-deployment.yamlAssurons-nous maintenant de connaître la version actuelle de l’image utilisée par nos pods :
$ kubectl get pods --selector=io.kompose.service=nestjs -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{":\t"}{range .spec.containers[*]}{.image}{", "}{end}{end}' | sortnestjs-b7b95dc65-hf6kz: atilbian/hex:0.0.1,nestjs-b7b95dc65-lqrsl: atilbian/hex:0.0.1,nestjs-b7b95dc65-m4hjf: atilbian/hex:0.0.1,nestjs-b7b95dc65-nvsz5: atilbian/hex:0.0.1,nestjs-b7b95dc65-qcw4t: atilbian/hex:0.0.1,nestjs-b7b95dc65-t6w57: atilbian/hex:0.0.1,nestjs-b7b95dc65-wpmsn: atilbian/hex:0.0.1,nestjs-b7b95dc65-x5rrq: atilbian/hex:0.0.1,nestjs-b7b95dc65-zfbcm: atilbian/hex:0.0.1,nestjs-b7b95dc65-zshq5: atilbian/hex:0.0.1Pour simuler une mise à jour de notre jeu de Hex, on va modifier son code source et publier une nouvelle version de l’image Docker.
L’image créée pour l’occasion : atilbian/hex:0.0.2.
Il suffit ensuite de référencer la nouvelle version de l’image dans le fichier nestjs-deployment.yaml :
spec: image: atilbian/hex:0.0.1 image: atilbian/hex:0.0.2 name: nestjs ports: - containerPort: 3000Puis on applique la modification et on récupère (dans la foulée pour voir le mécanisme de rolling update en oeuvre) les images utilisées dans nos pods :
$ kubectl apply -f nestjs-deployment.yaml$ kubectl get pods --selector=io.kompose.service=nestjs -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{":\t"}{range .spec.containers[*]}{.image}{", "}{end}{end}' | sortnestjs-6cf855c84-p645x: atilbian/hex:0.0.2,nestjs-6cf855c84-q8z57: atilbian/hex:0.0.2,nestjs-6cf855c84-qf6d9: atilbian/hex:0.0.2,nestjs-b7b95dc65-2pwgs: atilbian/hex:0.0.1,nestjs-b7b95dc65-56l9f: atilbian/hex:0.0.1,nestjs-b7b95dc65-kblk9: atilbian/hex:0.0.1,nestjs-b7b95dc65-kgh7w: atilbian/hex:0.0.1,nestjs-b7b95dc65-lhvvc: atilbian/hex:0.0.1,nestjs-b7b95dc65-nfjtx: atilbian/hex:0.0.1,nestjs-b7b95dc65-pn9nq: atilbian/hex:0.0.1,nestjs-b7b95dc65-s64vh: atilbian/hex:0.0.1,nestjs-b7b95dc65-sfbgn: atilbian/hex:0.0.1,nestjs-b7b95dc65-td52n: atilbian/hex:0.0.1,Bingo, on voit bien que la mise à jour s’applique de façon progressive !
Canary testing
Maintenant qu’on a appris à mettre à jour une application dans un cluster K8s, on peut essayer de faire fonctionner plusieurs versions simultanément.
Imaginons que nous aimerions que la moitié de nos utilisateurs utilisent la version 0.0.1, et l’autre moitié la version 0.0.2.
Pour cela, il faut dupliquer notre fichier de déploiement, et apporter les modifications suivante sur nos 2 fichiers :
- changer la version de l’image Docker utilisée (0.0.1 et 0.0.2)
- ajouter un label spécifique à chaque version (par exemple pour ma part j’ai ajouté le label
version: 0.0.1etversion: 0.0.2) - référencer le label spécifique à la version dans le
matchLabelsde la sectionspecpour relier chacun des déploiements à une version différente
Le code contenant ces changements se trouve dans cette branche.
Pour se simplifier la vie et partir sur une base saine, on peut faire un nettoyage brutal de l’ensemble des ressources du cluster grâce à kubectl delete all --all. Puis on peut recréer les ressources à partir des nouveaux fichiers. Vous devriez avoir 10 pods pour chacune des versions si vous repartez de la branche citée.
En requêtant plusieurs fois la page principale du jeu de Hex ($ curl localhost:32000) on peut voir qu’on accède de façon assez aléatoire aux 2 versions :
<head> <meta charset="utf-8" /> <title>Hex V2</title> <link rel="stylesheet" type="text/css" href="/css/style.css" /></head>...<head> <meta charset="utf-8" /> <title>Hex</title> <link rel="stylesheet" type="text/css" href="/css/style.css" /></head>...Notre canary testing fonctionne donc bien ! Cela peut sembler un peu magique. Mais c’est finalement assez simple. En fait, le service NestJS, sert de façade aux pods ayant le label io.kompose.service: nestjs, et c’est le cas des pods en 0.0.1 et 0.0.2. Le service reçoit donc notre requête et la distribue à un pod sélectionné de façon aléatoire.
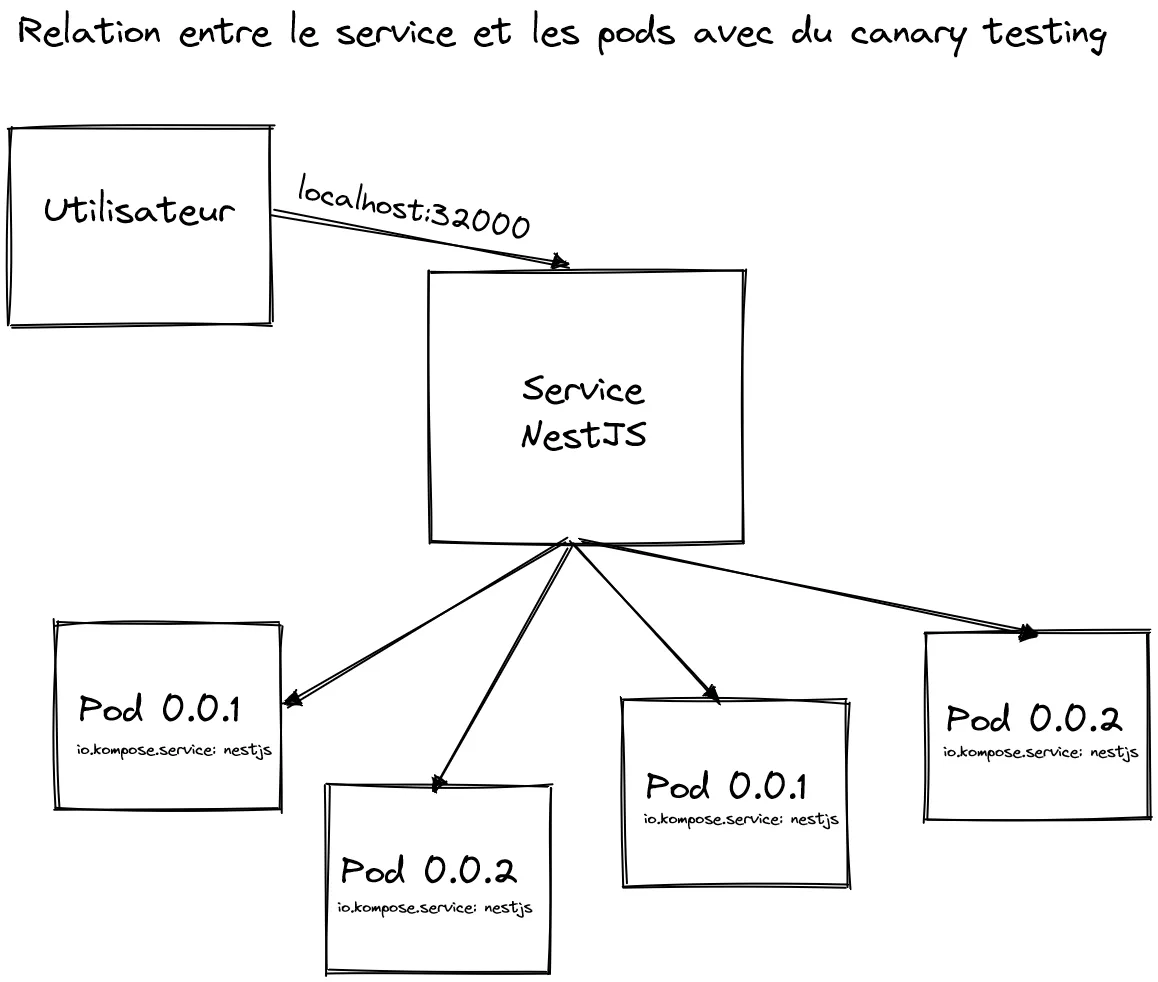
Bravo à vous, vous savez dorénavant exploiter 2 fonctionnalités clés de Kubernetes.
Gestion d’une application à état
La base de données doit pouvoir pérenniser son état au fil du temps, ce qui n’est pas le cas des couches NGINX ou NestJS.
Pour permettre la persistance des données, Kompose a exploité la définition du volume dans le fichier Compose pour créer une nouvelle ressource : PersistentVolumeClaim. Elle permet la consommation d’un espace de stockage permanent dans notre cluster.
Une autre différence importante est la nécessité de restreindre le nombre d’instance de notre base de données, pour éviter d’éventuels accès simultanés au volume permanent.
Cette restriction passe par la limite des replicas, fixée à 1, ainsi qu’à un changement de stratégie de mise à jour.
On peut constater cela dans le fichier postgres-deployment.yaml:
strategy: type: RecreateLa stratégie recreate force la destruction du pod existant avant la création d’un nouveau. Combiné à la limite sur le nombre de replicas, nous sommes assuré de cette façon d’avoir toujours au maximum une seule instance de notre bdd.
Il existe d’autres approches de gestion d’une base de données que celle utilisée par Kompose. D’ailleurs cette approche n’est pas forcément celle recommandée dans Kubernetes, la plateforme étant principalement outillée pour la gestion d’applications sans état.
Une alternative est d’externaliser l’hébergerment de la base de données, comme par exemple chez un fournisseur de services cloud. Permettant d’une part de réduire la complexité obligatoire à l’intégration de la BDD, tout en bénéficiant, sans effort supplémentaire, de différents services comme par exemple la gestion des backups, la réplication d’instances en lecture, etc..
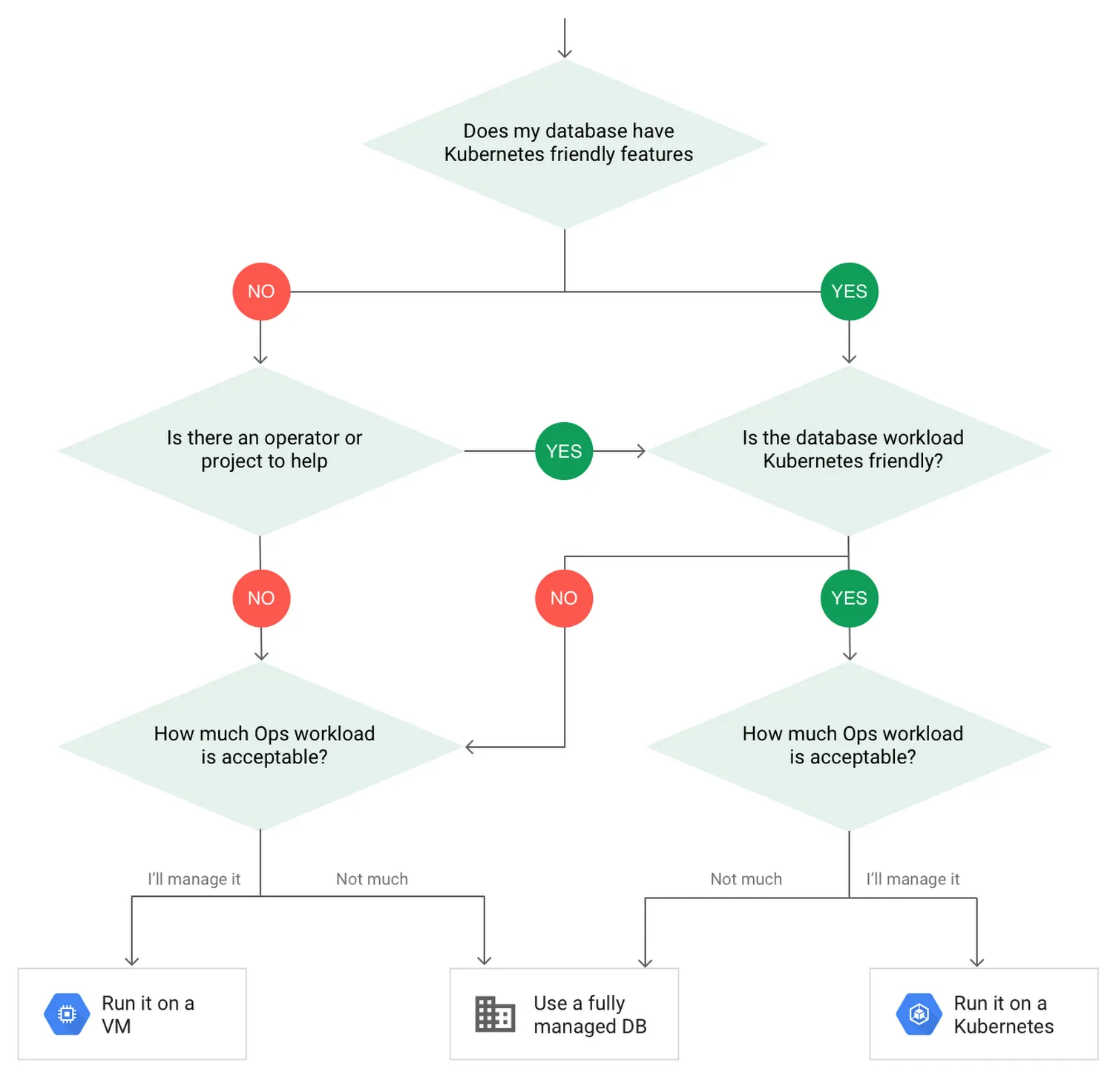
Je vous suggère de vous référer à cet arbre de décision, ainsi que lire l’article dont il est issu pour faire un choix éclairé.
Le cas du back-office
La gestion de notre back office React Admin, qui est une single-page application et donc une application web statique, n’a pas été traitée durant la première partie de l’article.
C’est normal, la conversion automatique n’a pas créée les ressources associées car aucun service correspondant n’est défini dans notre fichier Compose. En fait, nous avions fait le choix durant le développement de gérer son déploiement via le service Amazon S3.
Il existe d’autres solutions pour l’hébergement d’applications web rendues côté client, ou de sites statiques.
Par exemple, on peut créer une image Docker qui contient un serveur HTTP ainsi que l’ensemble des fichiers du site. On créera ensuite les ressources K8s adéquates pour permettre son exécution dans notre cluster.
Mais cette solution peut paraître surdimensionnée pour héberger des fichiers statiques. Il me semble pour ma part préférable de rester sur la solution initiale, c’est à dire l’externalisation de l’hébergement dans un CDN. Vous pouvez en apprendre plus en lisant mon article sur le sujet.
Pour aller plus loin
Nous avons survolé les concepts de base de Kubernetes, mais il y a encore de nombreux aspects à traiter pour un déploiement en production.
Voici une liste non exhaustive de sujets qui peuvent être approfondis (peut-être feront-ils l’objet de nouveaux articles, qui sait ?) :
- Migration vers un cluster dédié à la production, via un fournisseur cloud ou auto-géré
- Gestion de l’accès externe à notre cluster (via à un ingress)
- Optimisation de la taille des images Docker (lisez cette série d’articles)
- Intégration dans la CI/CD
- Gestion des logs
- Gestion des droits d’accès
- Surveillance de l’état des conteneurs (avec les startup, liveness, readiness probes)
- Packaging de notre application dans un chart Helm
Vous pouvez vous référer à cette checklist pour vous guider.
Conclusion
Nous avons découvert les bases de Kubernetes, mis en oeuvre un environnement local et migré dessus une application.
On a découvert en prime quelques fonctionnalités importantes que nous offre cet outil, notamment pour mettre à jour et gérer la réplication des pods.
Finalement on a pris du recul sur certains choix et chemins à suivre pour viser à terme une utilisation en production.
Alors maintenant que vous avez les fondamentaux, c’est à vous de poursuivre l’exploration !
Le code final se trouve ici.
Authors
Full-stack web developer at marmelab, Arnaud is a Software Engineer with a strong environmental conscience. He brews his own beer, which is a good way to prepare for the future.