
Creating an MCP Server from OpenAPI Documentation

AI agents are changing how we build software. The Model Context Protocol (MCP) lets these agents communicate with external services in a structured way. I wanted to see if I could create an MCP server from an OpenAPI specification and let agents interact with any REST API automatically.
Our open-source CRM Atomic CRM already has a working MCP server (see Atomic MCP documentation), but I wanted to see if I could recreate another one based on the REST API alone, and how agents could interact with it.
Here is a quick preview of an agent interaction powered by the MCP server I built:
Setting Up Atomic CRM
Atomic CRM is an open-source CRM with OpenAPI documentation. I cloned the repository and ran the setup commands:
git clone git@github.com:marmelab/atomic-crm.gitcd atomic-crmmake install start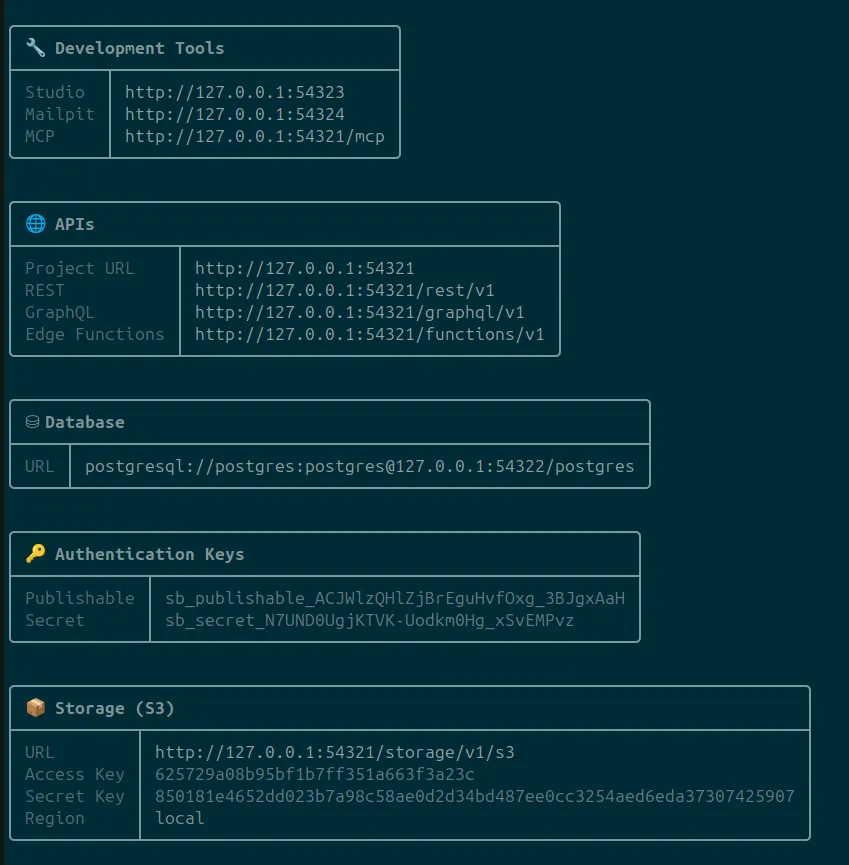
Note: Supabase (which powers Atomic CRM) also provides an MCP server to explore the database and execute SQL queries (see the Supabase MCP documentation). But since I wanted to work with the REST API, I built my own MCP server.
Creating a First MCP Server with FastMCP
I used FastMCP to create an MCP server from a REST API. It’s a Python library that can generate an MCP server from an OpenAPI specification.
First, I created a server.py file:
import httpxfrom fastmcp import FastMCP
# Create an HTTP client for your APIclient = httpx.AsyncClient(base_url="http://localhost:54321/rest/v1")
# Load your OpenAPI specopenapi_spec = httpx.get("http://localhost:54321/rest/v1/").json()
# Create the MCP servermcp = FastMCP.from_openapi( openapi_spec=openapi_spec, client=client, name="My API Server",)
if __name__ == "__main__": # Run the MCP server, in http mode mcp.run('streamable-http')I started the server with:
python server.pyAnd got this error:

FastMCP supports OpenAPI v3+, but Supabase uses OpenAPI v2. This is because Supabase runs on PostgREST, which doesn’t support OpenAPI v3 yet (open issue on GitHub).
As a workaround, I used Swagger Editor to convert the OpenAPI v2 specification to v3.
With the converted OpenAPI v3 specification, the server started without issues:
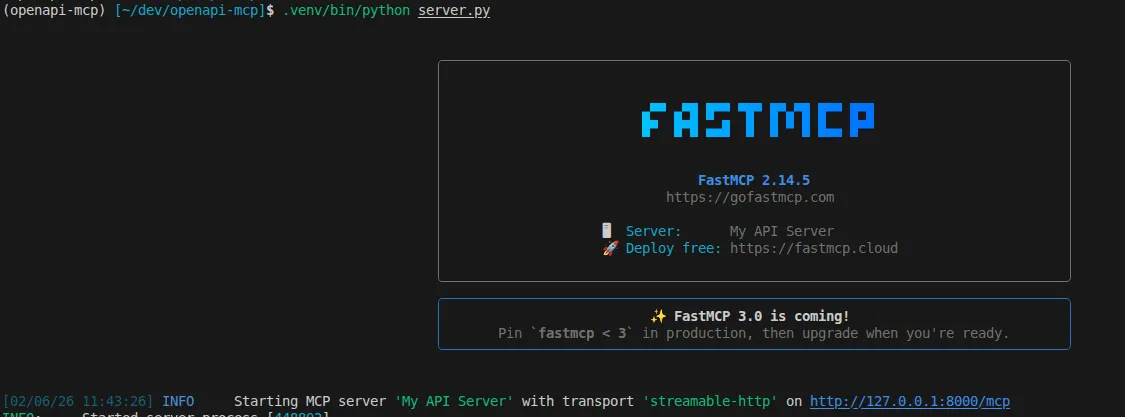
Exploring the MCP Server with the Inspector
MCP servers expose two types of content:
- Resources: Read-only data sources that provide information
- Tools: Functions that the LLM can actively call
I explored what my MCP server provides using @modelcontextprotocol/inspector:
npx @modelcontextprotocol/inspector http://localhost:8000/mcp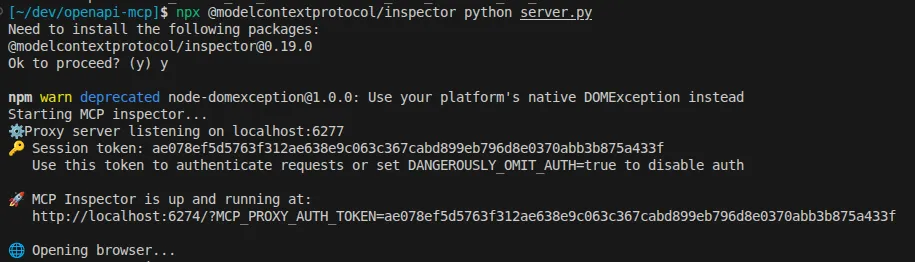
The inspector shows all available tools for interacting with the API:
Connecting the MCP Server to Copilot
I added the MCP server to GitHub Copilot so I could interact with it through natural language:

I named it “atomic-mcp”. Now I could ask questions like “#atomic-mcp What are the companies in the CRM?” and Copilot used the MCP server tools to answer:
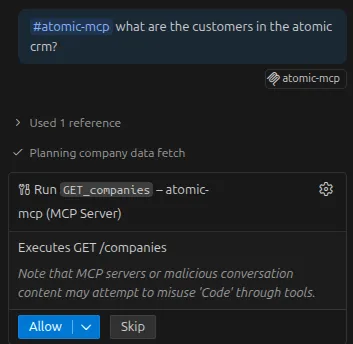
At first, the MCP server returned no companies.
The problem was that the REST API requires an authentication token. Without it, requests are anonymous and return nothing.
I retrieved the service token from the Supabase dashboard at http://127.0.0.1:54323/project/default/:
I added the token to my environment variables as SERVICE_API_TOKEN and updated the code:
# Get API token from environment api_token = os.getenv("SERVICE_API_TOKEN", "")
# Create an HTTP client for your API with authentication headersclient = httpx.AsyncClient( base_url="http://localhost:54321/rest/v1/", headers={ "apikey": api_token, "Authorization": f"Bearer {api_token}" })With authentication in place, the MCP server could now access the CRM data properly.
Adding Custom Discovery Tools
I had some trouble using the MCP server because of how resources work. I followed the FastMCP documentation and configured GET endpoints as resources:
route_maps=[ RouteMap( mcp_type=MCPType.RESOURCE, methods=["GET"], tags=["resources"] ) ]I expected the agent to use these resources to list companies. But the agent kept trying to use tools instead of resources, which led to errors like this:
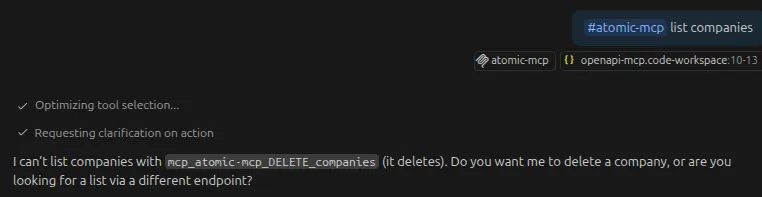
Resources are meant to be passive data sources, while tools are active functions that the agent can call. To use a resource, I had to explicitly add it to the context, which was not ideal for an autonomous agent.
I wanted my agent to discover resources on its own, so I added two custom tools: list_api_resources lists all available GET endpoints with their URIs and descriptions, and read_api_resource lets the agent fetch any of them by URI.
@mcp.toolasync def list_api_resources() -> list[dict]: """ List all available API resources with their URIs and descriptions. Call this tool to discover what data is accessible before reading it. Returns a list of resources with their URI, name, and description. """ base_url = client.base_url.rstrip("/") resources = [] for path, path_item in openapi_spec.get("paths", {}).items(): if "get" in path_item: get_op = path_item["get"] uri = f"{base_url}{path}" parameters = [ p["name"] for p in get_op.get("parameters", []) if p.get("in") == "query" ] resources.append({ "uri": uri, "name": get_op.get("summary") or path, "description": get_op.get("description") or get_op.get("summary") or "", "filter_parameters": parameters, }) return resources
@mcp.toolasync def read_api_resource(uri: str) -> str: """ Read the content of an API resource by its URI. Use list_api_resources first to discover available resource URIs. You can append query parameters to filter results (e.g. http://localhost:54321/rest/v1/contacts?id=eq.42).
Args: uri: The full URI of the resource to read, with optional query parameters. """ response = await client.get(uri) response.raise_for_status() return response.textThe agent could now discover and interact with the API without having every endpoint exposed as a separate tool.
With that in place, I could query the CRM more fluently:
❯ For each deals add me a tasks to plan a call before end of the month.
◐ Let me first get all the deals and then create tasks for each one.
● read_api_resource └ {"result":"[{\"id\":2,\"name\":\"CloudNine - Migration Services\",\"sales_id\...
◐ Now I'll create a task for each deal to plan a call before end of the month (February 2026, so due date is 2026-02-28).
◐ The Ghostbusters Deal has no contact_ids (null), so I can't create a task for it without a contact_id. Let me skip it or let the user know.
All other 6 tasks were created successfully. The Ghostbusters Deal has no contacts associated so the task couldn't be created.
● Created 6 call tasks due by Feb 28 for all deals with contacts:
┌─────────────────────────────────────────┬─────────────────────────┐ │ Deal │ Status │ ├─────────────────────────────────────────┼─────────────────────────┤ │ TechVision AI - Enterprise License Deal │ ✅ │ ├─────────────────────────────────────────┼─────────────────────────┤ │ CloudNine - Migration Services │ ✅ │ ├─────────────────────────────────────────┼─────────────────────────┤ │ Digital Marketing Pro - Q1 Campaign │ ✅ │ ├─────────────────────────────────────────┼─────────────────────────┤ │ Double Fine - Custom Engine Work │ ✅ │ ├─────────────────────────────────────────┼─────────────────────────┤ │ SecureNet - Security Services │ ✅ │ ├─────────────────────────────────────────┼─────────────────────────┤ │ Nouveau deal │ ✅ │ ├─────────────────────────────────────────┼─────────────────────────┤ │ Ghostbusters Deal │ ❌ No contacts assigned │ └─────────────────────────────────────────┴─────────────────────────┘
The Ghostbusters Deal task couldn't be created because it has no contacts. You'll need to assign a contact to that deal first.Limitations: Context Size and Token Consumption
OpenAPI specs usually contain a lot of routes, and each of these routes becomes a separate tool in the MCP server. This is the case here: Atomic CRM has 13 tables and 6 stored procedures, so the generated MCP server results in dozens of tools.
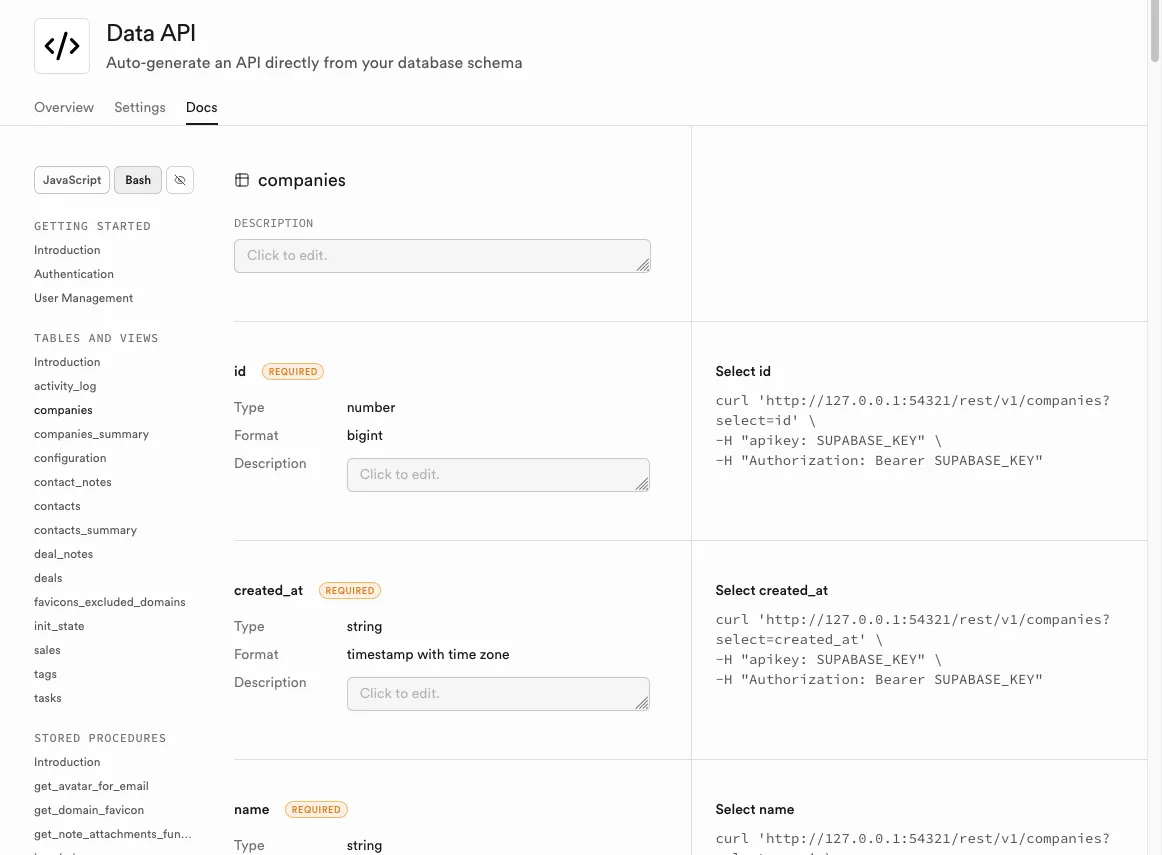
A direct consequence is high token consumption, as the agent has to include all these tools and their descriptions in the context. This also makes it harder for the agent to choose the right tool, as there are so many options available. Finally, it leaves less room for the agent to reason about the task at hand.
REST APIs are resource-oriented, so simple tasks may require long chains of API calls. This means the agent will have to call multiple tools in sequence to achieve a goal, with each one slow and error-prone. Besides, REST responses return many fields the agent doesn’t need.
In my case, while exploring the MCP server, I saw my token consumption skyrocket as the agent made multiple API calls each time it accessed data. I mitigated this by adding the list_api_resources and read_api_resource tools, which let the agent discover and read resources more efficiently. But it still required careful prompt engineering to guide the agent toward using these tools.
Conclusion: Only Useful for Prototyping
Generating an MCP server from an OpenAPI spec is fast and tempting. It allows you to create a working prototype very quickly. But the trade-offs are real, so I wouldn’t recommend this approach for production use.
A better approach is to build feature-oriented tools that wrap multiple API calls. This kind of design is covered in a previous post: Arazzo: a Documentation Helper for Generating Client Code Using AI.
Another approach is to expose the API as a single tool that transmits queries in a structured format (e.g. PostgREST queries or SQL queries) and returns only the relevant data. This is the approach taken by the real Atomic CRM MCP Server, which exposes only 3 tools (get_schema, query, and mutation) for the entire API.
These alternative approaches take more time to build, but they give the agent a much better experience and cut token consumption significantly. They also allow you to design the interface in a way that guides the agent toward the right usage patterns, which is crucial for autonomous agents.
The complete code for this tutorial is available on GitHub at marmelab/mcp-openapi-experiment.
Authors
Full-stack web developer at marmelab, Guillaume can turn complex business logic into an elegant and maintainable program. He brews his own beer, too.