
SnowCamp 2024 : Les talks à ne pas manquer

Malgré la raréfaction de la neige, le fameux événement tech Grenoblois est plus fort que jamais : le SnowCamp !
Vous êtes au bon endroit si vous avez raté l’événement mais souhaitez en apprendre un peu plus sur l’édition 2024 et découvrir quelques-uns des 70 talks qui ont été donnés !
Le SnowCamp
Lancé en 2016 par l’Alpes JUG (décidément les javaistes sont partout), tout l’événement est géré uniquement par des bénévoles, merci à eux !
Cette 8ème édition accueillait plus de 600 personnes, 72 speakers et proposait un format plutôt atypique, sur 4 jours :
- une journée d’université pour participer à 2 formations de 3 heures chacune.
- 2 jours composés de talks de 45 minutes et de lightnings de 20 minutes (enfin plutôt des
tout shousspour rester dans le thème). - une dernière journée sur les pistes (pour faire de la raquette, car pas assez de neige).
Un autre aspect que je trouve chouette, les organisateurs proposaient un “tremplin” : un accompagnement en coaching de plusieurs “primo-speakeurs” pour les épauler dans la fabrication de leur première conf !
La compression Web : comment (re)prendre le contrôle ?
YouTube might track you and we would rather have your consent before loading this video.
En Keynote on a eu le droit à un super talk d’Antoine Caron et Hubert Sablonniere sur la compression de données, principalement textuelles, et ce que ça apporte au web. Le talk était franchement bien ficelé, avec tout plein de parallèles bien pensés avec le Scrabble.
L’histoire commence avec l’indispensable algorithme de compression sans perte, le codage de Huffman inventé en 1952 (ça date) par David Albert Huffman à l’âge de 27 ans (le boss). Elle s’est poursuivie ensuite avec l’apparition des algorithmes de compression par dictionnaire dans la fin des années 1970, dont les plus connus sont LZ77 et LZ78.
Finalement, l’ensemble des formats de compression modernes (gzip, zopfli, brotli, ..) sont basés sur des combinaisons modifiées de ces 2 types de compressions. Du coup ça fait 70 ans que la base du domaine a été posée, mais ce qui chagrine les 2 auteurs c’est que 1/4 des sites ne compressent toujours pas leurs assets d’après le rapport du Web Almanac 2022.
Pourtant ils nous rappellent que c’est facile à mettre en place car parfaitement géré par les serveurs et les navigateurs, que ça permet d’augmenter drastiquement la réactivité d’un site (qui peut réduire le temps de chargement de 5 secondes à 500 millisecondes sur une page Wikipédia en 3G, imaginez !) et aussi de décharger les infrastructures réseau. Pour obtenir le maximum de bénéfices il faut minifier nos fichiers avant de les compresser.
Si vous avez des doutes pour choisir un format ou pour le configurer, les auteurs recommandent le site almanac.httparchive.org. Et pour ma part je vous recommande de voir cette conf pour profiter pleinement des démos interactives !
Practical introduction to OpenTelemetry tracing
J’ai assisté à cet excellent talk de Nicolas Fränkel qui nous a présenté OpenTelemetry.
OpenTelemetry c’est à la fois une norme et un ensemble d’outils ouverts qui standardise la collecte et l’export de 3 types d’informations clés:
- logs
- métriques
- traces
Le gros avantage de OpenTelemetry étant que l’instrumentation des applications est découplée de la plateforme de monitoring sous-jacente (NewRelic, Graphana, Datadog,..), on peut donc en changer plus facilement.
Le coeur de cette conférence selon moi c’était surtout sa démo vraiment bien ficelée, dans laquelle Nicolas a branché OpenTelemetry (avec très peu de modifications du code source) dans une architecture micro-services et qui permettait d’analyser le parcours d’une action utilisateur à travers toutes les couches (base de données et messagerie asynchrone incluent).
Forcément il y a plein de sujets à creuser qui n’avaient pas le temps d’être traités, comme la compatibilité des plateformes de monitoring avec OpenTelemetry ou la configuration de la collecte de données ne pas faire exploser sa facture (comme la mise en place de règles pour échantillonner).
Pour les plus curieux, le repository de la démo est accessible ici, et pour en apprendre plus sur OpenTelemetry vous pouvez lire l’article Demystifying Monitoring: From Basics to OpenTelemetry écrit par Cindy sur notre blog.
Vous pouvez venir à ce talk les yeux fermés
J’ai découvert durant cette présentation, la navigation sur différents sites web via un lecteur d’écran tout gardant les yeux fermés (c’était pas obligé hein, mais j’ai joué le jeu) et l’expérience était traumatisante (vraiment!).
L’auteur nous rappelait que 1.7 millions de personnes sont concernées par un handicap visuel rien qu’en France, dont 80% utilise le web. Le bilan est assez alarmant:
- 10% des sites sont réellement adaptés
- sur les 250 démarches les plus courantes des Français, seulement 6 respectaient complètement le RGAA en 2023.
Mais en réalité ces problèmes d’accessibilités concernent encore plus de monde, car les lecteurs d’écrans sont aussi utilisés par des personnes atteintes de troubles cognitifs ou concernées par l’analphabétisme ou la dyslexie.
À partir de ces constats, François-Xavier Lair nous proposait quelques règles vraiment triviales mais qui peuvent améliorer grandement la vie de ces usagers (et s’il fallait vous convaincre un peu plus, ça favorisera votre référencement naturel):
- maximiser l’usage des balises sémantiques: “A div is not a button”.
- avoir une hiérarchie de titres cohérente.
- donner des intitulés explicites aux liens.
- ajouter des textes alternatifs pour les images ayant du sens.
- et à l’inverse, minimiser l’impact du contenu purement décoratif (en utilisant aria-hidden pour les emojis, ou en mettant du texte alternatif vide sur certaines images).
- La première règle d’Aria, c’est de ne pas l’utiliser.
Ce que j’en retiens aussi, c’est qu’on peut tester pour de vrai et facilement comment notre site se comporte avec un lecteur d’écran, comme par exemple avec nvda.
Code Case : les méthodes de la crim adaptées au code
L’enquêteur Punkin sous son long chapeau et imperméable, nous a montré comment il a dû par le passé investiguer une codebase en exploitant Git avec l’oeil d’un flic de la Crim’.
Pour cela il s’est appuyé sur une boîte à outils, en partie héritée de la lecture du livre Your Code as a Crime Scene permettant d’analyser l’évolution d’une application grâce aux différents types de visualisations comme :
- Les “hotspots” qui sont les fichiers étant les plus fréquemment modifiés
- L’évolution de la complexité des fichiers (basée sur le nombre de lignes et l’indentation)
- Le couplage entre différents fichiers (la probabilité de devoir modifier un fichier B si je travaille sur le fichier A)
- La distribution des connaissances
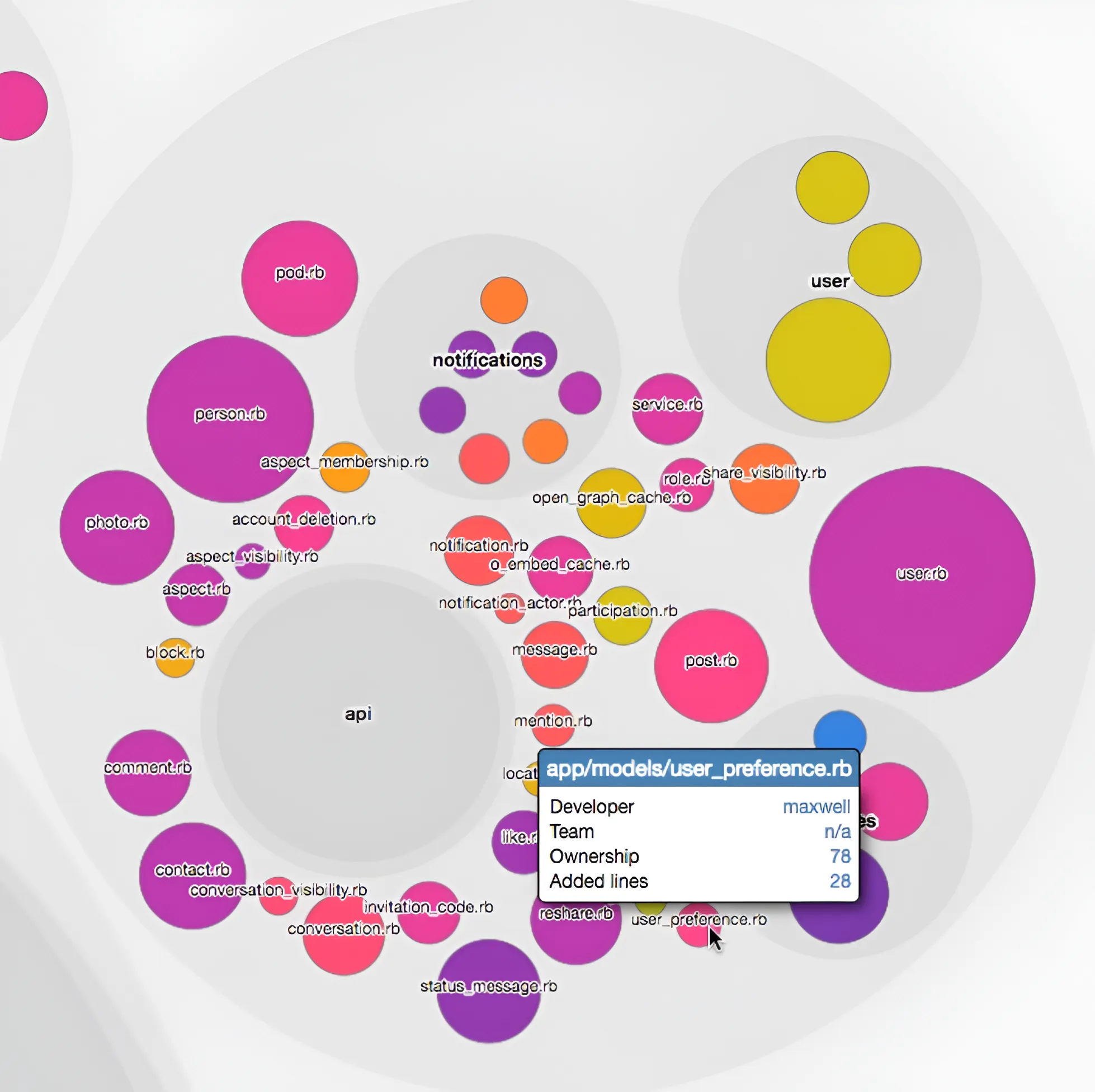 La distribution des connaissances met en évidence qui sont les plus gros contributeurs de chaque fichier
La distribution des connaissances met en évidence qui sont les plus gros contributeurs de chaque fichier
J’ai bien aimé l’idée d’utiliser ces outils d’analyses pour exposer des informations “objectives” sur l’évolution du code, ça peut aider à prendre conscience de certains problèmes architecturaux ou d’organisations (où sont les silos de connaissances, par exemple).
En plus, les visualisations générées par cette approche permettent de mettre en avant certaines problématiques de façon assez didactique à des personnes non-tech.
L’auteur du livre a aussi donné une conférence il y a quelques années, et les outils sont mis à disposition dans ce repository.
Conclusion
Des sujets variés et intéressants, une organisation au poil et tout un tas de gens sympathiques. Il manquait juste l’enregistrement vidéo des conférences à cette édition 2024 pour que ce soit parfait.
Du coup, il ne me reste plus qu’à vous recommander de participer à la 9ème édition !
Authors
Full-stack web developer at marmelab, Arnaud is a Software Engineer with a strong environmental conscience. He brews his own beer, which is a good way to prepare for the future.