
Tech F'Est : La conf de proximité


En juin avait lieu la toute première édition de la Tech F’Est à Nancy, une nouvelle conférence dédiée aux technologies et à l’innovation. Portée par des membres de l’AFUP Lorraine et l’Apéro Web Nancy, cette initiative vise à rassembler les passionné·e·s de tech de la région, mettre en lumière l’expertise locale et encourager les échanges.
Marmelab était présent pour découvrir l’évènement (spoiler : c’était super bien).
Les organisateurs nous ont installés dans l’amphithéâtre Botté de l’IUT Charlemagne où une petite nostalgie de nos études passées nous a quelque peu envahie, avant de céder place au sentiment agréable qu’une journée enrichissante s’annonçait.
La première particularité innovante que l’on à pu découvrir : tous les talks étaient retranscrits en direct par une transcriptrice, dont le texte était diffusé sur un écran dédié, afin de faciliter l’accessibilité de l’ensemble des sujets abordés.
On vous propose un petit retour sur les talks qu’on a préféré. (dans le but secret de vous convaincre de venir participer à Nancy à l’édition 2026).
- Embeddings : Transformation de la recherche d’information - Iana Iatsun
- Retour d’expérience sur la migration technique du code legacy - Arnaud Lahaxe
- Comment débuter dans l’accessibilité numérique ? - Emmanuelle Aboaf
- Comment scaler une integration Stripe à large échelle : une histoire de fiabilité - Kevin Maschtaler
- Façonner les architectures du futur avec Dapr - Christophe Gigax
Embeddings : Transformation de la recherche d’information
Ce premier talk a été présenté par Iana Iatsun, docteure en traitement d’images et du signal, et pionnière dans les réseaux de neurones.
Lors de cet échange, elle nous explique avec beaucoup de pédagogie et de talent comment l’IA a changé nos habitudes de recherche d’information et comment elle fonctionne pour nous fournir des réponses pertinentes.
Les moteurs de recherche ont évolués, utilisant initialement de simples index, jusqu’a des méthodes sémantiques aujourd’hui impliquant des embeddings (des vecteurs représentants les différentes dimensions des mots). Ce sont ces mêmes embeddings qui sont utilisés pour entraîner les modèles de langage (LLMs) actuels.
Ses exemples sont clairs et parlants : Le mot Pomme va avoir de multiple dimensions: type: fruit, gout: sucré, forme: ronde, couleur: rouge, etc. La comparaison de ces dimensions sous forme de vecteurs numériques permet de déterminer la proximité sémantique entre les mots.

Elle nous a également décrit précisément la phase de RAG (Retrieval-Augmented Generation) qui pose quelque défis comme la récupération d’informations à partir de documents volumineux : comment découper ces documents en morceaux pertinents pour les RAGs ? Ces segments (chunks) doivent être assez petits pour être traités efficacement, tout en étant suffisamment grands pour conserver le contexte et la signification.
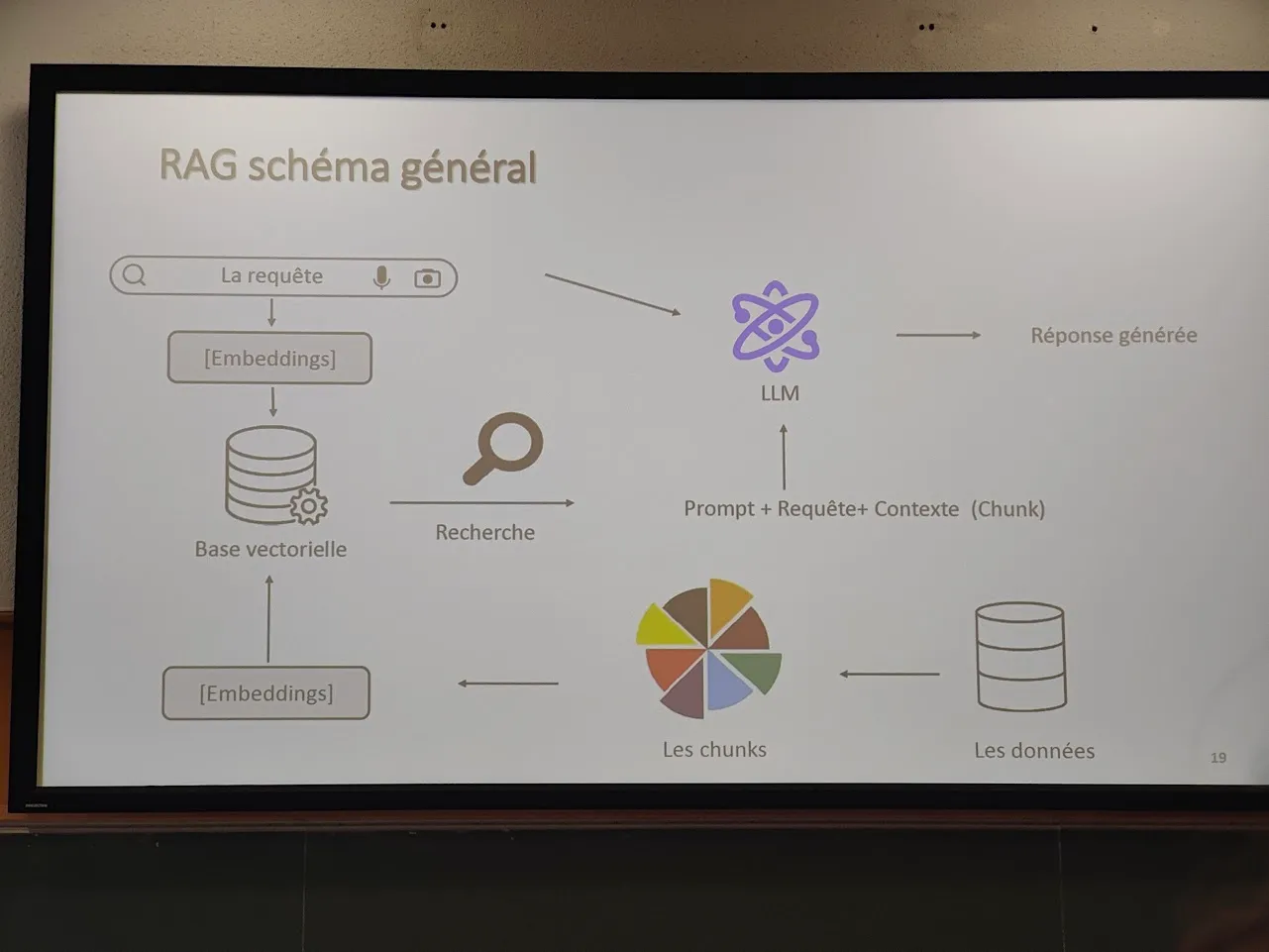
Cette notion de découpage des chunks offre une fascinante variété d’approches possibles :
- Par nombre de caractères : simple, mais peut couper des mots.
- Par phrases : risque de casser le contexte, surtout dans des documents mal structurés.
- Par paragraphes : mieux, mais peut manquer d’information clé entre paragraphes.
- Par fenêtre glissante : on découpe en segments de taille fixe, avec un chevauchement (ex : 1000 caractères avec un recouvrement de 200). Cela conserve le contexte.
- Approche sémantique : on utilise les LLMs pour détecter les segments logiques du document.
- Approche récursive : combinaison des méthodes précédentes pour maximiser à la fois cohérence, granularité et pertinence.
(Iana utilise principalement la fenêtre glissante aujourd’hui dans ses projets.)
Notre oratrice ne manquera pas de nous rappeler que les LLMs sont des outils puissants, mais qu’ils peuvent être biaisés. Elle l’illustre par l’exemple frappant d’un chatbot d’une compagnie aérienne ayant répondu à un client qu’il pouvait se faire rembourser son billet d’avion pour aller aux funérailles de sa grand-mère. La compagnie a refusé de rembourser, mais un tribunal finalement a jugé qu’elle était responsable de la réponse du chatbot et qu’elle devait rembourser le client.
On repartira de ce talk avec quelques bons conseils :
- L’IA a changé nos habitudes de recherche d’information, mais il est essentiel de l’utiliser de manière responsable.
- Les RAGs améliorent la pertinence et réduisent les hallucinations, mais nécessitent un bon découpage des documents et le choix d’une base vectorielle adaptée.
- Les embeddings sont un outil puissant, mais dépendent fortement du corpus d’entraînement. Il est donc essentiel que les données soient de qualité et représentatives.
- Les modèles de langage sont des outils puissants, mais ils doivent être utilisés avec précaution et responsabilité.
YouTube might track you and we would rather have your consent before loading this video.
Retour d’expérience sur la migration technique du code legacy
Arnaud Lahaxe nous a présenté son retour d’expérience sur la migration technique du code legacy chez BoursoBank, une banque en ligne française. Leur pôle de développement est localisé à Nancy et nos équipes à Marmelab ont régulièrement l’occasion d’échanger avec eux lors des différents meets locaux.
La migration de code legacy n’est pas le sujet majoritaire que l’on traite à Marmelab, ou nous travaillons souvent sur des projets innovants avec l’objectifs de faire leur preuve le plus rapidement possible. Mais c’est tout de même une tâche que l’on doit parfois accomplir, et les conseils d’Arnaud nous ont paru très pertinents.
On peut résumer son approche en quelques grandes étapes :
-
Comprendre l’impact de la réécriture du code legacy. Il est essentiel de savoir la criticité du code legacy et surtout ne pas créer de régression. Pour cela, il va utiliser les métriques existantes pour savoir si une partie de code est critique, voir même n’est plus utilisée. Il va également communiquer avec les utilisateurs pour collecter des informations et aussi communiquer les nouveaux usages du code migré.
-
Nettoyer au maximum le code legacy avant de le migrer. Il ne faudrait pas perdre du temps à migrer du code qui n’est plus utilisé. Mais aussi rendre le code plus lisible et compréhensible pour les développeurs qui vont travailler dessus.
-
Il faut faire des POCs (Proof of Concept) pour tester les nouvelles technologies et architectures. Et faire une implémentation minimale pour valider les choix techniques. Et bien évidemment utiliser des features flags pour activer ou désactiver les nouvelles fonctionnalités. Cela permet de tester les nouvelles fonctionnalités en production sans impacter l’ensemble de l’application.
-
Il est recommandé d’automatiser la migration du code legacy. En utilisant par exemple les AST (Abstract Syntax Tree). Il faut livrer petit à petit et ne pas attendre d’avoir migré l’ensemble du code pour livrer. On peut rapidement voir les impacts de la migration et corriger les éventuels bugs. Idéalement il ne faudrait livrer que de la configuration, par exemple en activant des features flags de la migration. Une erreur en production, on désactive le feature flag et on corrige le bug.
-
Il reste le plus satisfaisant : supprimer le code legacy. On a maintenant un code plus lisible, maintenable et évolutif, testé et documenté.
L’utilisation d’un tableau Kanban est également recommandée pour les différentes étapes de la migration. Les features ne sont pas oubliés et cela permets aux autres équipes de suivre l’avancement de la migration.
Tout cela tombe bien, ces étapes ressembles beaucoup à nos méthodes agiles pour mener à bien n’importe lequel de nos projets actuels au sein de Marmelab :
- Bien communiquer, pour bien déterminer les besoin et les impacts.
- Commencer par des POCs validant les points critiques.
- Livrer en cycle court avec des retours au furs et a mesure.
- Nettoyer à garder la code lisible.
- Et pour couronner le tout, Kanban est déjà l’un de nos outil de travail principal au quotidien.
Nous sommes sereins, la prochaine grosse migration de code legacy que Marmelab pourrai avoir à traiter devrait bien se passer.
YouTube might track you and we would rather have your consent before loading this video.
Comment débuter dans l’accessibilité numérique ?
Emmanuelle Aboaf de Shodo nous a présenté les bases de l’accessibilité numérique, un sujet crucial pour garantir que les sites web et les applications soient utilisables par tous, y compris les personnes en situation de handicap.
Elle connaît particulièrement bien son sujet, étant sourde de naissance, l’accessibilité n’est pas pour elle une simple passion, ou un concept mais c’est une véritable nécessité dont le manque est subi au quotidien. Ce sujet revient maintenant régulièrement dans les conférences, mais il a rarement été si bien incarné. Présenté à travers une petite session de live coding rafraîchissante, ce talk nous a permis de découvrir et redécouvrir un certain nombre d’éléments à mettre en place dans les pages web que nous développons pour éviter les “6 erreurs les plus communes”.
Nous allons essayer de les résumer ici. Pour vivre l’expérience complète, n’hésitez pas à regarder la vidéo du talk ci-dessous.
1. Attention au contraste
Pour garantir un bon contraste, utiliser l’inspecteur d’accessibilité de votre navigateur, outil devenu indispensable.
Un site utile pour aider a choisir et valider un jeu de couleurs : https://contrast-finder.tanaguru.com/
2. Attention aux lecteurs d’écran
Les lecteurs d’écran utilisent la lange définie de la page. Il faut donc être vigilent à bien la définir dans la balise html la langue réelle du contenu.
<html lang="fr">3. Attention particulièrement aux images pour les lecteurs d’écran
Les images sont décrites par les lecteurs d’écran en utilisant l’attribut alt.
Il est important de toujours fournir une description pertinente et complète de l’image dans cet attribut.
Un simple titre ne suffit pas pour que l’utilisateur comprenne le contenu de l’image.
4. Attention aux formulaires
Pour la validité des champs, ne pas véhiculer l’information uniquement par la couleur (vert ou rouge). Utiliser des icônes. Utiliser l’attribut “aria-describeby”
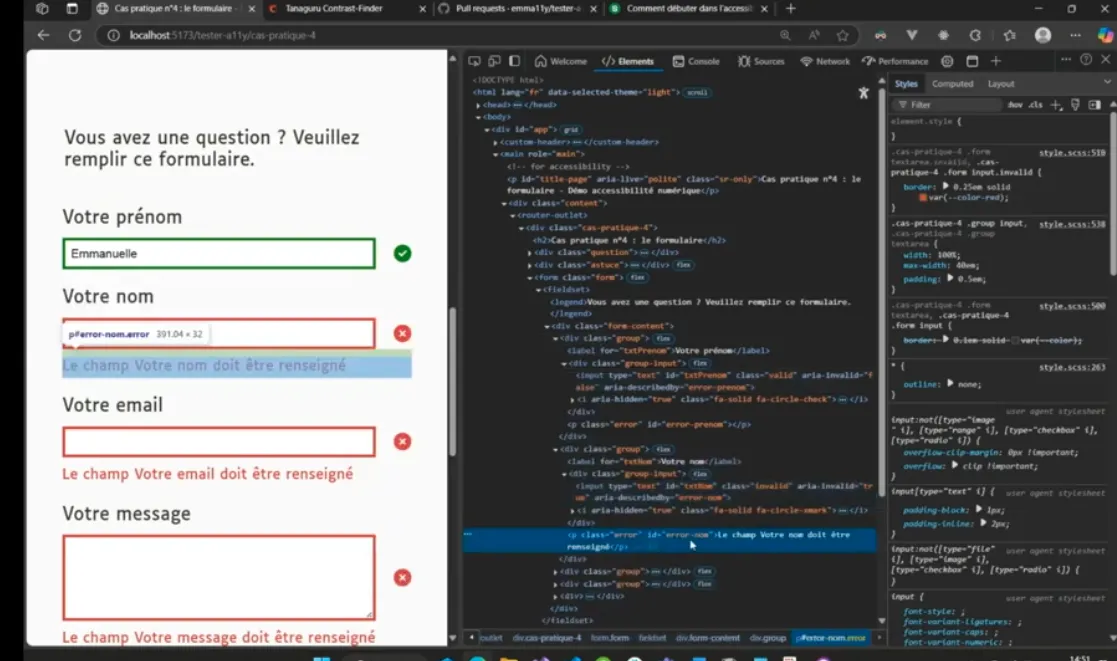
5. Attention aux boutons
Les boutons doivent toujours contenir du texte. Donc pour les icône boutons, ajouter au moins un texte en “aria-hidden”.
6. Attention aux liens Le label du lien doit être pertinent. Comme le dit Emmanuelle : “En savoir plus”,c’est une pochette surprise. Penser donc au “title” ou au “aria-label” encore une fois.
YouTube might track you and we would rather have your consent before loading this video.
Comment scaler une integration Stripe à large échelle : une histoire de fiabilité
Ce conférencier, Kevin Maschtaler nous est bien connu car c’est un ancien de Marmelab, parmi les premiers employés. La qualité de son travail et son talent pour expliquer des sujets techniques nous sont bien connus.
Son sujet du jour est assez simple à résumer : Les paiements en ligne sont compliqués car ils impliquent une quantité d’acteurs et d’étapes énorme (Ici il traite l’exemple de shotgun, une plateforme de billetterie pour le milieu des festivaliers). Considérant ça, quels sont les risques encourus par les clients et quelles sont les solutions techniques préventives à mettre en oeuvre ?
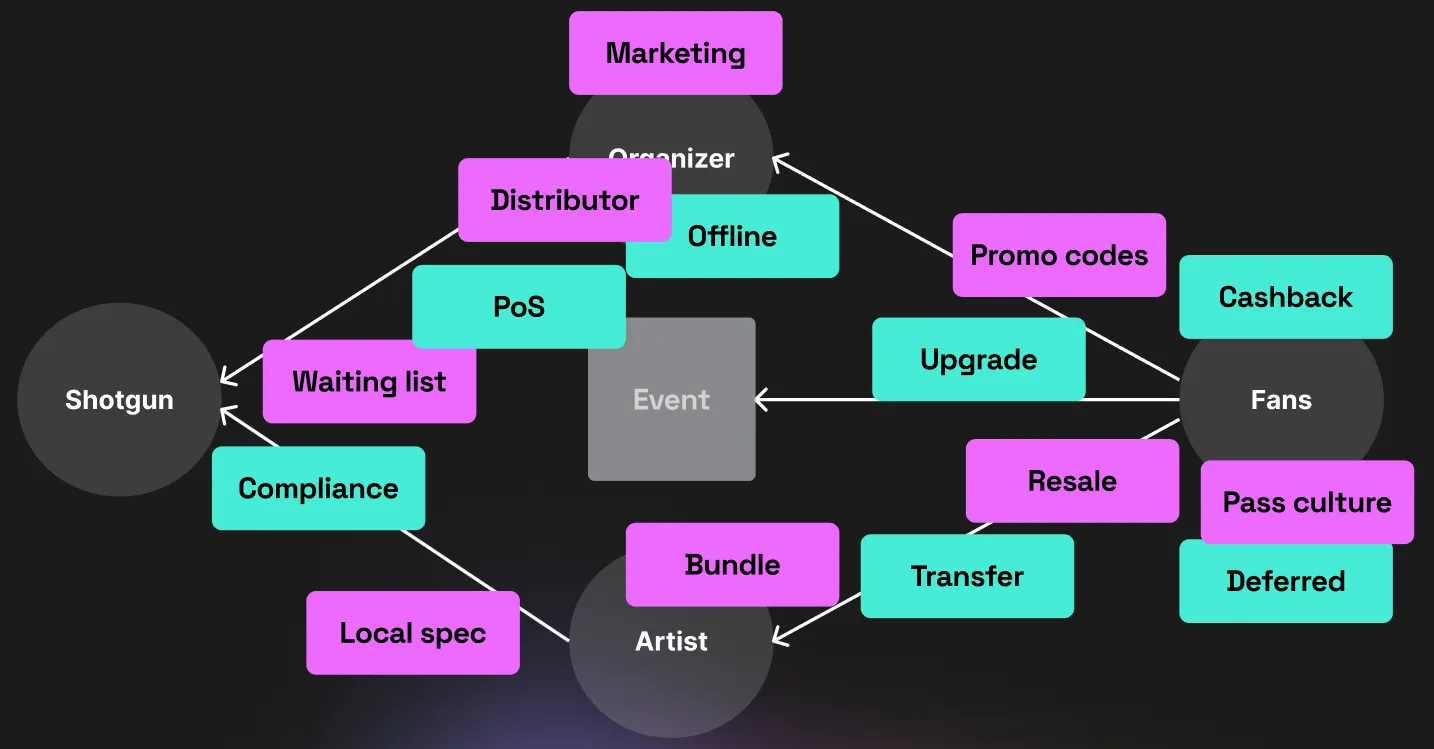
Il met en scène trois 3 cas différents, en expliquant pour chacun la solution mise en place.
- Un client facturé deux fois pour la même commande :
Ajouter l’identifiant de commande comme clé d’idempotence lors de l’appel à la création des paiements pour garantir qu’une même commande ne créera pas plusieurs paiements. - Un remboursement validé, mais l’argent n’est jamais reçu :
Ne pas appeler simultanément l’annulation de commande et le remboursement au cas ou l’un échouerai. Utiliser un webhooks pour déclencher l’annulation de commande uniquement lorsque le remboursement est confirmé. - Un billet non reçu pour le paiement a été débité :
Grouper les actions liées à une commande dans une transaction, capable de rollback l’ensemble en cas d’erreur. Si l’envoi du billet échoue, la commande entière échouera.
Et la conclusion tiens donc en trois points essentiels à garantir lors de la mise en oeuvre d’un système :
- Idempotence: Garantir qu’une même opération répétée plusieurs fois avec les mêmes paramètres aura toujours le même résultat.
- Synchronisation par webhooks : Utiliser les webhooks pour synchroniser les états entre les différents systèmes impliqués dans le processus de paiement.
- Assurer la consistance des données : Mettre en place des mécanismes pour vérifier et maintenir la cohérence des données entre les différents systèmes.
Pour finir, une chose majeure à mettre en place pour garantir la fiabilité d’un système, c’est un suivi efficace de son fonctionnement. Définir des attentes, les mesurer par des indicateurs précis, les contrôler, et améliorer le système en fonction des résultats. Puis itérer sur ces étapes à période régulière.
Toutes ces notions de fiabilité des échanges nous concernent nécessairement chez Marmelab, car nous développons régulièrement des systèmes distribués “from scratch” pour nos clients, ou le choix de l’architecture initiale est notre entière responsabilité. Ces principes d’idempotence, de synchronisation par webhooks ou de consistance des données font partie de nos pratiques courantes et nous validons largement les implémentations proposées par notre orateur. Il sera intéressant de voir si nous pouvons nous inspirer de l’approche proposée par Kevin concernant la mesure itérative des indicateurs de fiabilité pour améliorer encore la qualité de nos prestations et la satisfaction de nos clients.

Le support de cette conférence est disponible ici : Kevin talks
YouTube might track you and we would rather have your consent before loading this video.
Façonner les architectures du futur avec Dapr
Christophe Gigax de chez Hager nous a présenté Dapr, une plateforme open-source qui facilite le développement d’applications distribuées en fournissant des abstractions pour les composants courants tels que la gestion des états, la messagerie, les triggers, etc.

L’outil est assez impressionnant. Il fonctionne en parallèle de vos applications, en “sidecar” et va servir d’intermédiaire pour prendre en charge toutes les interactions externes entre vos services. Ce faisant, il intègre un mécanisme très utile de traces distribué qui permet de suivre facilement un problème à travers l’ensemble du système global, sans avoir à compiler manuellement les logs de chaque service individuel. Ou encore un système de partage des secrets centralisé.
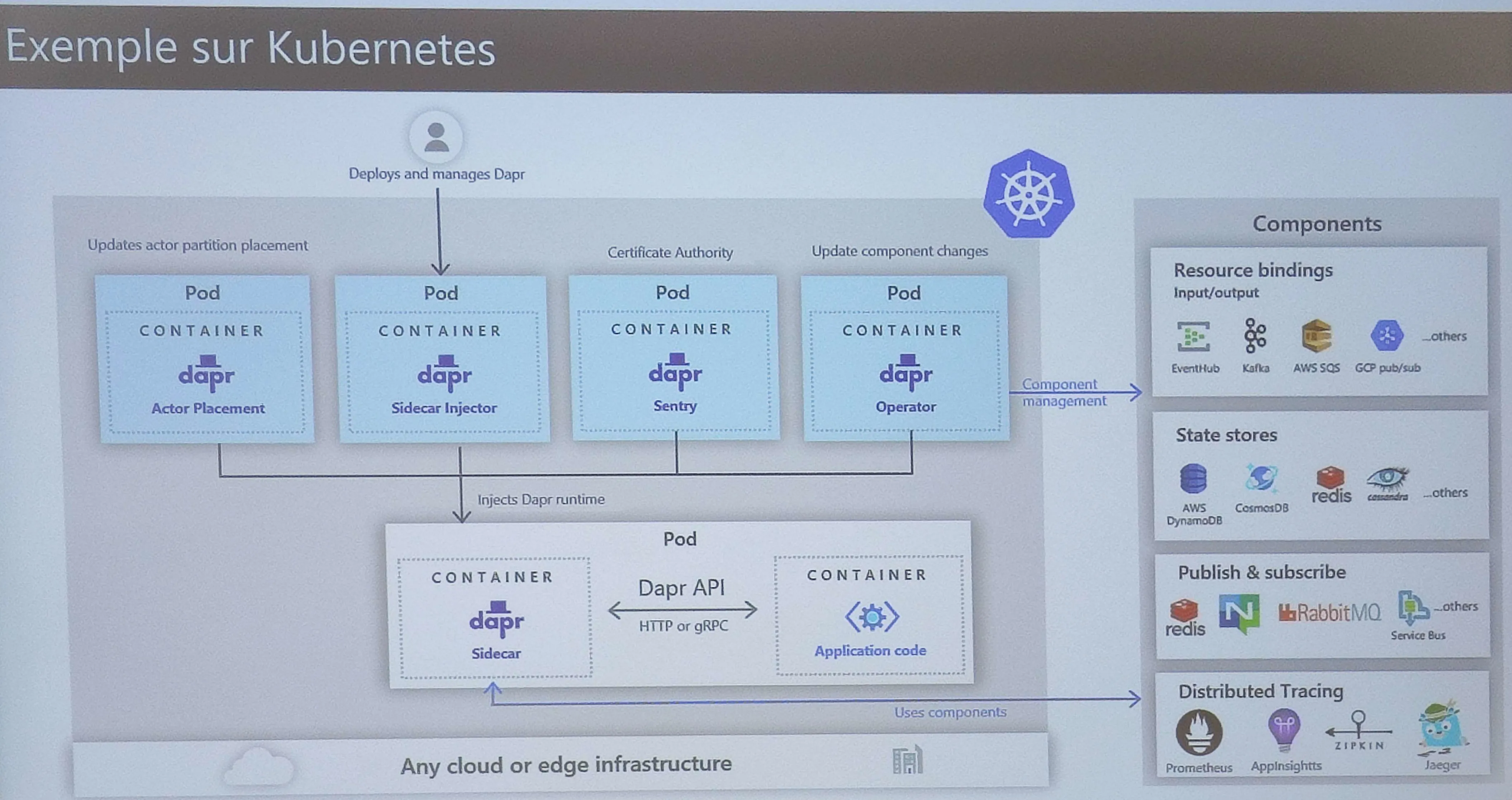
Un autre des avantages mis en avant par Christophe est la facilité avec laquelle une des briques du système peut être remplacée par une autre. Par exemple, si vous utilisiez une base de données PostGreSQL, puis vous changez vers une autre sur MySQL, alors la connection à juste besoin d’être mise à jour une fois dans Dapr sans avoir besoin de redéployer et synchroniser laborieusement chaque service concerné. Cela fonctionne pour n’importe quel élément du système, ou même dans l’autre sans s’il fallait revert MySQL vers POStGreSQL en urgence (sûrement le cas le plus utile :D ).
Une question pertinente soulevée concernait la latence induite par la mise en place d’un acteur intermédiaire au milieu de chaque appel.

Réponse : à priori, très faible, entre 2 et 5 millisecondes. A chacun de voir si le jeu en vaut la chandelle.
Il est difficile d’affirmer qu’un tel outil est adapté aux projets de Marmelab aujourd’hui. C’est probablement un over-engineering pour la plupart des cas que nous rencontrons, mais l’approche est intéressante et mérite d’être suivie de près.
YouTube might track you and we would rather have your consent before loading this video.
Une petite déception (bien qu’annoncée)
L’absence de Marcy Ericka Charollois (remplacée par Danielle Kayumbi avec un talk sur Open telemetry) nous a chagriné car sa conférence sobrement intitulée : “Techno-Autoritarisme et design persuasif : quels risques pour nos libertés ?” s’annonçait vraiment des plus passionnantes.
Bien sur Open telemetry reste un sujet intéressant mais il n’avait pas ce petit coté engageant promis à l’origine. Vous pouvez par ailleurs retrouver ici notre excellent article qui traite également du fonctionnement d’Open telemetry : opentelemetry-in-practice

On espère de tout cœur qu’on pourra retrouver Marcy Ericka Charollois et son talk à une autre occasion.
Conclusion
La conférence Tech F’Est a été une belle occasion de découvrir des sujets passionnants et de rencontrer des experts de la région.
Les talks présentés ont permis d’explorer les dernières avancées en matière de technologie et d’innovation, tout en mettant en avant l’expertise locale.
Un grand merci aux organisateurs pour cette belle initiative.
On a déjà hâte de découvrir ce que nous réserve la prochaine édition.
Espérons que la Tech F’Est continue à grandir et à rassembler les passionné·e·s de tech de la région.
On vous laisse avec l’aftermovie de la conférence, qui vous donnera un aperçu de l’ambiance et des échanges qui ont eu lieu lors de cette première édition.
YouTube might track you and we would rather have your consent before loading this video.
Authors
Full-stack web developer at marmelab, Guillaume was initially a Java guy. Fan of anime and video games, he can develop an AI that beats you every time.
Full-stack web developer at marmelab, Julien follows a customer-centric approach and likes to dig deep into hard problems. He also plugs Legos to computers. He doesn't know who is Irene...